 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Optimal Attribute Representations for Conditional GANs
Mar 13, 2020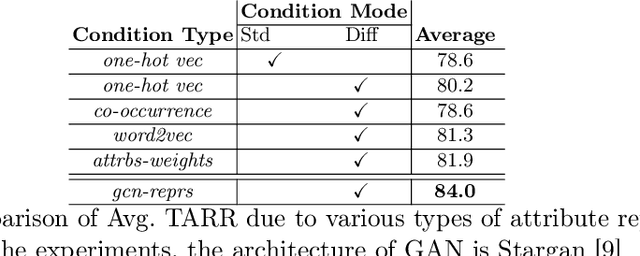

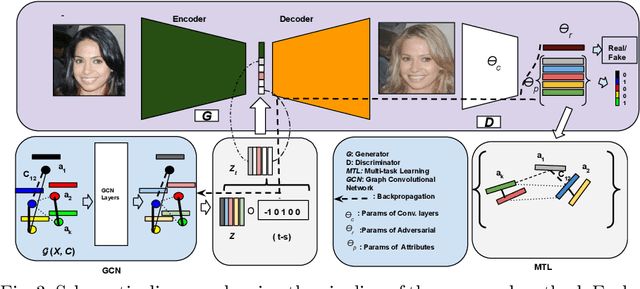
Conditional GANs are widely used in translating an image from one category to another. Meaningful conditions to GANs provide greater flexibility and control over the nature of the target domain synthetic data. Existing conditional GANs commonly encode target domain label information as hard-coded categorical vectors in the form of 0s and 1s. The major drawbacks of such representations are inability to encode the high-order semantic information of target categories and their relative dependencies. We propose a novel end-to-end learning framework with Graph Convolutional Networks to learn the attribute representations to condition on the generator. The GAN losses, i.e. the discriminator and attribute classification losses, are fed back to the Graph resulting in the synthetic images that are more natural and clearer in attributes. Moreover, prior-arts are given priorities to condition on the generator side, not on the discriminator side of GANs. We apply the conditions to the discriminator side as well via multi-task learning. We enhanced the four state-of-the art cGANs architectures: Stargan, Stargan-JNT, AttGAN and STGAN. Our extensive qualitative and quantitative evaluations on challenging face attributes manipulation data set, CelebA, LFWA, and RaFD, show that the cGANs enhanced by our methods outperform by a large margin, compared to their counter-parts and other conditioning methods, in terms of both target attributes recognition rates and quality measures such as PSNR and SSIM.
A Review on Object Pose Recovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
Jan 28, 2020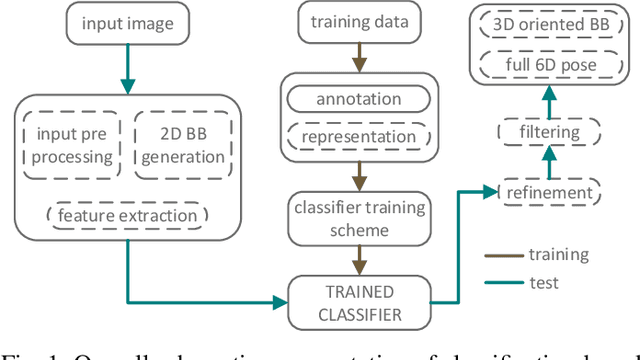
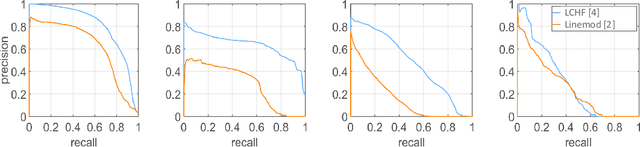
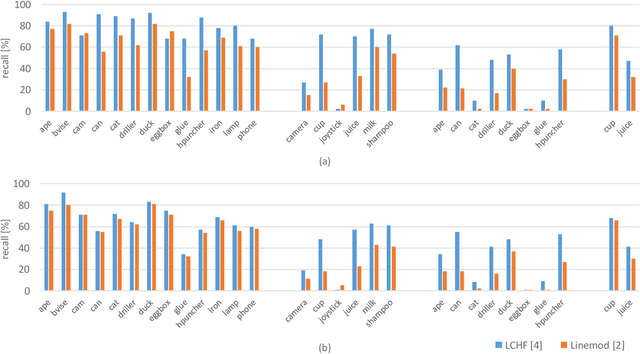
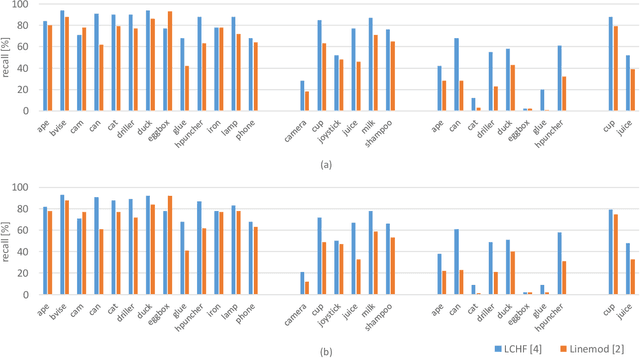
Object pose recovery has gained increasing attention in the computer vision field as it has become an important problem in rapidly evolving technological areas related to autonomous driving, robotics, and augmented reality. Existing review-related studies have addressed the problem at visual level in 2D, going through the methods which produce 2D bounding boxes of objects of interest in RGB images. The 2D search space is enlarged either using the geometry information available in the 3D space along with RGB (Mono/Stereo) images, or utilizing depth data from LIDAR sensors and/or RGB-D cameras. 3D bounding box detectors, producing category-level amodal 3D bounding boxes, are evaluated on gravity aligned images, while full 6D object pose estimators are mostly tested at instance-level on the images where the alignment constraint is removed. Recently, 6D object pose estimation is tackled at the level of categories. In this paper, we present the first comprehensive and most recent review of the methods on object pose recovery, from 3D bounding box detectors to full 6D pose estimators. The methods mathematically model the problem as a classification, regression, classification & regression, template matching, and point-pair feature matching task. Based on this, a mathematical-model-based categorization of the methods is established. Datasets used for evaluating the methods are investigated with respect to the challenges, and evaluation metrics are studied. Quantitative results of experiments in the literature are analysed to show which category of methods best performs across what types of challenges. The analyses are further extended comparing two methods, which are our own implementations, so that the outcomes from the public results are further solidified. Current position of the field is summarized regarding object pose recovery, and possible research directions are identified.
Accurate 6D Object Pose Estimation by Pose Conditioned Mesh Reconstruction
Oct 23, 2019
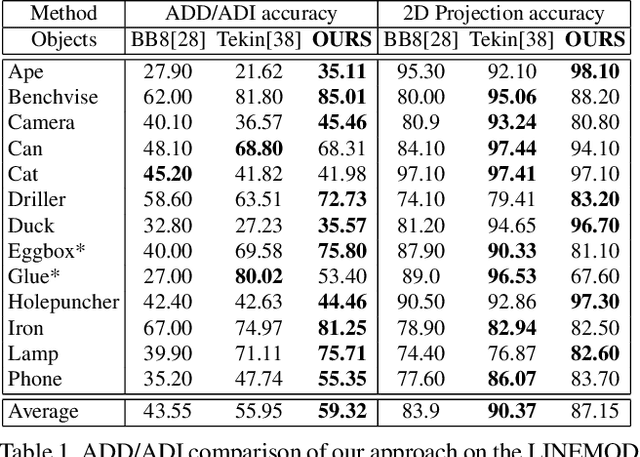
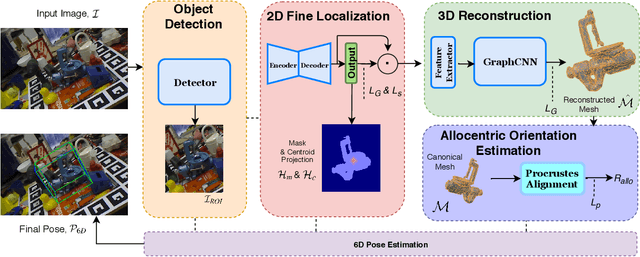
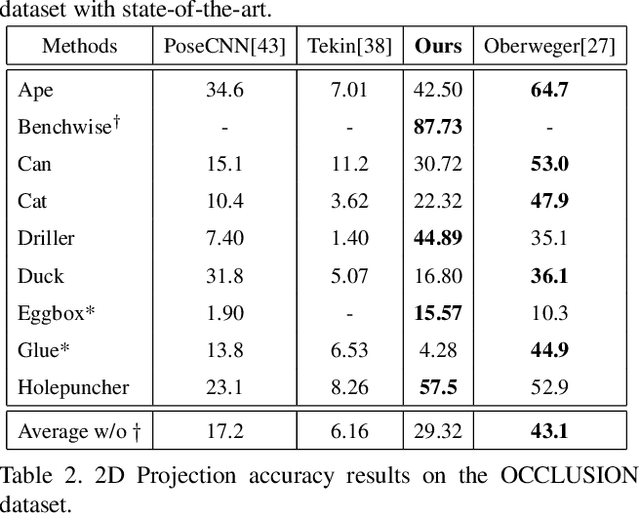
Current 6D object pose methods consist of deep CNN models fully optimized for a single object but with its architecture standardized among objects with different shapes. In contrast to previous works, we explicitly exploit each object's distinct topological information i.e. 3D dense meshes in the pose estimation model, with an automated process and prior to any post-processing refinement stage. In order to achieve this, we propose a learning framework in which a Graph Convolutional Neural Network reconstructs a pose conditioned 3D mesh of the object. A robust estimation of the allocentric orientation is recovered by computing, in a differentiable manner, the Procrustes' alignment between the canonical and reconstructed dense 3D meshes. 6D egocentric pose is then lifted using additional mask and 2D centroid projection estimations. Our method is capable of self validating its pose estimation by measuring the quality of the reconstructed mesh, which is invaluable in real life applications. In our experiments on the LINEMOD, OCCLUSION and YCB-Video benchmarks, the proposed method outperforms state-of-the-arts.
Active 6D Multi-Object Pose Estimation in Cluttered Scenarios with Deep Reinforcement Learning
Oct 19, 2019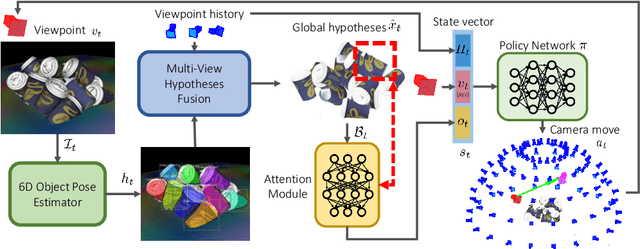
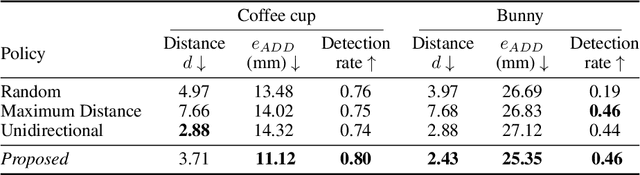
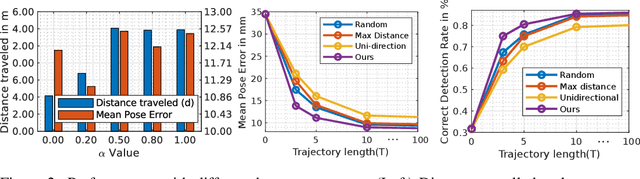
In this work, we explore how a strategic selection of camera movements can facilitate the task of 6D multi-object pose estimation in cluttered scenarios while respecting real-world constraints important in robotics and augmented reality applications, such as time and distance traveled. In the proposed framework, a set of multiple object hypotheses is given to an agent, which is inferred by an object pose estimator and subsequently spatio-temporally selected by a fusion function that makes use of a verification score that circumvents the need of ground-truth annotations. The agent reasons about these hypotheses, directing its attention to the object which it is most uncertain about, moving the camera towards such an object. Unlike previous works that propose short-sighted policies, our agent is trained in simulated scenarios using reinforcement learning, attempting to learn the camera moves that produce the most accurate object poses hypotheses for a given temporal and spatial budget, without the need of viewpoints rendering during inference. Our experiments show that the proposed approach successfully estimates the 6D object pose of a stack of objects in both challenging cluttered synthetic and real scenarios, showing superior performance compared to strong baselines.
Sampling Strategies for GAN Synthetic Data
Sep 10, 2019
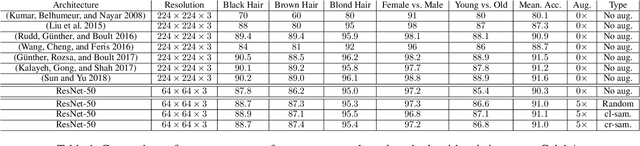
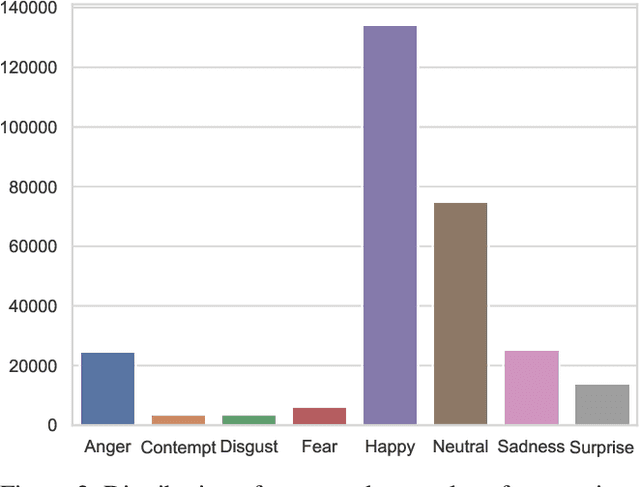
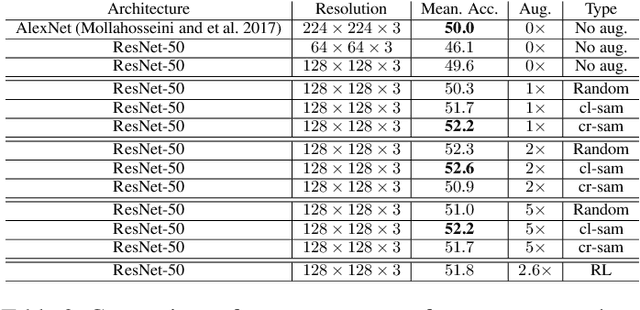
Generative Adversarial Networks (GANs) have been used widely to generate large volumes of synthetic data. This data is being utilized for augmenting with real examples in order to train deep Convolutional Neural Networks (CNNs). Studies have shown that the generated examples lack sufficient realism to train deep CNNs and are poor in diversity. Unlike previous studies of randomly augmenting the synthetic data with real data, we present our simple, effective and easy to implement synthetic data sampling methods to train deep CNNs more efficiently and accurately. To this end, we propose to maximally utilize the parameters learned during training of the GAN itself. These include discriminator's realism confidence score and the confidence on the target label of the synthetic data. In addition to this, we explore reinforcement learning (RL) to automatically search a subset of meaningful synthetic examples from a large pool of GAN synthetic data. We evaluate our method on two challenging face attribute classification data sets viz. AffectNet and CelebA. Our extensive experiments clearly demonstrate the need of sampling synthetic data before augmentation, which also improves the performance of one of the state-of-the-art deep CNNs in vitro.
Real-time Background-aware 3D Textureless Object Pose Estimation
Jul 22, 2019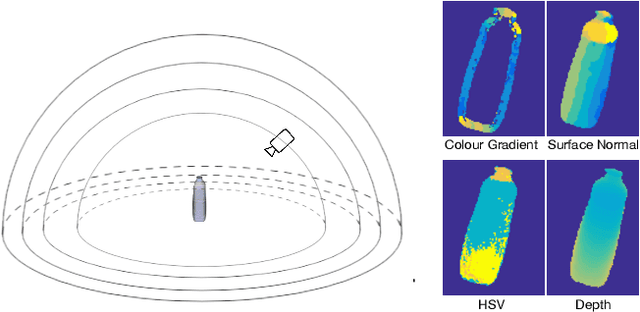
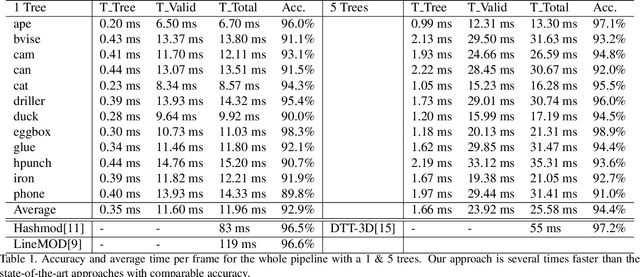
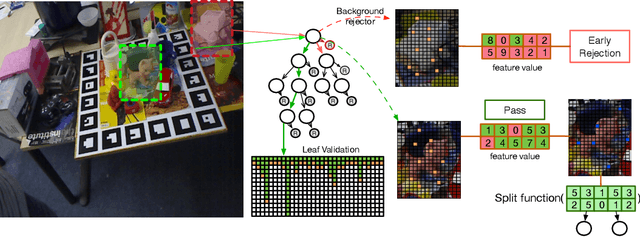
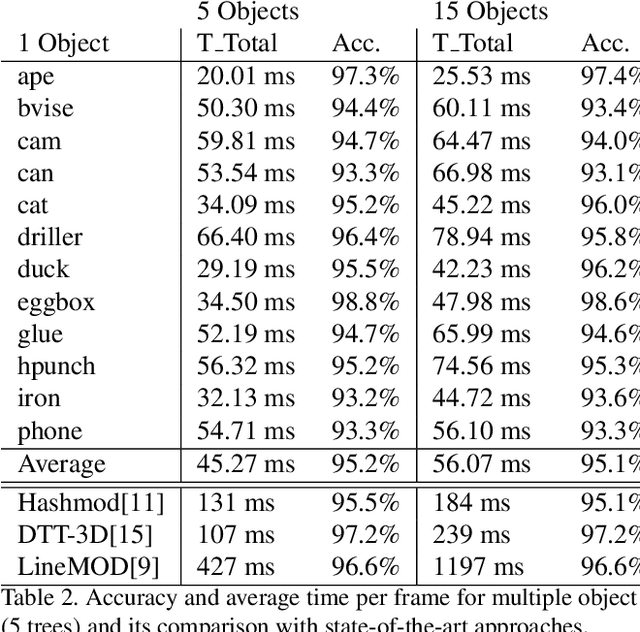
In this work, we present a modified fuzzy decision forest for real-time 3D object pose estimation based on typical template representation. We employ an extra preemptive background rejector node in the decision forest framework to terminate the examination of background locations as early as possible, result in a significantly improvement on efficiency. Our approach is also scalable to large dataset since the tree structure naturally provides a logarithm time complexity to the number of objects. Finally we further reduce the validation stage with a fast breadth-first scheme. The results show that our approach outperform the state-of-the-arts on the efficiency while maintaining a comparable accuracy.
AugLabel: Exploiting Word Representations to Augment Labels for Face Attribute Classification
Jul 15, 2019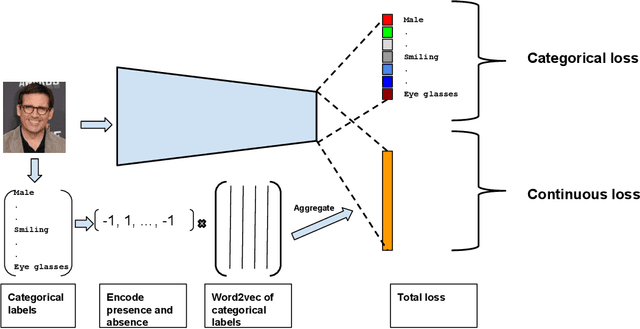
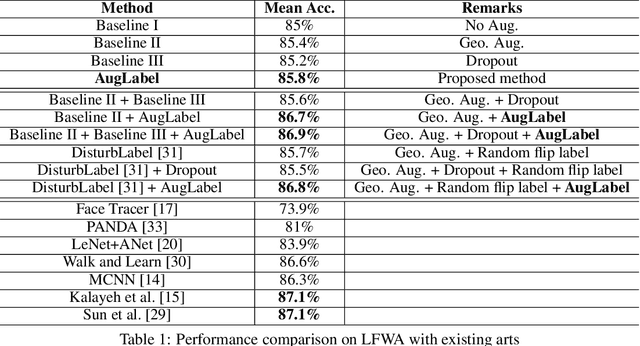
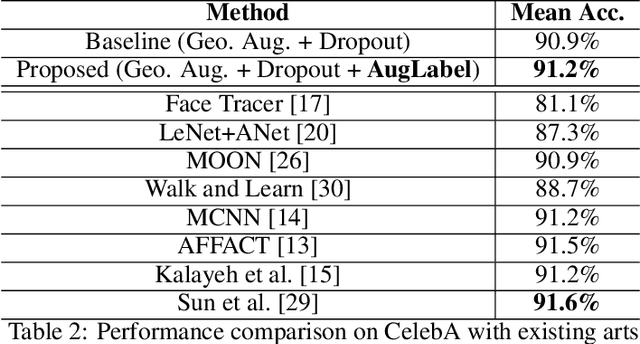
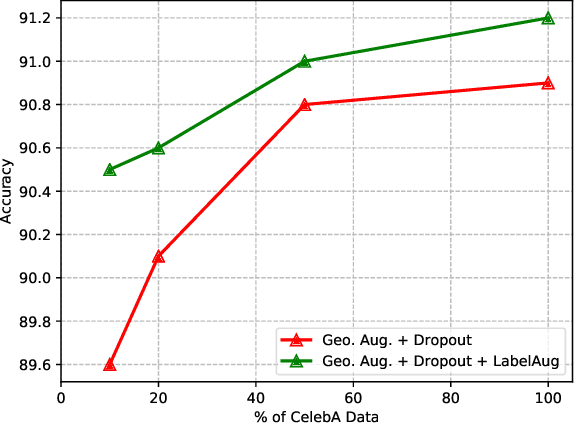
Augmenting data in image space (eg. flipping, cropping etc) and activation space (eg. dropout) are being widely used to regularise deep neural networks and have been successfully applied on several computer vision tasks. Unlike previous works, which are mostly focused on doing augmentation in the aforementioned domains, we propose to do augmentation in label space. In this paper, we present a novel method to generate fixed dimensional labels with continuous values for images by exploiting the word2vec representations of the existing categorical labels. We then append these representations with existing categorical labels and train the model. We validated our idea on two challenging face attribute classification data sets viz. CelebA and LFWA. Our extensive experiments show that the augmented labels improve the performance of the competitive deep learning baseline and reduce the need of annotated real data up to 50%, while attaining a performance similar to the state-of-the-art methods.
Rethink Global Reward Game and Credit Assignment in Multi-agent Reinforcement Learning
Jul 11, 2019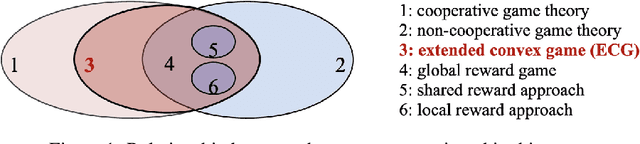



Cooperative game is a critical research area in multi-agent reinforcement learning (MARL). Global reward game is a subclass of cooperative games, where all agents aim to maximize cumulative global rewards. Credit assignment is an important problem studied in the global reward game. Most works stand by the view of non-cooperative-game theoretical framework with the shared reward approach, i.e., each agent is assigned a shared global reward directly. This, however, may give each agent an inaccurate feedback on his contribution to the group. In this paper, we introduce a cooperative-game theoretical framework and extend it to the finite-horizon case. We show that our proposed framework is a superset of the global reward game. Based on this framework, we propose an algorithm called Shapley Q-value policy gradient (SQPG) to learn a local reward approach that can distribute the cumulative global reward fairly, reflecting each agent's own contribution in contrast to the shared reward approach. We evaluate our method on the Cooperative Navigation, Prey-and-Predator and Traffic Junction, compared with MADDPG, COMA, Independent actor-critic and Independent DDPG. In the experiments, our algorithm shows better convergence than the baselines.
Pushing the Envelope for RGB-based Dense 3D Hand Pose Estimation via Neural Rendering
Apr 09, 2019

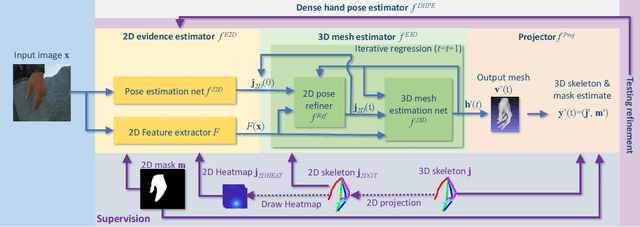

Estimating 3D hand meshes from single RGB images is challenging, due to intrinsic 2D-3D mapping ambiguities and limited training data. We adopt a compact parametric 3D hand model that represents deformable and articulated hand meshes. To achieve the model fitting to RGB images, we investigate and contribute in three ways: 1) Neural rendering: inspired by recent work on human body, our hand mesh estimator (HME) is implemented by a neural network and a differentiable renderer, supervised by 2D segmentation masks and 3D skeletons. HME demonstrates good performance for estimating diverse hand shapes and improves pose estimation accuracies. 2) Iterative testing refinement: Our fitting function is differentiable. We iteratively refine the initial estimate using the gradients, in the spirit of iterative model fitting methods like ICP. The idea is supported by the latest research on human body. 3) Self-data augmentation: collecting sized RGB-mesh (or segmentation mask)-skeleton triplets for training is a big hurdle. Once the model is successfully fitted to input RGB images, its meshes i.e. shapes and articulations, are realistic, and we augment view-points on top of estimated dense hand poses. Experiments using three RGB-based benchmarks show that our framework offers beyond state-of-the-art accuracy in 3D pose estimation, as well as recovers dense 3D hand shapes. Each technical component above meaningfully improves the accuracy in the ablation study.
Instance- and Category-level 6D Object Pose Estimation
Mar 11, 2019
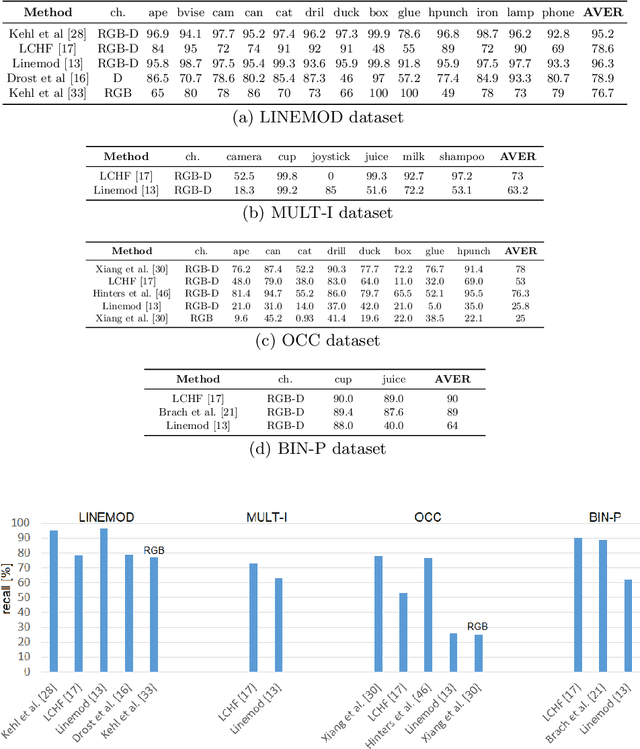

6D object pose estimation is an important task that determines the 3D position and 3D rotation of an object in camera-centred coordinates. By utilizing such a task, one can propose promising solutions for various problems related to scene understanding, augmented reality, control and navigation of robotics. Recent developments on visual depth sensors and low-cost availability of depth data significantly facilitate object pose estimation. Using depth information from RGB-D sensors, substantial progress has been made in the last decade by the methods addressing the challenges such as viewpoint variability, occlusion and clutter, and similar looking distractors. Particularly, with the recent advent of convolutional neural networks, RGB-only based solutions have been presented. However, improved results have only been reported for recovering the pose of known instances, i.e., for the instance-level object pose estimation tasks. More recently, state-of-the-art approaches target to solve object pose estimation problem at the level of categories, recovering the 6D pose of unknown instances. To this end, they address the challenges of the category-level tasks such as distribution shift among source and target domains, high intra-class variations, and shape discrepancies between objects.