 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image 3D Hand Reconstruction with Mesh Convolutions
May 13, 2019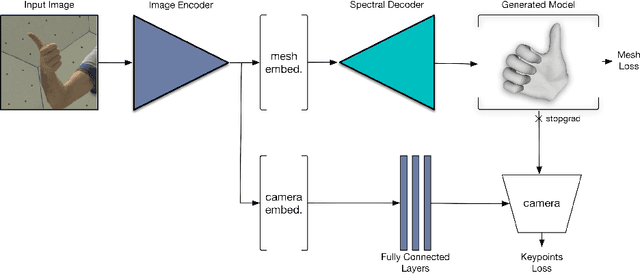

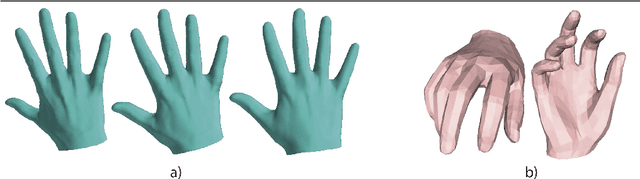
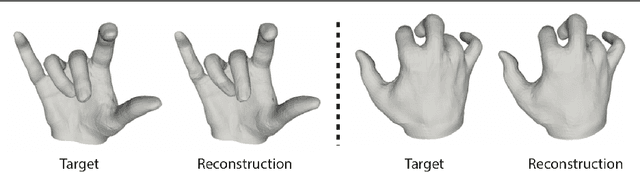
Monocular 3D reconstruction of deformable objects, such as human body parts, has been typically approached by predicting parameters of heavyweight linear models. In this paper, we demonstrate an alternative solution that is based on the idea of encoding images into a latent non-linear representation of meshes. The prior on 3D hand shapes is learned by training an autoencoder with intrinsic graph convolutions performed in the spectral domain. The pre-trained decoder acts as a non-linear statistical deformable model. The latent parameters that reconstruct the shape and articulated pose of hands in the image are predicted using an image encoder. We show that our system reconstructs plausible meshes and operates in real-time. We evaluate the quality of the mesh reconstructions produced by the decoder on a new dataset and show latent space interpolation results. Our code, data, and models will be made publicly available.
3DFaceGAN: Adversarial Nets for 3D Face Representation, Generation, and Translation
May 09, 2019


Over the past few years, Generative Adversarial Networks (GANs) have garnered increased interest among researchers in Computer Vision, with applications including, but not limited to, image generation, translation, imputation, and super-resolution. Nevertheless, no GAN-based method has been proposed in the literature that can successfully represent, generate or translate 3D facial shapes (meshes). This can be primarily attributed to two facts, namely that (a) publicly available 3D face databases are scarce as well as limited in terms of sample size and variability (e.g., few subjects, little diversity in race and gender), and (b) mesh convolutions for deep networks present several challenges that are not entirely tackled in the literature, leading to operator approximations and model instability, often failing to preserve high-frequency components of the distribution. As a result, linear methods such as Principal Component Analysis (PCA) have been mainly utilized towards 3D shape analysis, despite being unable to capture non-linearities and high frequency details of the 3D face - such as eyelid and lip variations. In this work, we present 3DFaceGAN, the first GAN tailored towards modeling the distribution of 3D facial surfaces, while retaining the high frequency details of 3D face shapes. We conduct an extensive series of both qualitative and quantitative experiments, where the merits of 3DFaceGAN are clearly demonstrated against other, state-of-the-art methods in tasks such as 3D shape representation, generation, and translation.
Neural 3D Morphable Models: Spiral Convolutional Networks for 3D Shape Representation Learning and Generation
May 09, 2019
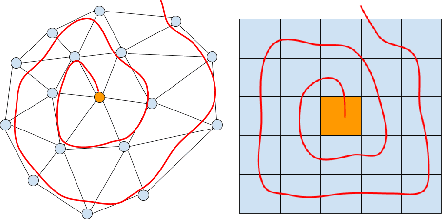
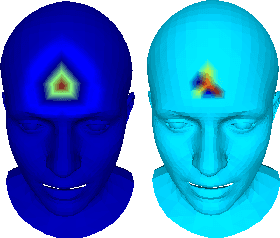
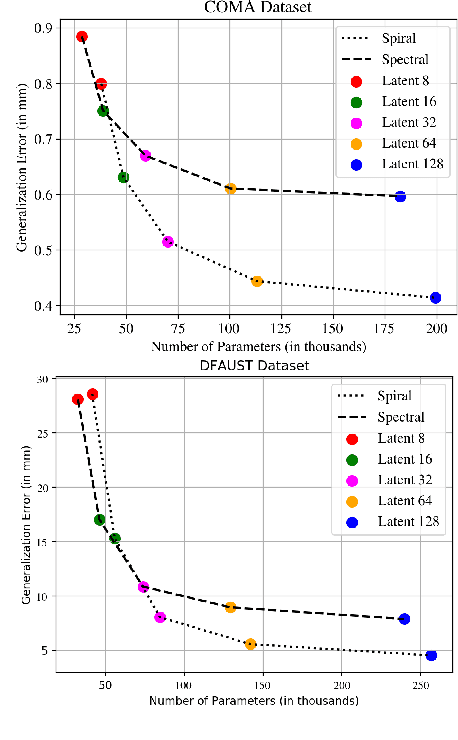
Generative models for 3D geometric data arise in many important applications in 3D computer vision and graphics. In this paper, we focus on 3D deformable shapes that share a common topological structure, such as human faces and bodies. Morphable Models were among the first attempts to create compact representations for such shapes; despite their effectiveness and simplicity, such models have limited representation power due to their linear formulation. Recently, non-linear learnable methods have been proposed, although most of them resort to intermediate representations, such as 3D grids of voxels or 2D views. In this paper, we introduce a convolutional mesh autoencoder and a GAN architecture based on the spiral convolutional operator, acting directly on the mesh and leveraging its underlying geometric structure. We provide an analysis of our convolution operator and demonstrate state-of-the-art results on 3D shape datasets compared to the linear Morphable Model and the recently proposed COMA model.
RetinaFace: Single-stage Dense Face Localisation in the Wild
May 04, 2019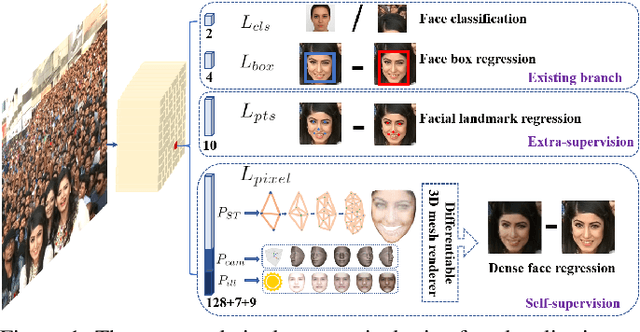

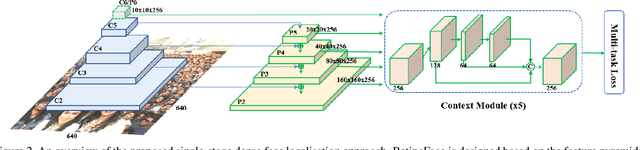

Though tremendous strides have been made in uncontrolled face detection, accurate and efficient face localisation in the wild remains an open challenge. This paper presents a robust single-stage face detector, named RetinaFace, which performs pixel-wise face localisation on various scales of faces by taking advantages of joint extra-supervised and self-supervised multi-task learning. Specifically, We make contributions in the following five aspects: (1) We manually annotate five facial landmarks on the WIDER FACE dataset and observe significant improvement in hard face detection with the assistance of this extra supervision signal. (2) We further add a self-supervised mesh decoder branch for predicting a pixel-wise 3D shape face information in parallel with the existing supervised branches. (3) On the WIDER FACE hard test set, RetinaFace outperforms the state of the art average precision (AP) by 1.1% (achieving AP equal to 91.4%). (4) On the IJB-C test set, RetinaFace enables state of the art methods (ArcFace) to improve their results in face verification (TAR=89.59% for FAR=1e-6). (5) By employing light-weight backbone networks, RetinaFace can run real-time on a single CPU core for a VGA-resolution image. Extra annotations and code have been made available at: https://github.com/deepinsight/insightface/tree/master/RetinaFace.
Face Video Generation from a Single Image and Landmarks
Apr 25, 2019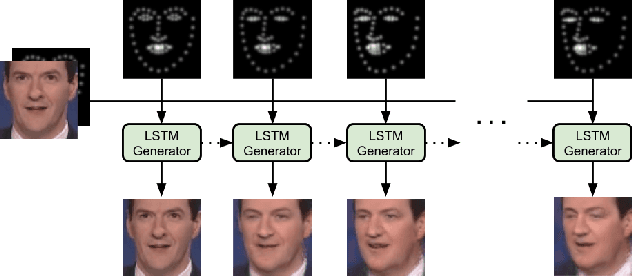
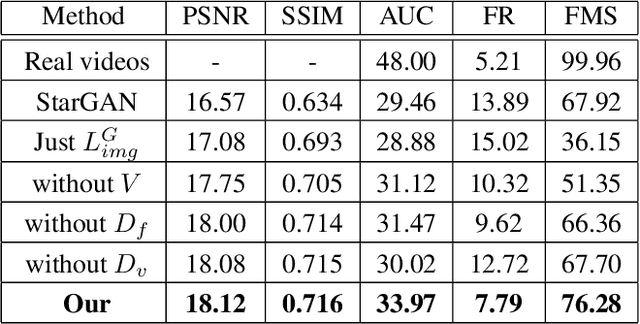
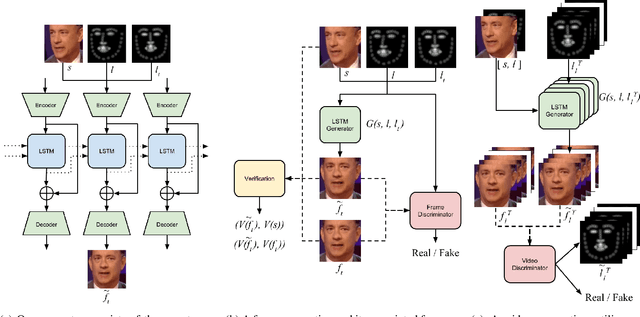
In this paper we are concerned with the challenging problem of producing a full image sequence of a deformable face given only an image and generic facial motions encoded by a set of sparse landmarks. To this end we build upon recent breakthroughs in image-to-image translation such as pix2pix, CycleGAN and StarGAN which learn Deep Convolutional Neural Networks (DCNNs) that learn to map aligned pairs or images between different domains (i.e., having different labels) and propose a new architecture which is not driven any more by labels but by spatial maps, facial landmarks. In particular, we propose the MotionGAN which transforms an input face image into a new one according to a heatmap of target landmarks. We show that it is possible to create very realistic face videos using a single image and a set of target landmarks. Furthermore, our method can be used to edit a facial image with arbitrary motions according to landmarks (e.g., expression, speech, etc.). This provides much more flexibility to face editing, expression transfer, facial video creation, etc. than models based on discrete expressions, audios or action units.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019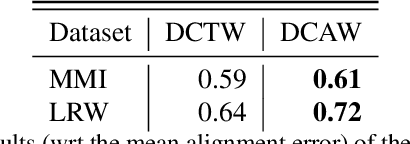
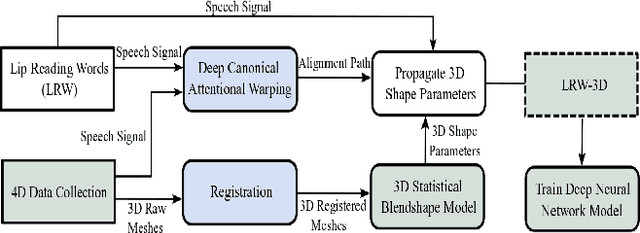

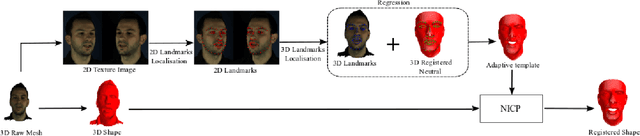
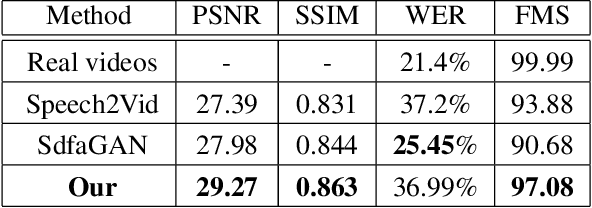
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.
Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders
Apr 06, 2019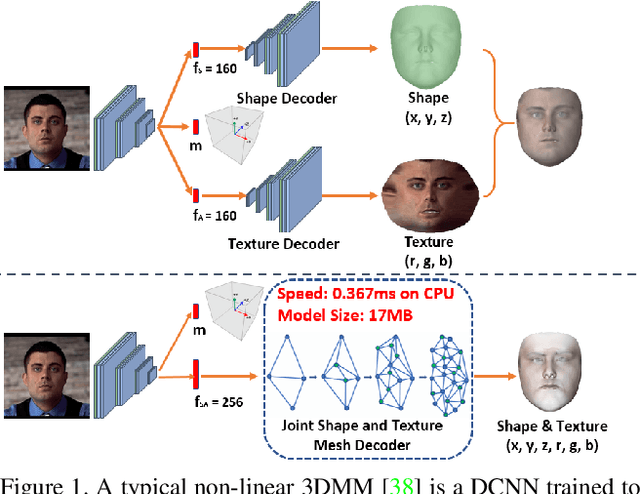
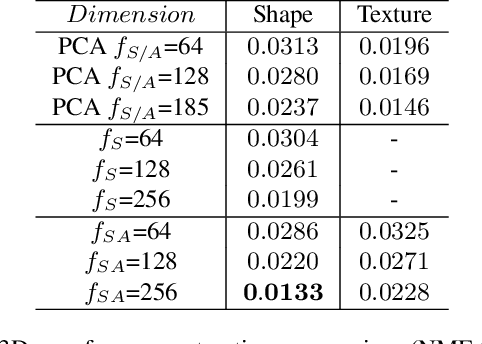
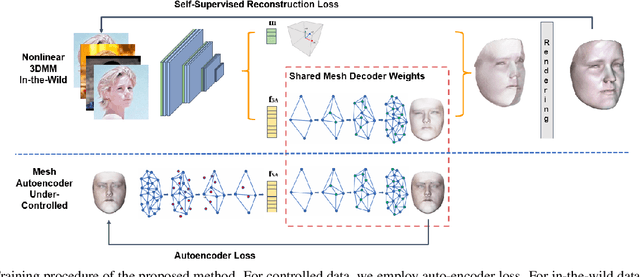

3D Morphable Models (3DMMs) are statistical models that represent facial texture and shape variations using a set of linear bases and more particular Principal Component Analysis (PCA). 3DMMs were used as statistical priors for reconstructing 3D faces from images by solving non-linear least square optimization problems. Recently, 3DMMs were used as generative models for training non-linear mappings (\ie, regressors) from image to the parameters of the models via Deep Convolutional Neural Networks (DCNNs). Nevertheless, all of the above methods use either fully connected layers or 2D convolutions on parametric unwrapped UV spaces leading to large networks with many parameters. In this paper, we present the first, to the best of our knowledge, non-linear 3DMMs by learning joint texture and shape auto-encoders using direct mesh convolutions. We demonstrate how these auto-encoders can be used to train very light-weight models that perform Coloured Mesh Decoding (CMD) in-the-wild at a speed of over 2500 FPS.
GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction
Apr 06, 2019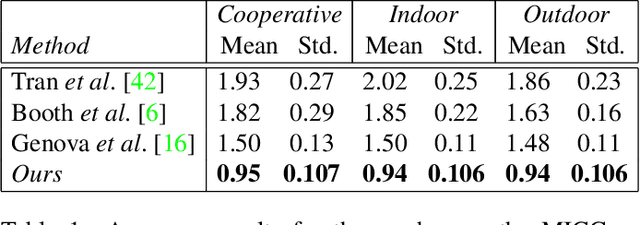
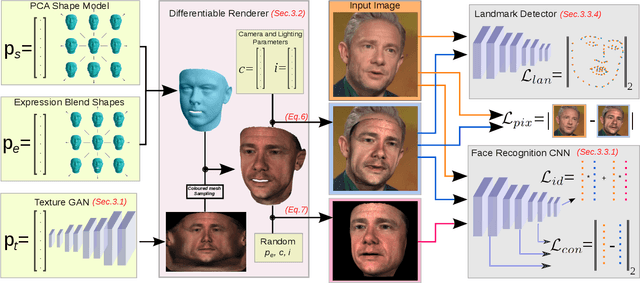

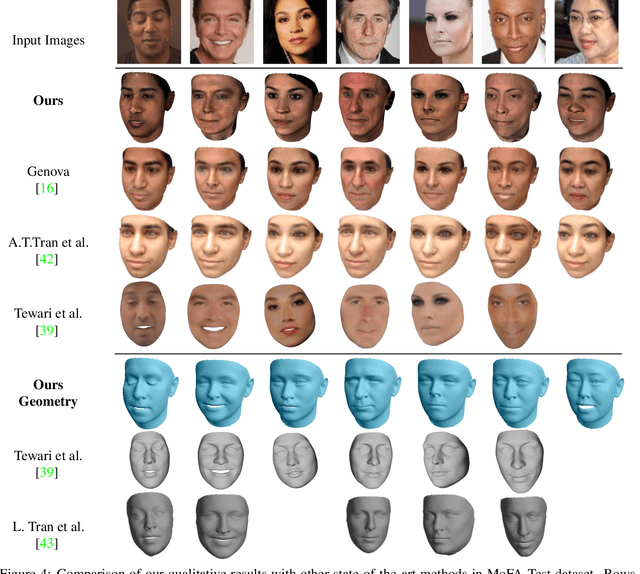
In the past few years, a lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the most recent works, differentiable renderers were employed in order to learn the relationship between the facial identity features and the parameters of a 3D morphable model for shape and texture. The texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction of the state-of-the-art methods is still not capable of modeling textures in high fidelity. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful generator of facial texture in UV space. Then, we revisit the original 3D Morphable Models (3DMMs) fitting approaches making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. We optimize the parameters with the supervision of pretrained deep identity features through our end-to-end differentiable framework. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
MeshGAN: Non-linear 3D Morphable Models of Faces
Mar 25, 2019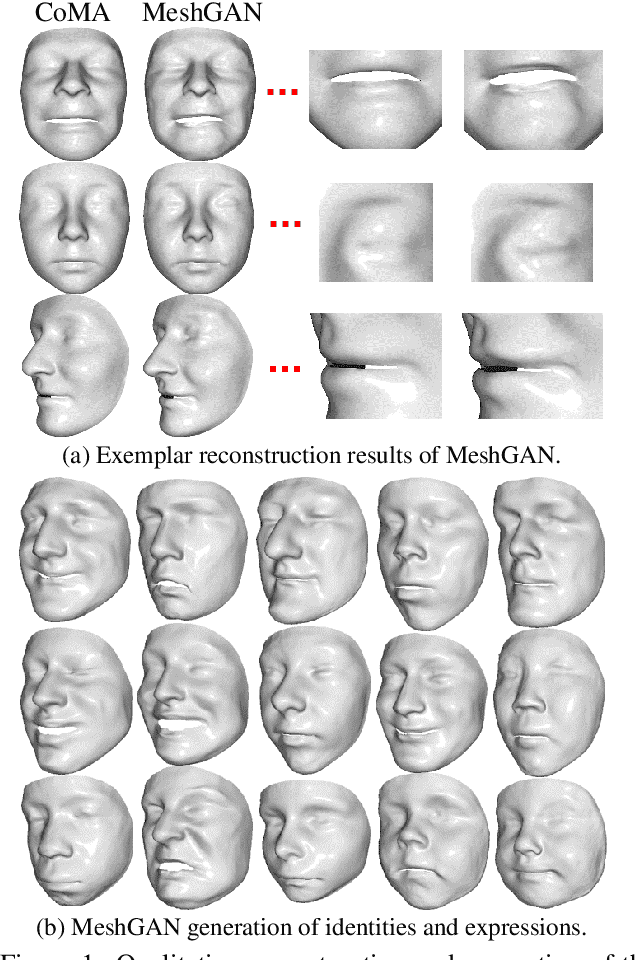


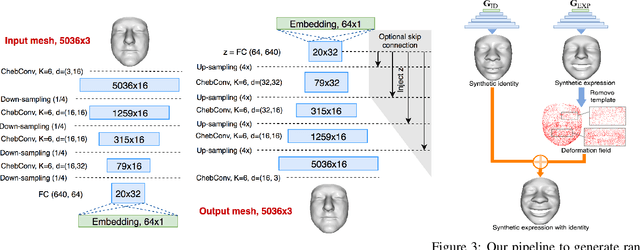
Generative Adversarial Networks (GANs) are currently the method of choice for generating visual data. Certain GAN architectures and training methods have demonstrated exceptional performance in generating realistic synthetic images (in particular, of human faces). However, for 3D object, GANs still fall short of the success they have had with images. One of the reasons is due to the fact that so far GANs have been applied as 3D convolutional architectures to discrete volumetric representations of 3D objects. In this paper, we propose the first intrinsic GANs architecture operating directly on 3D meshes (named as MeshGAN). Both quantitative and qualitative results are provided to show that MeshGAN can be used to generate high-fidelity 3D face with rich identities and expressions.
Combining 3D Morphable Models: A Large scale Face-and-Head Model
Mar 09, 2019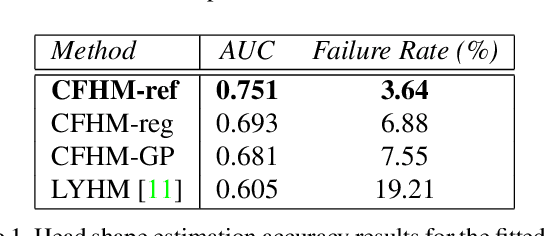
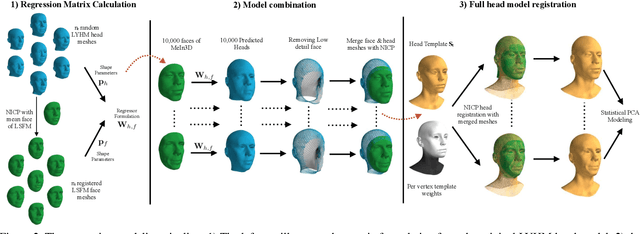
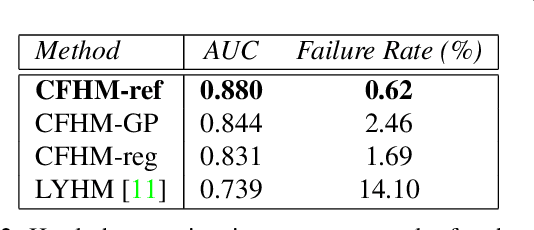
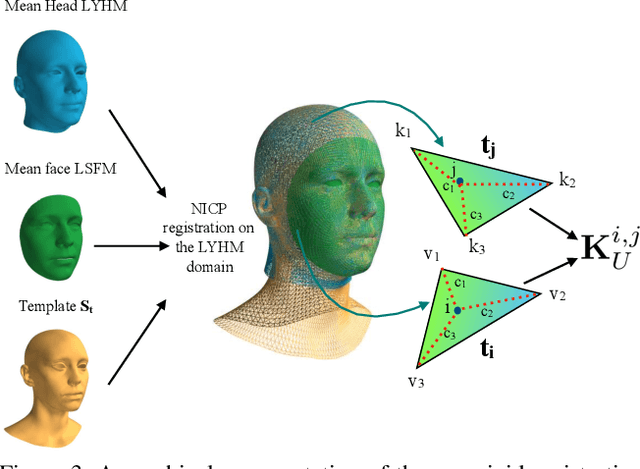
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D surfaces of an object class. In this context, we identify an interesting question that has previously not received research attention: is it possible to combine two or more 3DMMs that (a) are built using different templates that perhaps only partly overlap, (b) have different representation capabilities and (c) are built from different datasets that may not be publicly-available? In answering this question, we make two contributions. First, we propose two methods for solving this problem: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Second, as an example application of our approach, we build a new face-and-head shape model that combines the variability and facial detail of the LSFM with the full head modelling of the LYHM. The resulting combined shape model achieves state-of-the-art performance and outperforms existing head models by a large margin. Finally, as an application experiment, we reconstruct full head representations from single, unconstrained images by utilizing our proposed large-scale model in conjunction with the FaceWarehouse blendshapes for handling expressions.