 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond neural scaling laws: beating power law scaling via data pruning
Jun 29, 2022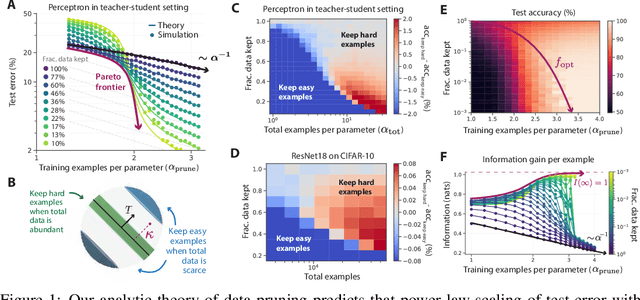

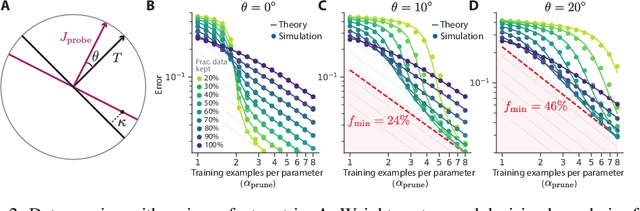
Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, these improvements through scaling alone require considerable costs in compute and energy. Here we focus on the scaling of error with dataset size and show how both in theory and practice we can break beyond power law scaling and reduce it to exponential scaling instead if we have access to a high-quality data pruning metric that ranks the order in which training examples should be discarded to achieve any pruned dataset size. We then test this new exponential scaling prediction with pruned dataset size empirically, and indeed observe better than power law scaling performance on ResNets trained on CIFAR-10, SVHN, and ImageNet. Given the importance of finding high-quality pruning metrics, we perform the first large-scale benchmarking study of ten different data pruning metrics on ImageNet. We find most existing high performing metrics scale poorly to ImageNet, while the best are computationally intensive and require labels for every image. We therefore developed a new simple, cheap and scalable self-supervised pruning metric that demonstrates comparable performance to the best supervised metrics. Overall, our work suggests that the discovery of good data-pruning metrics may provide a viable path forward to substantially improved neural scaling laws, thereby reducing the resource costs of modern deep learning.
Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
Jun 02, 2022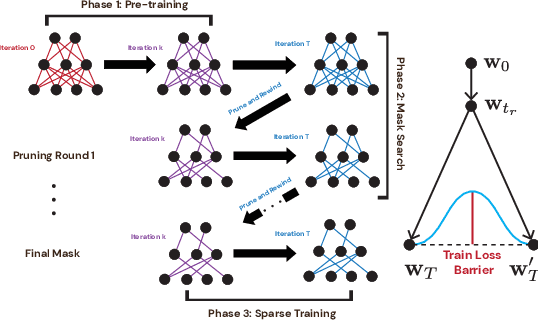
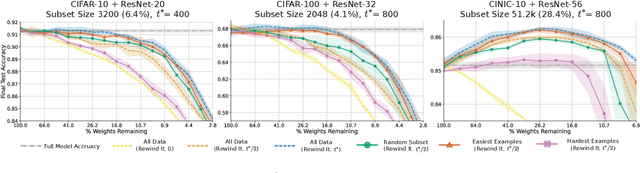

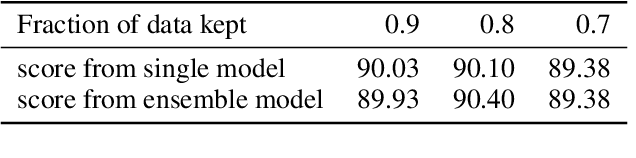
A striking observation about iterative magnitude pruning (IMP; Frankle et al. 2020) is that $\unicode{x2014}$ after just a few hundred steps of dense training $\unicode{x2014}$ the method can find a sparse sub-network that can be trained to the same accuracy as the dense network. However, the same does not hold at step 0, i.e. random initialization. In this work, we seek to understand how this early phase of pre-training leads to a good initialization for IMP both through the lens of the data distribution and the loss landscape geometry. Empirically we observe that, holding the number of pre-training iterations constant, training on a small fraction of (randomly chosen) data suffices to obtain an equally good initialization for IMP. We additionally observe that by pre-training only on "easy" training data, we can decrease the number of steps necessary to find a good initialization for IMP compared to training on the full dataset or a randomly chosen subset. Finally, we identify novel properties of the loss landscape of dense networks that are predictive of IMP performance, showing in particular that more examples being linearly mode connected in the dense network correlates well with good initializations for IMP. Combined, these results provide new insight into the role played by the early phase training in IMP.
MetaMorph: Learning Universal Controllers with Transformers
Mar 22, 2022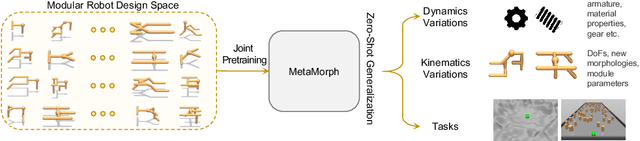
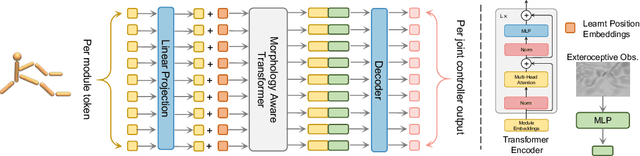
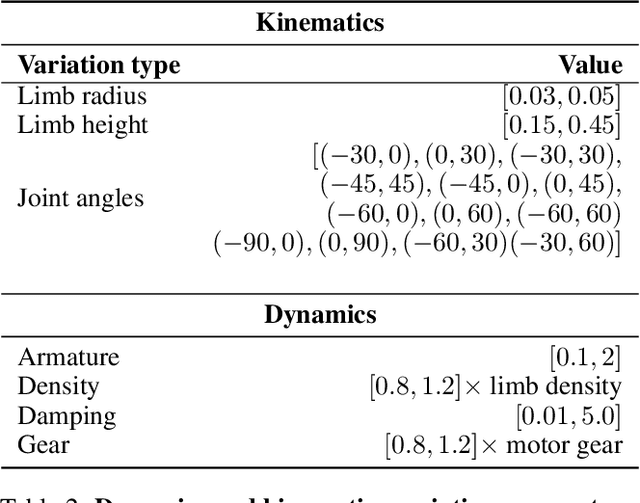
Multiple domains like vision, natural language, and audio are witnessing tremendous progress by leveraging Transformers for large scale pre-training followed by task specific fine tuning. In contrast, in robotics we primarily train a single robot for a single task. However, modular robot systems now allow for the flexible combination of general-purpose building blocks into task optimized morphologies. However, given the exponentially large number of possible robot morphologies, training a controller for each new design is impractical. In this work, we propose MetaMorph, a Transformer based approach to learn a universal controller over a modular robot design space. MetaMorph is based on the insight that robot morphology is just another modality on which we can condition the output of a Transformer. Through extensive experiments we demonstrate that large scale pre-training on a variety of robot morphologies results in policies with combinatorial generalization capabilities, including zero shot generalization to unseen robot morphologies. We further demonstrate that our pre-trained policy can be used for sample-efficient transfer to completely new robot morphologies and tasks.
Rethinking the limiting dynamics of SGD: modified loss, phase space oscillations, and anomalous diffusion
Jul 19, 2021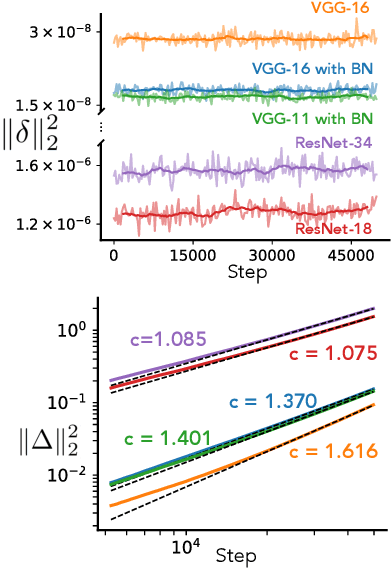
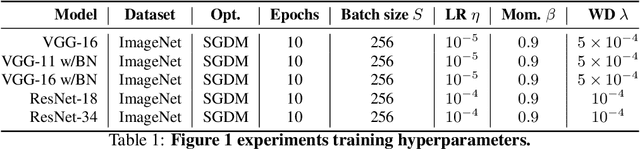
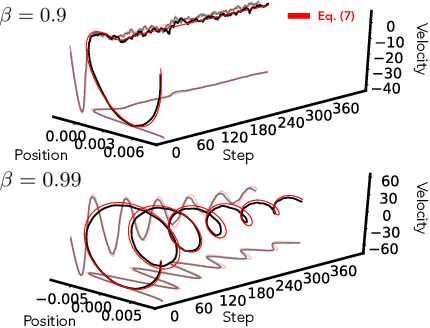

In this work we explore the limiting dynamics of deep neural networks trained with stochastic gradient descent (SGD). We find empirically that long after performance has converged, networks continue to move through parameter space by a process of anomalous diffusion in which distance travelled grows as a power law in the number of gradient updates with a nontrivial exponent. We reveal an intricate interaction between the hyperparameters of optimization, the structure in the gradient noise, and the Hessian matrix at the end of training that explains this anomalous diffusion. To build this understanding, we first derive a continuous-time model for SGD with finite learning rates and batch sizes as an underdamped Langevin equation. We study this equation in the setting of linear regression, where we can derive exact, analytic expressions for the phase space dynamics of the parameters and their instantaneous velocities from initialization to stationarity. Using the Fokker-Planck equation, we show that the key ingredient driving these dynamics is not the original training loss, but rather the combination of a modified loss, which implicitly regularizes the velocity, and probability currents, which cause oscillations in phase space. We identify qualitative and quantitative predictions of this theory in the dynamics of a ResNet-18 model trained on ImageNet. Through the lens of statistical physics, we uncover a mechanistic origin for the anomalous limiting dynamics of deep neural networks trained with SGD.
Deep Learning on a Data Diet: Finding Important Examples Early in Training
Jul 15, 2021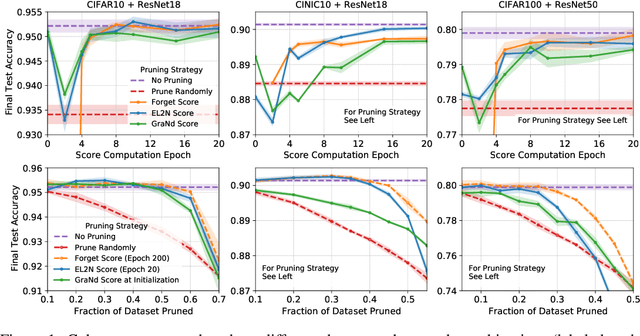
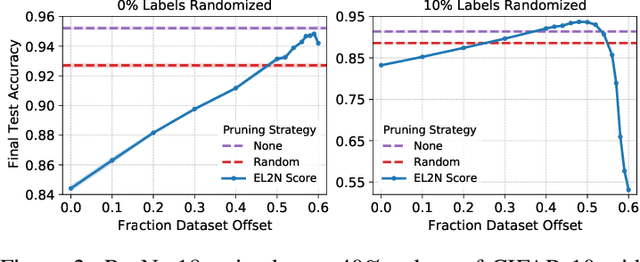
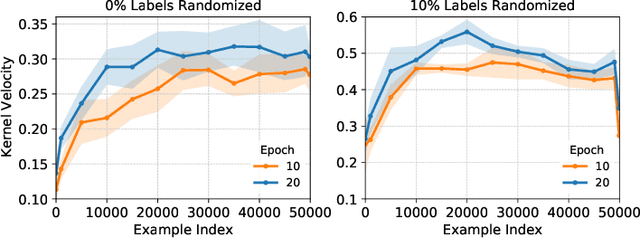
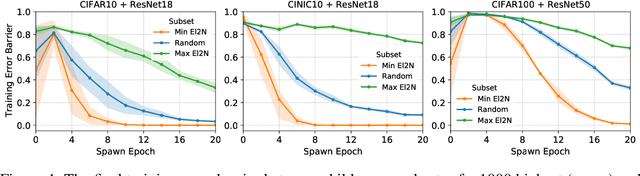
The recent success of deep learning has partially been driven by training increasingly overparametrized networks on ever larger datasets. It is therefore natural to ask: how much of the data is superfluous, which examples are important for generalization, and how do we find them? In this work, we make the striking observation that, on standard vision benchmarks, the initial loss gradient norm of individual training examples, averaged over several weight initializations, can be used to identify a smaller set of training data that is important for generalization. Furthermore, after only a few epochs of training, the information in gradient norms is reflected in the normed error--L2 distance between the predicted probabilities and one hot labels--which can be used to prune a significant fraction of the dataset without sacrificing test accuracy. Based on this, we propose data pruning methods which use only local information early in training, and connect them to recent work that prunes data by discarding examples that are rarely forgotten over the course of training. Our methods also shed light on how the underlying data distribution shapes the training dynamics: they rank examples based on their importance for generalization, detect noisy examples and identify subspaces of the model's data representation that are relatively stable over training.
How many degrees of freedom do we need to train deep networks: a loss landscape perspective
Jul 13, 2021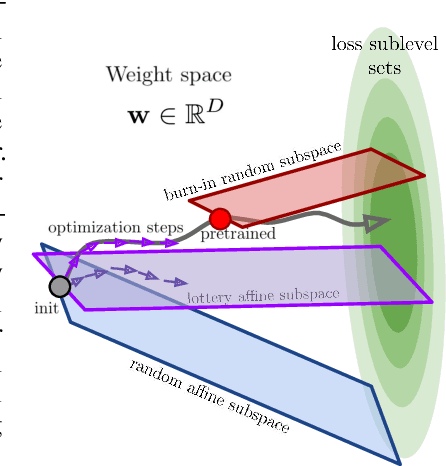
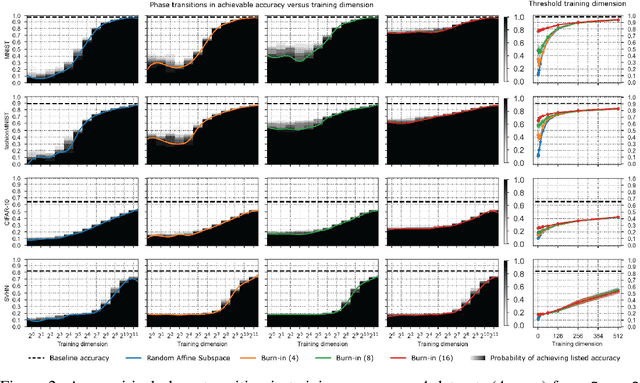
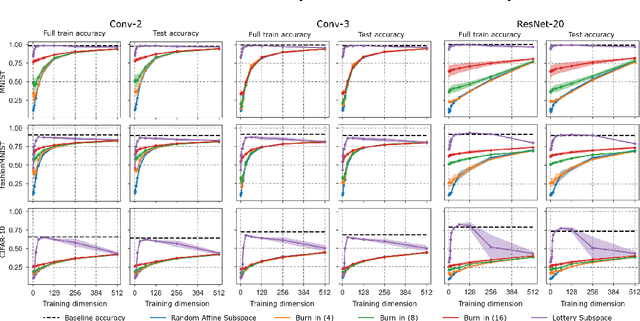
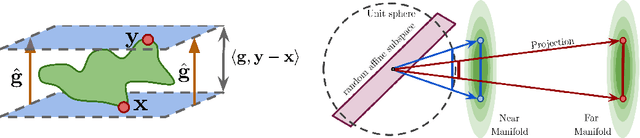
A variety of recent works, spanning pruning, lottery tickets, and training within random subspaces, have shown that deep neural networks can be trained using far fewer degrees of freedom than the total number of parameters. We explain this phenomenon by first examining the success probability of hitting a training loss sub-level set when training within a random subspace of a given training dimensionality. We find a sharp phase transition in the success probability from $0$ to $1$ as the training dimension surpasses a threshold. This threshold training dimension increases as the desired final loss decreases, but decreases as the initial loss decreases. We then theoretically explain the origin of this phase transition, and its dependence on initialization and final desired loss, in terms of precise properties of the high dimensional geometry of the loss landscape. In particular, we show via Gordon's escape theorem, that the training dimension plus the Gaussian width of the desired loss sub-level set, projected onto a unit sphere surrounding the initialization, must exceed the total number of parameters for the success probability to be large. In several architectures and datasets, we measure the threshold training dimension as a function of initialization and demonstrate that it is a small fraction of the total number of parameters, thereby implying, by our theory, that successful training with so few dimensions is possible precisely because the Gaussian width of low loss sub-level sets is very large. Moreover, this threshold training dimension provides a strong null model for assessing the efficacy of more sophisticated ways to reduce training degrees of freedom, including lottery tickets as well a more optimal method we introduce: lottery subspaces.
Understanding self-supervised Learning Dynamics without Contrastive Pairs
Feb 12, 2021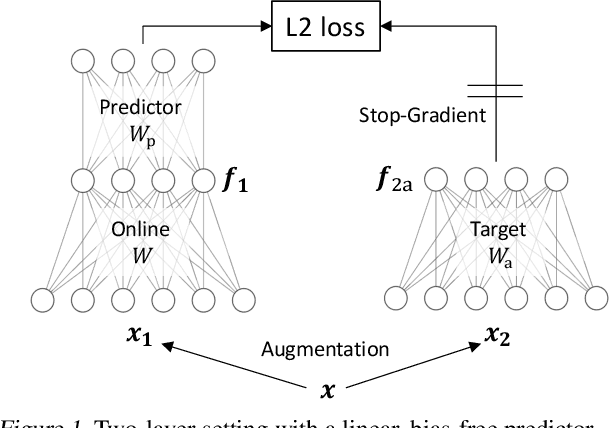
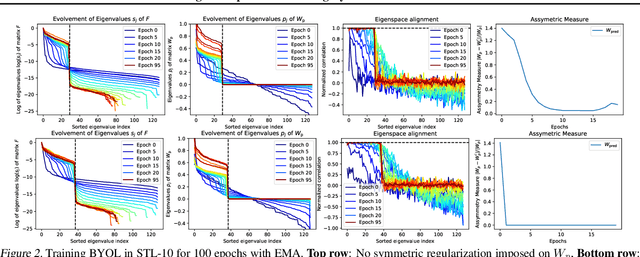

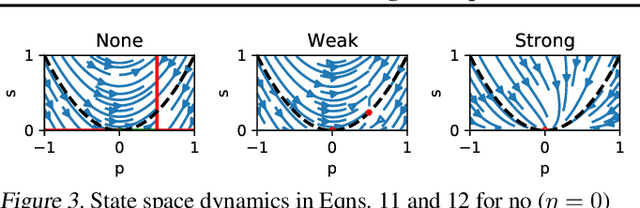
Contrastive approaches to self-supervised learning (SSL) learn representations by minimizing the distance between two augmented views of the same data point (positive pairs) and maximizing the same from different data points (negative pairs). However, recent approaches like BYOL and SimSiam, show remarkable performance {\it without} negative pairs, raising a fundamental theoretical question: how can SSL with only positive pairs avoid representational collapse? We study the nonlinear learning dynamics of non-contrastive SSL in simple linear networks. Our analysis yields conceptual insights into how non-contrastive SSL methods learn, how they avoid representational collapse, and how multiple factors, like predictor networks, stop-gradients, exponential moving averages, and weight decay all come into play. Our simple theory recapitulates the results of real-world ablation studies in both STL-10 and ImageNet. Furthermore, motivated by our theory we propose a novel approach that \emph{directly} sets the predictor based on the statistics of its inputs. In the case of linear predictors, our approach outperforms gradient training of the predictor by $5\%$ and on ImageNet it performs comparably with more complex two-layer non-linear predictors that employ BatchNorm. Code is released in https://github.com/facebookresearch/luckmatters/tree/master/ssl.
Embodied Intelligence via Learning and Evolution
Feb 03, 2021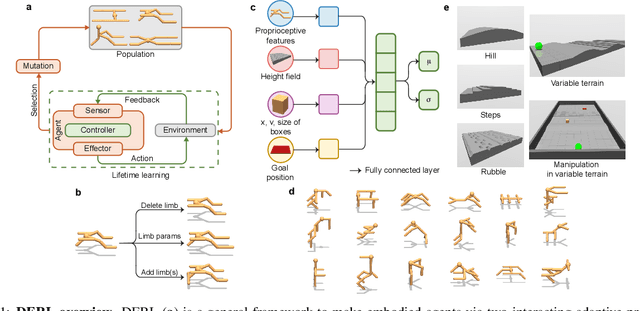

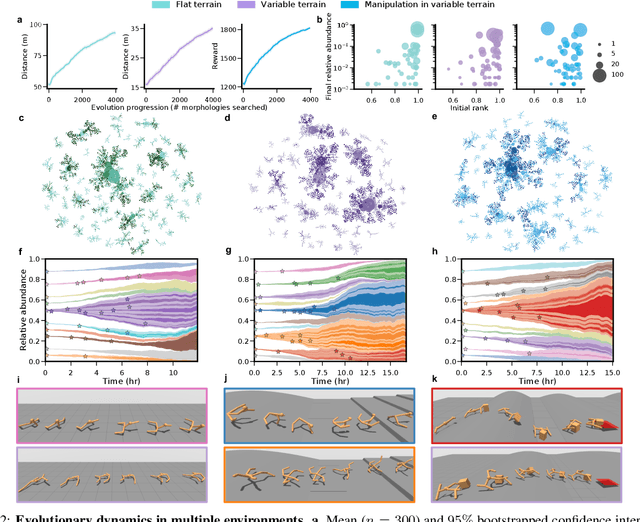
The intertwined processes of learning and evolution in complex environmental niches have resulted in a remarkable diversity of morphological forms. Moreover, many aspects of animal intelligence are deeply embodied in these evolved morphologies. However, the principles governing relations between environmental complexity, evolved morphology, and the learnability of intelligent control, remain elusive, partially due to the substantial challenge of performing large-scale in silico experiments on evolution and learning. We introduce Deep Evolutionary Reinforcement Learning (DERL): a novel computational framework which can evolve diverse agent morphologies to learn challenging locomotion and manipulation tasks in complex environments using only low level egocentric sensory information. Leveraging DERL we demonstrate several relations between environmental complexity, morphological intelligence and the learnability of control. First, environmental complexity fosters the evolution of morphological intelligence as quantified by the ability of a morphology to facilitate the learning of novel tasks. Second, evolution rapidly selects morphologies that learn faster, thereby enabling behaviors learned late in the lifetime of early ancestors to be expressed early in the lifetime of their descendants. In agents that learn and evolve in complex environments, this result constitutes the first demonstration of a long-conjectured morphological Baldwin effect. Third, our experiments suggest a mechanistic basis for both the Baldwin effect and the emergence of morphological intelligence through the evolution of morphologies that are more physically stable and energy efficient, and can therefore facilitate learning and control.
Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics
Dec 08, 2020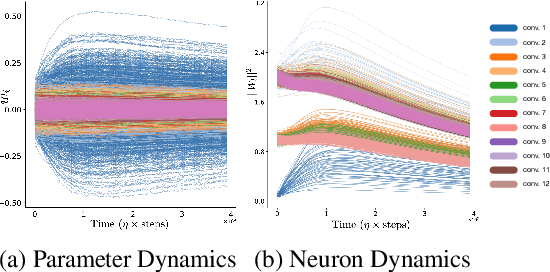
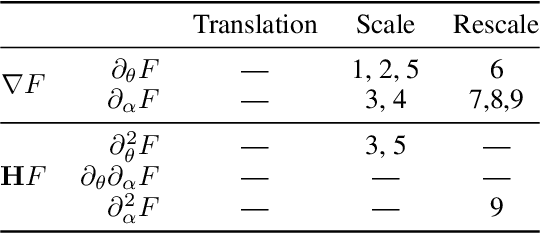
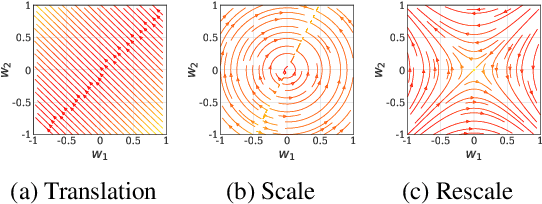

Predicting the dynamics of neural network parameters during training is one of the key challenges in building a theoretical foundation for deep learning. A central obstacle is that the motion of a network in high-dimensional parameter space undergoes discrete finite steps along complex stochastic gradients derived from real-world datasets. We circumvent this obstacle through a unifying theoretical framework based on intrinsic symmetries embedded in a network's architecture that are present for any dataset. We show that any such symmetry imposes stringent geometric constraints on gradients and Hessians, leading to an associated conservation law in the continuous-time limit of stochastic gradient descent (SGD), akin to Noether's theorem in physics. We further show that finite learning rates used in practice can actually break these symmetry induced conservation laws. We apply tools from finite difference methods to derive modified gradient flow, a differential equation that better approximates the numerical trajectory taken by SGD at finite learning rates. We combine modified gradient flow with our framework of symmetries to derive exact integral expressions for the dynamics of certain parameter combinations. We empirically validate our analytic predictions for learning dynamics on VGG-16 trained on Tiny ImageNet. Overall, by exploiting symmetry, our work demonstrates that we can analytically describe the learning dynamics of various parameter combinations at finite learning rates and batch sizes for state of the art architectures trained on any dataset.
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel
Oct 28, 2020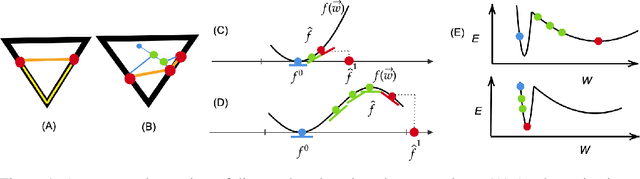
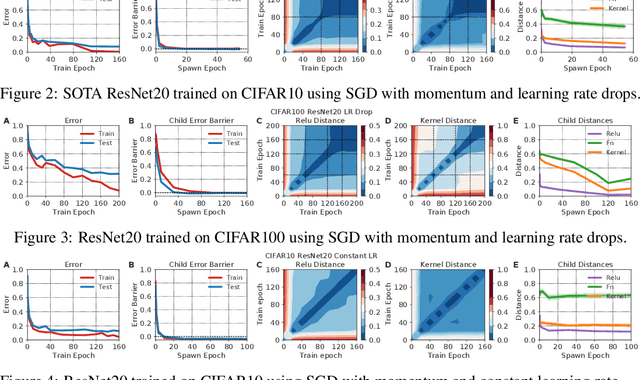
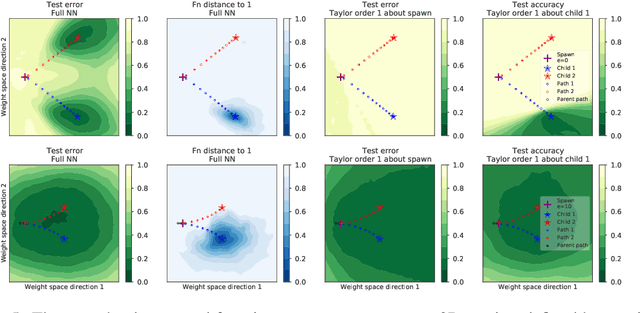
In suitably initialized wide networks, small learning rates transform deep neural networks (DNNs) into neural tangent kernel (NTK) machines, whose training dynamics is well-approximated by a linear weight expansion of the network at initialization. Standard training, however, diverges from its linearization in ways that are poorly understood. We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. In multiple neural architectures and datasets, we find these diverse measures evolve in a highly correlated manner, revealing a universal picture of the deep learning process. In this picture, deep network training exhibits a highly chaotic rapid initial transient that within 2 to 3 epochs determines the final linearly connected basin of low loss containing the end point of training. During this chaotic transient, the NTK changes rapidly, learning useful features from the training data that enables it to outperform the standard initial NTK by a factor of 3 in less than 3 to 4 epochs. After this rapid chaotic transient, the NTK changes at constant velocity, and its performance matches that of full network training in 15% to 45% of training time. Overall, our analysis reveals a striking correlation between a diverse set of metrics over training time, governed by a rapid chaotic to stable transition in the first few epochs, that together poses challenges and opportunities for the development of more accurate theories of deep learning.