 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTs for SITS: Vision Transformers for Satellite Image Time Series
Jan 26, 2023



In this paper we introduce the Temporo-Spatial Vision Transformer (TSViT), a fully-attentional model for general Satellite Image Time Series (SITS) processing based on the Vision Transformer (ViT). TSViT splits a SITS record into non-overlapping patches in space and time which are tokenized and subsequently processed by a factorized temporo-spatial encoder. We argue, that in contrast to natural images, a temporal-then-spatial factorization is more intuitive for SITS processing and present experimental evidence for this claim. Additionally, we enhance the model's discriminative power by introducing two novel mechanisms for acquisition-time-specific temporal positional encodings and multiple learnable class tokens. The effect of all novel design choices is evaluated through an extensive ablation study. Our proposed architecture achieves state-of-the-art performance, surpassing previous approaches by a significant margin in three publicly available SITS semantic segmentation and classification datasets. All model, training and evaluation codes are made publicly available to facilitate further research.
Weakly-Supervised Gaze Estimation from Synthetic Views
Dec 06, 20223D gaze estimation is most often tackled as learning a direct mapping between input images and the gaze vector or its spherical coordinates. Recently, it has been shown that pose estimation of the face, body and hands benefits from revising the learning target from few pose parameters to dense 3D coordinates. In this work, we leverage this observation and propose to tackle 3D gaze estimation as regression of 3D eye meshes. We overcome the absence of compatible ground truth by fitting a rigid 3D eyeball template on existing gaze datasets and propose to improve generalization by making use of widely available in-the-wild face images. To this end, we propose an automatic pipeline to retrieve robust gaze pseudo-labels from arbitrary face images and design a multi-view supervision framework to balance their effect during training. In our experiments, our method achieves improvement of 30% compared to state-of-the-art in cross-dataset gaze estimation, when no ground truth data are available for training, and 7% when they are. We make our project publicly available at https://github.com/Vagver/dense3Deyes.
Dynamic Neural Portraits
Nov 25, 2022



We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
Physically-Based Face Rendering for NIR-VIS Face Recognition
Nov 11, 2022Near infrared (NIR) to Visible (VIS) face matching is challenging due to the significant domain gaps as well as a lack of sufficient data for cross-modality model training. To overcome this problem, we propose a novel method for paired NIR-VIS facial image generation. Specifically, we reconstruct 3D face shape and reflectance from a large 2D facial dataset and introduce a novel method of transforming the VIS reflectance to NIR reflectance. We then use a physically-based renderer to generate a vast, high-resolution and photorealistic dataset consisting of various poses and identities in the NIR and VIS spectra. Moreover, to facilitate the identity feature learning, we propose an IDentity-based Maximum Mean Discrepancy (ID-MMD) loss, which not only reduces the modality gap between NIR and VIS images at the domain level but encourages the network to focus on the identity features instead of facial details, such as poses and accessories. Extensive experiments conducted on four challenging NIR-VIS face recognition benchmarks demonstrate that the proposed method can achieve comparable performance with the state-of-the-art (SOTA) methods without requiring any existing NIR-VIS face recognition datasets. With slightly fine-tuning on the target NIR-VIS face recognition datasets, our method can significantly surpass the SOTA performance. Code and pretrained models are released under the insightface (https://github.com/deepinsight/insightface/tree/master/recognition).
A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal
Nov 05, 2022



Face Restoration (FR) aims to restore High-Quality (HQ) faces from Low-Quality (LQ) input images, which is a domain-specific image restoration problem in the low-level computer vision area. The early face restoration methods mainly use statistic priors and degradation models, which are difficult to meet the requirements of real-world applications in practice. In recent years, face restoration has witnessed great progress after stepping into the deep learning era. However, there are few works to study deep learning-based face restoration methods systematically. Thus, this paper comprehensively surveys recent advances in deep learning techniques for face restoration. Specifically, we first summarize different problem formulations and analyze the characteristic of the face image. Second, we discuss the challenges of face restoration. Concerning these challenges, we present a comprehensive review of existing FR methods, including prior based methods and deep learning-based methods. Then, we explore developed techniques in the task of FR covering network architectures, loss functions, and benchmark datasets. We also conduct a systematic benchmark evaluation on representative methods. Finally, we discuss future directions, including network designs, metrics, benchmark datasets, applications,etc. We also provide an open-source repository for all the discussed methods, which is available at https://github.com/TaoWangzj/Awesome-Face-Restoration.
3DMM-RF: Convolutional Radiance Fields for 3D Face Modeling
Sep 15, 2022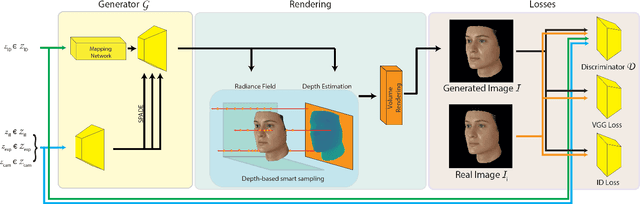
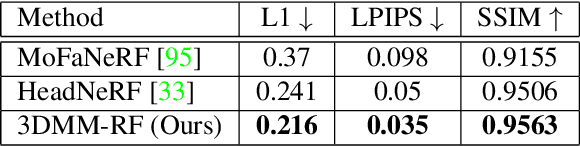

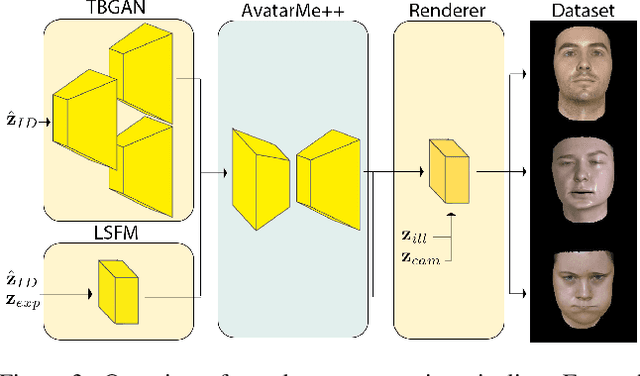
Facial 3D Morphable Models are a main computer vision subject with countless applications and have been highly optimized in the last two decades. The tremendous improvements of deep generative networks have created various possibilities for improving such models and have attracted wide interest. Moreover, the recent advances in neural radiance fields, are revolutionising novel-view synthesis of known scenes. In this work, we present a facial 3D Morphable Model, which exploits both of the above, and can accurately model a subject's identity, pose and expression and render it in arbitrary illumination. This is achieved by utilizing a powerful deep style-based generator to overcome two main weaknesses of neural radiance fields, their rigidity and rendering speed. We introduce a style-based generative network that synthesizes in one pass all and only the required rendering samples of a neural radiance field. We create a vast labelled synthetic dataset of facial renders, and train the network on these data, so that it can accurately model and generalize on facial identity, pose and appearance. Finally, we show that this model can accurately be fit to "in-the-wild" facial images of arbitrary pose and illumination, extract the facial characteristics, and be used to re-render the face in controllable conditions.
Inverse Image Frequency for Long-tailed Image Recognition
Sep 11, 2022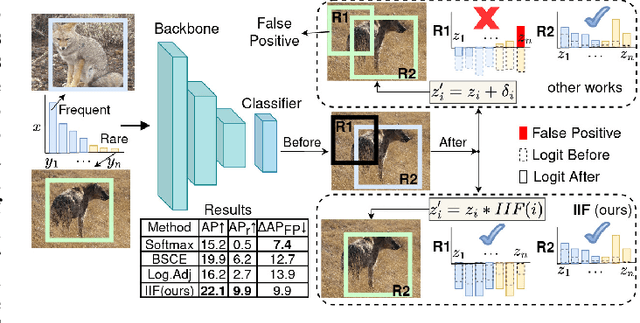
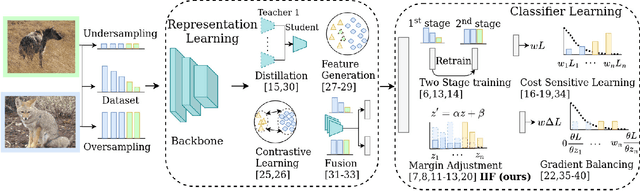
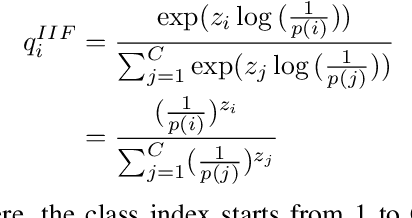
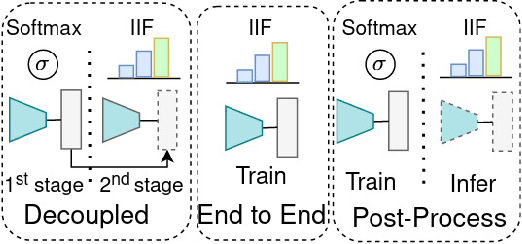
The long-tailed distribution is a common phenomenon in the real world. Extracted large scale image datasets inevitably demonstrate the long-tailed property and models trained with imbalanced data can obtain high performance for the over-represented categories, but struggle for the under-represented categories, leading to biased predictions and performance degradation. To address this challenge, we propose a novel de-biasing method named Inverse Image Frequency (IIF). IIF is a multiplicative margin adjustment transformation of the logits in the classification layer of a convolutional neural network. Our method achieves stronger performance than similar works and it is especially useful for downstream tasks such as long-tailed instance segmentation as it produces fewer false positive detections. Our extensive experiments show that IIF surpasses the state of the art on many long-tailed benchmarks such as ImageNet-LT, CIFAR-LT, Places-LT and LVIS, reaching 55.8% top-1 accuracy with ResNet50 on ImageNet-LT and 26.2% segmentation AP with MaskRCNN on LVIS. Code available at https://github.com/kostas1515/iif
Redesigning Multi-Scale Neural Network for Crowd Counting
Aug 04, 2022
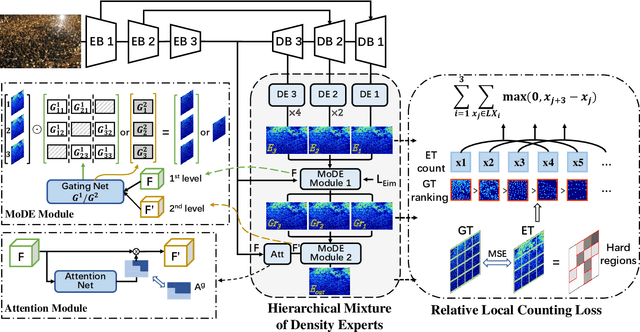
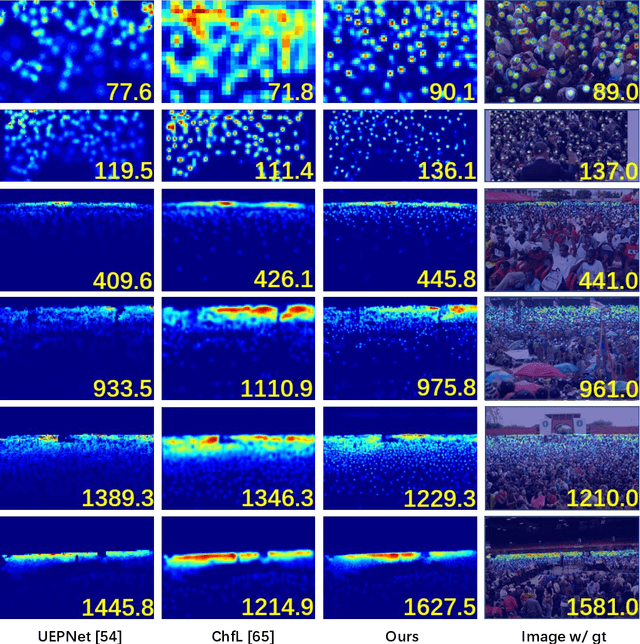
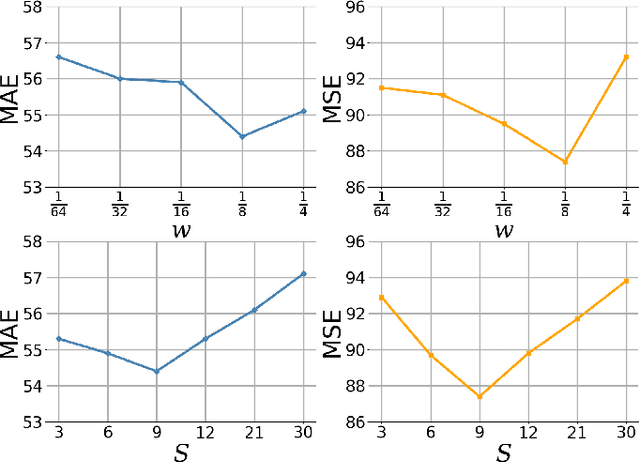
Perspective distortions and crowd variations make crowd counting a challenging task in computer vision. To tackle it, many previous works have used multi-scale architecture in deep neural networks (DNNs). Multi-scale branches can be either directly merged (e.g. by concatenation) or merged through the guidance of proxies (e.g. attentions) in the DNNs. Despite their prevalence, these combination methods are not sophisticated enough to deal with the per-pixel performance discrepancy over multi-scale density maps. In this work, we redesign the multi-scale neural network by introducing a hierarchical mixture of density experts, which hierarchically merges multi-scale density maps for crowd counting. Within the hierarchical structure, an expert competition and collaboration scheme is presented to encourage contributions from all scales; pixel-wise soft gating nets are introduced to provide pixel-wise soft weights for scale combinations in different hierarchies. The network is optimized using both the crowd density map and the local counting map, where the latter is obtained by local integration on the former. Optimizing both can be problematic because of their potential conflicts. We introduce a new relative local counting loss based on relative count differences among hard-predicted local regions in an image, which proves to be complementary to the conventional absolute error loss on the density map. Experiments show that our method achieves the state-of-the-art performance on five public datasets, i.e. ShanghaiTech, UCF_CC_50, JHU-CROWD++, NWPU-Crowd and Trancos.
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022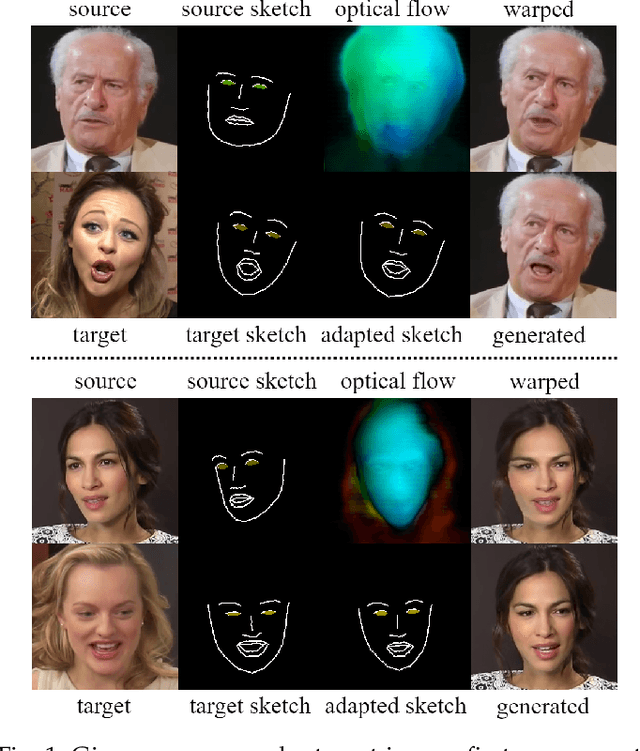
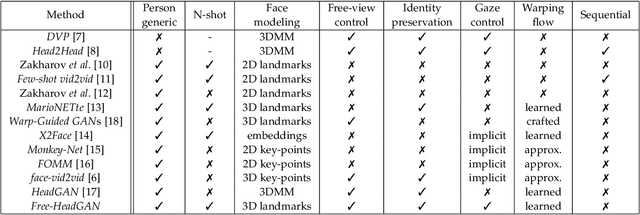
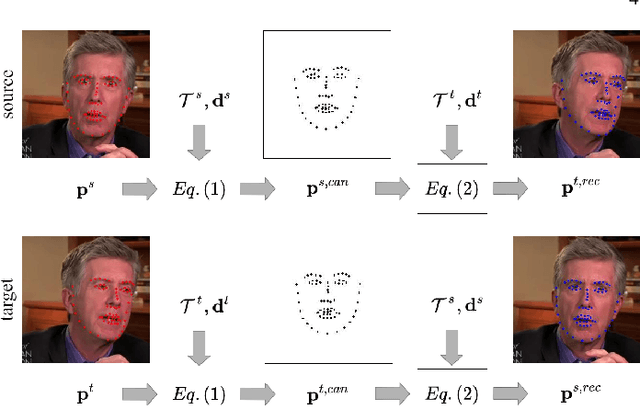
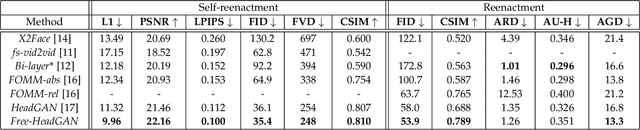
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
GraphWalks: Efficient Shape Agnostic Geodesic Shortest Path Estimation
May 30, 2022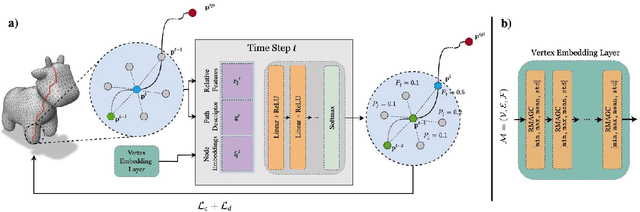
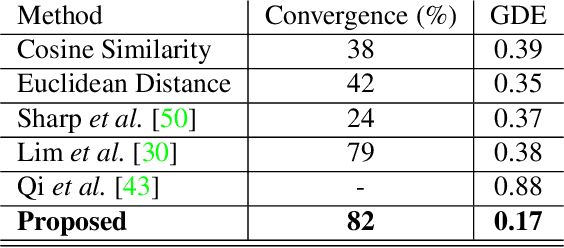
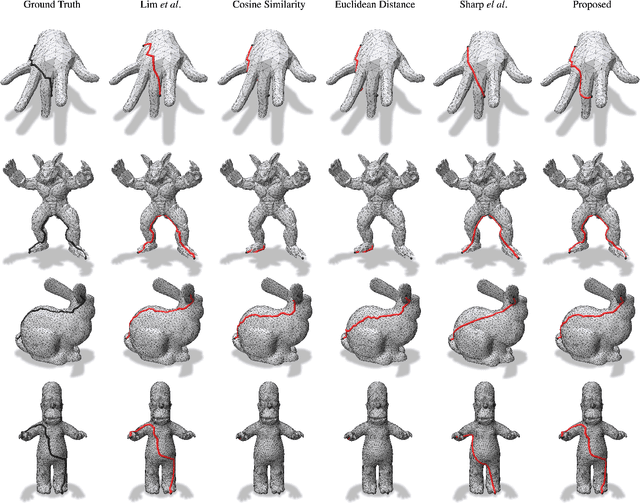
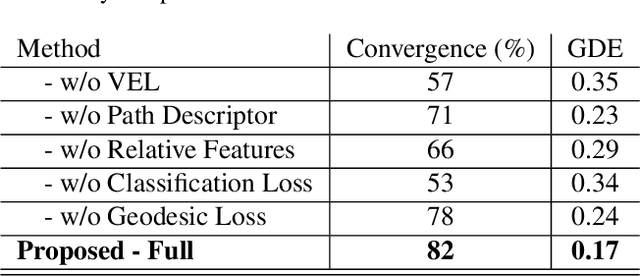
Geodesic paths and distances are among the most popular intrinsic properties of 3D surfaces. Traditionally, geodesic paths on discrete polygon surfaces were computed using shortest path algorithms, such as Dijkstra. However, such algorithms have two major limitations. They are non-differentiable which limits their direct usage in learnable pipelines and they are considerably time demanding. To address such limitations and alleviate the computational burden, we propose a learnable network to approximate geodesic paths. The proposed method is comprised by three major components: a graph neural network that encodes node positions in a high dimensional space, a path embedding that describes previously visited nodes and a point classifier that selects the next point in the path. The proposed method provides efficient approximations of the shortest paths and geodesic distances estimations. Given that all of the components of our method are fully differentiable, it can be directly plugged into any learnable pipeline as well as customized under any differentiable constraint. We extensively evaluate the proposed method with several qualitative and quantitative experiments.