 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning
Mar 02, 2023



Cooperative multi-agent reinforcement learning (MARL) requires agents to explore to learn to cooperate. Existing value-based MARL algorithms commonly rely on random exploration, such as $\epsilon$-greedy, which is inefficient in discovering multi-agent cooperation. Additionally, the environment in MARL appears non-stationary to any individual agent due to the simultaneous training of other agents, leading to highly variant and thus unstable optimisation signals. In this work, we propose ensemble value functions for multi-agent exploration (EMAX), a general framework to extend any value-based MARL algorithm. EMAX trains ensembles of value functions for each agent to address the key challenges of exploration and non-stationarity: (1) The uncertainty of value estimates across the ensemble is used in a UCB policy to guide the exploration of agents to parts of the environment which require cooperation. (2) Average value estimates across the ensemble serve as target values. These targets exhibit lower variance compared to commonly applied target networks and we show that they lead to more stable gradients during the optimisation. We instantiate three value-based MARL algorithms with EMAX, independent DQN, VDN and QMIX, and evaluate them in 21 tasks across four environments. Using ensembles of five value functions, EMAX improves sample efficiency and final evaluation returns of these algorithms by 54%, 55%, and 844%, respectively, averaged all 21 tasks.
Revisiting the Gumbel-Softmax in MADDPG
Feb 23, 2023MADDPG is an algorithm in multi-agent reinforcement learning (MARL) that extends the popular single-agent method, DDPG, to multi-agent scenarios. Importantly, DDPG is an algorithm designed for continuous action spaces, where the gradient of the state-action value function exists. For this algorithm to work in discrete action spaces, discrete gradient estimation must be performed. For MADDPG, the Gumbel-Softmax (GS) estimator is used -- a reparameterisation which relaxes a discrete distribution into a similar continuous one. This method, however, is statistically biased, and a recent MARL benchmarking paper suggests that this bias makes MADDPG perform poorly in grid-world situations, where the action space is discrete. Fortunately, many alternatives to the GS exist, boasting a wide range of properties. This paper explores several of these alternatives and integrates them into MADDPG for discrete grid-world scenarios. The corresponding impact on various performance metrics is then measured and analysed. It is found that one of the proposed estimators performs significantly better than the original GS in several tasks, achieving up to 55% higher returns, along with faster convergence.
Causal Social Explanations for Stochastic Sequential Multi-Agent Decision-Making
Feb 21, 2023We present a novel framework to generate causal explanations for the decisions of agents in stochastic sequential multi-agent environments. Explanations are given via natural language conversations answering a wide range of user queries and requiring associative, interventionist, or counterfactual causal reasoning. Instead of assuming any specific causal graph, our method relies on a generative model of interactions to simulate counterfactual worlds which are used to identify the salient causes behind decisions. We implement our method for motion planning for autonomous driving and test it in simulated scenarios with coupled interactions. Our method correctly identifies and ranks the relevant causes and delivers concise explanations to the users' queries.
Learning Complex Teamwork Tasks using a Sub-task Curriculum
Feb 09, 2023



Training a team to complete a complex task via multi-agent reinforcement learning can be difficult due to challenges such as policy search in a large policy space, and non-stationarity caused by mutually adapting agents. To facilitate efficient learning of complex multi-agent tasks, we propose an approach which uses an expert-provided curriculum of simpler multi-agent sub-tasks. In each sub-task of the curriculum, a subset of the entire team is trained to acquire sub-task-specific policies. The sub-teams are then merged and transferred to the target task, where their policies are collectively fined tuned to solve the more complex target task. We present MEDoE, a flexible method which identifies situations in the target task where each agent can use its sub-task-specific skills, and uses this information to modulate hyperparameters for learning and exploration during the fine-tuning process. We compare MEDoE to multi-agent reinforcement learning baselines that train from scratch in the full task, and with na\"ive applications of standard multi-agent reinforcement learning techniques for fine-tuning. We show that MEDoE outperforms baselines which train from scratch or use na\"ive fine-tuning approaches, requiring significantly fewer total training timesteps to solve a range of complex teamwork tasks.
Scalable Multi-Agent Reinforcement Learning for Warehouse Logistics with Robotic and Human Co-Workers
Dec 22, 2022



This project leverages advances in multi-agent reinforcement learning (MARL) to improve the efficiency and flexibility of order-picking systems for commercial warehouses. We envision a warehouse of the future in which dozens of mobile robots and human pickers work together to collect and deliver items within the warehouse. The fundamental problem we tackle, called the order-picking problem, is how these worker agents must coordinate their movement and actions in the warehouse to maximise performance (e.g. order throughput) under given resource constraints. Established industry methods using heuristic approaches require large engineering efforts to optimise for innately variable warehouse configurations. In contrast, the MARL framework can be flexibly applied to any warehouse configuration (e.g. size, layout, number/types of workers, item replenishment frequency) and the agents learn via a process of trial-and-error how to optimally cooperate with one another. This paper details the current status of the R&D effort initiated by Dematic and the University of Edinburgh towards a general-purpose and scalable MARL solution for the order-picking problem in realistic warehouses.
Planning with Occluded Traffic Agents using Bi-Level Variational Occlusion Models
Oct 26, 2022Reasoning with occluded traffic agents is a significant open challenge for planning for autonomous vehicles. Recent deep learning models have shown impressive results for predicting occluded agents based on the behaviour of nearby visible agents; however, as we show in experiments, these models are difficult to integrate into downstream planning. To this end, we propose Bi-level Variational Occlusion Models (BiVO), a two-step generative model that first predicts likely locations of occluded agents, and then generates likely trajectories for the occluded agents. In contrast to existing methods, BiVO outputs a trajectory distribution which can then be sampled from and integrated into standard downstream planning. We evaluate the method in closed-loop replay simulation using the real-world nuScenes dataset. Our results suggest that BiVO can successfully learn to predict occluded agent trajectories, and these predictions lead to better subsequent motion plans in critical scenarios.
DiPA: Diverse and Probabilistically Accurate Interactive Prediction
Oct 12, 2022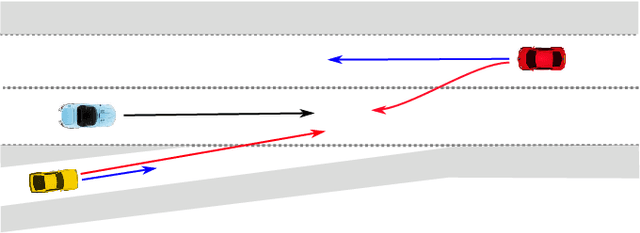
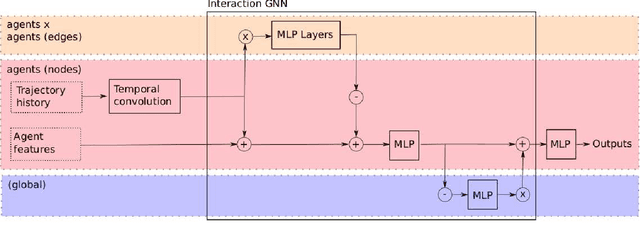

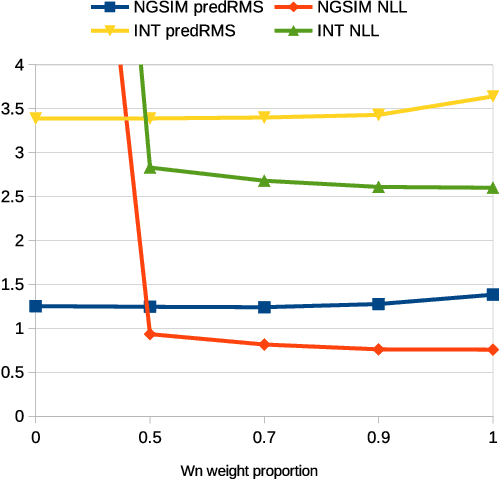
Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Previous interactive predictors have used closest-mode evaluations, which test if one of a set of predictions covers the ground-truth, but not if additional unlikely predictions are made. The presence of unlikely predictions can interfere with planning, by indicating conflict with the ego plan when it is not likely to occur. Closest-mode evaluations are not sufficient for showing a predictor is useful, an effective predictor also needs to accurately estimate mode probabilities, and to be evaluated using probabilistic measures. These two evaluation approaches, eg. predicted-mode RMS and minADE/FDE, are analogous to precision and recall in binary classification, and there is a challenging trade-off between prediction strategies for each. We present DiPA, a method for producing diverse predictions while also capturing accurate probabilistic estimates. DiPA uses a flexible representation that captures interactions in widely varying road topologies, and uses a novel training regime for a Gaussian Mixture Model that supports diversity of predicted modes, along with accurate spatial distribution and mode probability estimates. DiPA achieves state-of-the-art performance on INTERACTION and NGSIM, and improves over a baseline (MFP) when both closest-mode and probabilistic evaluations are used at the same time.
A General Learning Framework for Open Ad Hoc Teamwork Using Graph-based Policy Learning
Oct 11, 2022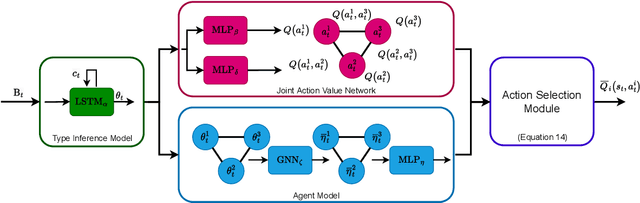
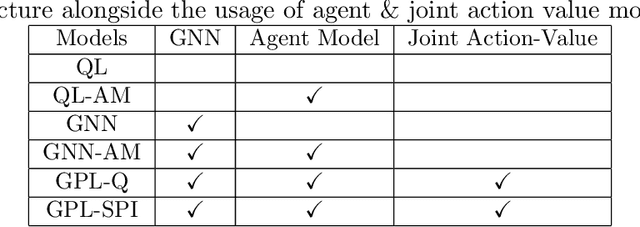
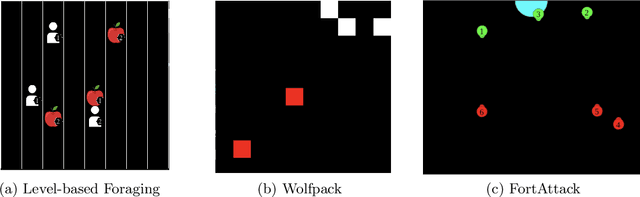
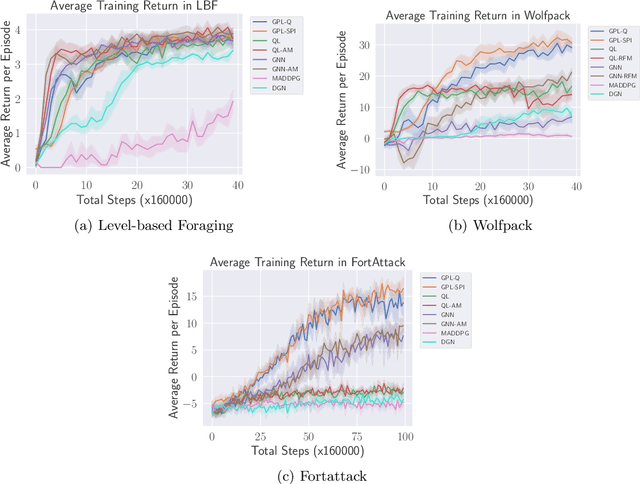
Open ad hoc teamwork is the problem of training a single agent to efficiently collaborate with an unknown group of teammates whose composition may change over time. A variable team composition creates challenges for the agent, such as the requirement to adapt to new team dynamics and dealing with changing state vector sizes. These challenges are aggravated in real-world applications where the controlled agent has no access to the full state of the environment. In this work, we develop a class of solutions for open ad hoc teamwork under full and partial observability. We start by developing a solution for the fully observable case that leverages graph neural network architectures to obtain an optimal policy based on reinforcement learning. We then extend this solution to partially observable scenarios by proposing different methodologies that maintain belief estimates over the latent environment states and team composition. These belief estimates are combined with our solution for the fully observable case to compute an agent's optimal policy under partial observability in open ad hoc teamwork. Empirical results demonstrate that our approach can learn efficient policies in open ad hoc teamwork in full and partially observable cases. Further analysis demonstrates that our methods' success is a result of effectively learning the effects of teammates' actions while also inferring the inherent state of the environment under partial observability
Pareto Actor-Critic for Equilibrium Selection in Multi-Agent Reinforcement Learning
Sep 28, 2022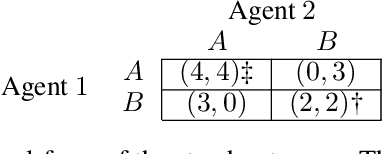
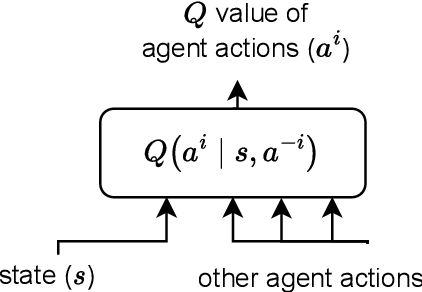
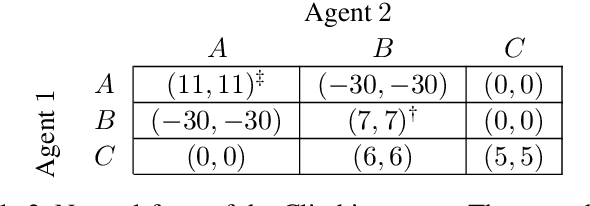
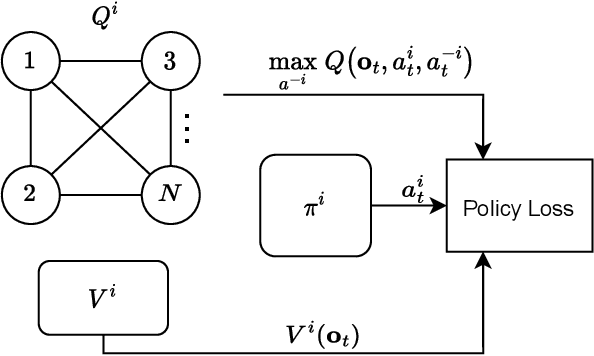
Equilibrium selection in multi-agent games refers to the problem of selecting a Pareto-optimal equilibrium. It has been shown that many state-of-the-art multi-agent reinforcement learning (MARL) algorithms are prone to converging to Pareto-dominated equilibria due to the uncertainty each agent has about the policy of the other agents during training. To address suboptimal equilibrium selection, we propose Pareto-AC (PAC), an actor-critic algorithm that utilises a simple principle of no-conflict games (a superset of cooperative games with identical rewards): each agent can assume the others will choose actions that will lead to a Pareto-optimal equilibrium. We evaluate PAC in a diverse set of multi-agent games and show that it converges to higher episodic returns compared to alternative MARL algorithms, as well as successfully converging to a Pareto-optimal equilibrium in a range of matrix games. Finally, we propose a graph neural network extension which is shown to efficiently scale in games with up to 15 agents.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.