 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning by Estimating Expertise of Demonstrators
Feb 02, 2022



Many existing imitation learning datasets are collected from multiple demonstrators, each with different expertise at different parts of the environment. Yet, standard imitation learning algorithms typically treat all demonstrators as homogeneous, regardless of their expertise, absorbing the weaknesses of any suboptimal demonstrators. In this work, we show that unsupervised learning over demonstrator expertise can lead to a consistent boost in the performance of imitation learning algorithms. We develop and optimize a joint model over a learned policy and expertise levels of the demonstrators. This enables our model to learn from the optimal behavior and filter out the suboptimal behavior of each demonstrator. Our model learns a single policy that can outperform even the best demonstrator, and can be used to estimate the expertise of any demonstrator at any state. We illustrate our findings on real-robotic continuous control tasks from Robomimic and discrete environments such as MiniGrid and chess, out-performing competing methods in $21$ out of $23$ settings, with an average of $7\%$ and up to $60\%$ improvement in terms of the final reward.
Conditional Imitation Learning for Multi-Agent Games
Jan 05, 2022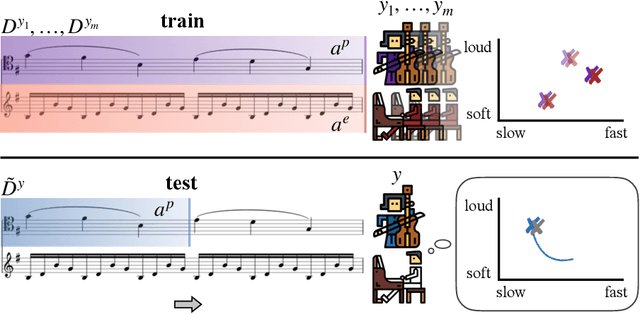
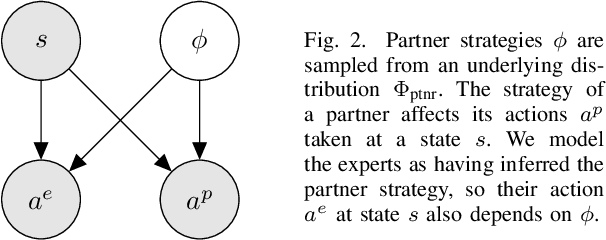
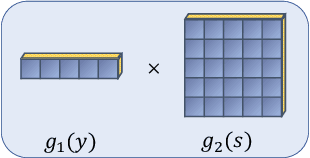
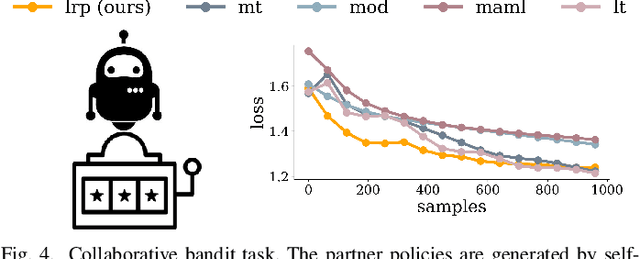
While advances in multi-agent learning have enabled the training of increasingly complex agents, most existing techniques produce a final policy that is not designed to adapt to a new partner's strategy. However, we would like our AI agents to adjust their strategy based on the strategies of those around them. In this work, we study the problem of conditional multi-agent imitation learning, where we have access to joint trajectory demonstrations at training time, and we must interact with and adapt to new partners at test time. This setting is challenging because we must infer a new partner's strategy and adapt our policy to that strategy, all without knowledge of the environment reward or dynamics. We formalize this problem of conditional multi-agent imitation learning, and propose a novel approach to address the difficulties of scalability and data scarcity. Our key insight is that variations across partners in multi-agent games are often highly structured, and can be represented via a low-rank subspace. Leveraging tools from tensor decomposition, our model learns a low-rank subspace over ego and partner agent strategies, then infers and adapts to a new partner strategy by interpolating in the subspace. We experiments with a mix of collaborative tasks, including bandits, particle, and Hanabi environments. Additionally, we test our conditional policies against real human partners in a user study on the Overcooked game. Our model adapts better to new partners compared to baselines, and robustly handles diverse settings ranging from discrete/continuous actions and static/online evaluation with AI/human partners.
IS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
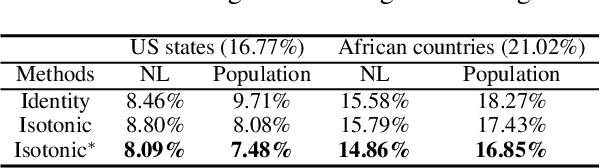
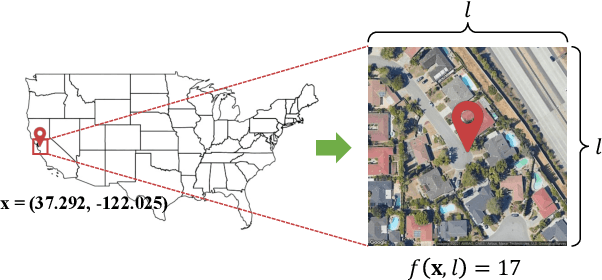
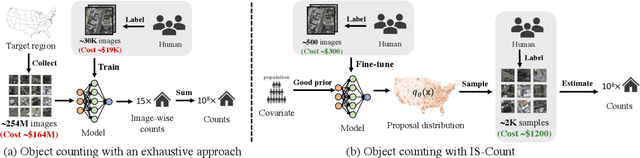
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
Quantifying and Understanding Adversarial Examples in Discrete Input Spaces
Dec 12, 2021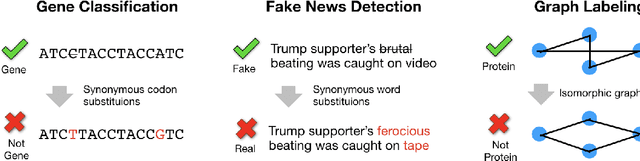
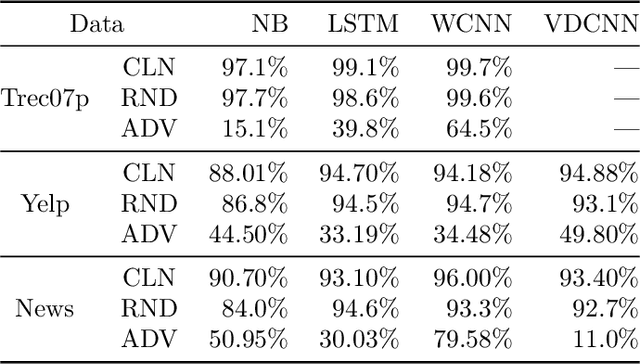


Modern classification algorithms are susceptible to adversarial examples--perturbations to inputs that cause the algorithm to produce undesirable behavior. In this work, we seek to understand and extend adversarial examples across domains in which inputs are discrete, particularly across new domains, such as computational biology. As a step towards this goal, we formalize a notion of synonymous adversarial examples that applies in any discrete setting and describe a simple domain-agnostic algorithm to construct such examples. We apply this algorithm across multiple domains--including sentiment analysis and DNA sequence classification--and find that it consistently uncovers adversarial examples. We seek to understand their prevalence theoretically and we attribute their existence to spurious token correlations, a statistical phenomenon that is specific to discrete spaces. Our work is a step towards a domain-agnostic treatment of discrete adversarial examples analogous to that of continuous inputs.
An Experimental Design Perspective on Model-Based Reinforcement Learning
Dec 09, 2021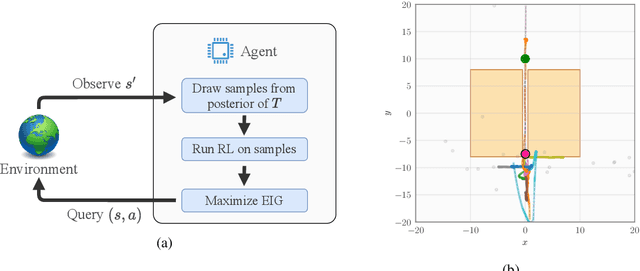
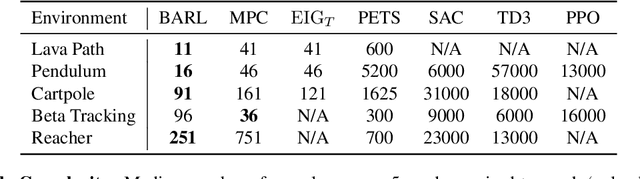
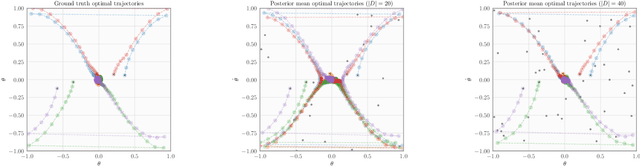

In many practical applications of RL, it is expensive to observe state transitions from the environment. For example, in the problem of plasma control for nuclear fusion, computing the next state for a given state-action pair requires querying an expensive transition function which can lead to many hours of computer simulation or dollars of scientific research. Such expensive data collection prohibits application of standard RL algorithms which usually require a large number of observations to learn. In this work, we address the problem of efficiently learning a policy while making a minimal number of state-action queries to the transition function. In particular, we leverage ideas from Bayesian optimal experimental design to guide the selection of state-action queries for efficient learning. We propose an acquisition function that quantifies how much information a state-action pair would provide about the optimal solution to a Markov decision process. At each iteration, our algorithm maximizes this acquisition function, to choose the most informative state-action pair to be queried, thus yielding a data-efficient RL approach. We experiment with a variety of simulated continuous control problems and show that our approach learns an optimal policy with up to $5$ -- $1,000\times$ less data than model-based RL baselines and $10^3$ -- $10^5\times$ less data than model-free RL baselines. We also provide several ablated comparisons which point to substantial improvements arising from the principled method of obtaining data.
A Unified Framework for Multi-distribution Density Ratio Estimation
Dec 07, 2021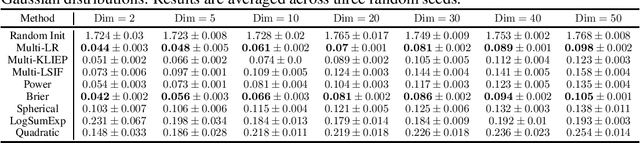
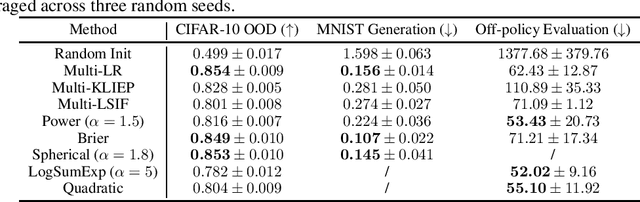
Binary density ratio estimation (DRE), the problem of estimating the ratio $p_1/p_2$ given their empirical samples, provides the foundation for many state-of-the-art machine learning algorithms such as contrastive representation learning and covariate shift adaptation. In this work, we consider a generalized setting where given samples from multiple distributions $p_1, \ldots, p_k$ (for $k > 2$), we aim to efficiently estimate the density ratios between all pairs of distributions. Such a generalization leads to important new applications such as estimating statistical discrepancy among multiple random variables like multi-distribution $f$-divergence, and bias correction via multiple importance sampling. We then develop a general framework from the perspective of Bregman divergence minimization, where each strictly convex multivariate function induces a proper loss for multi-distribution DRE. Moreover, we rederive the theoretical connection between multi-distribution density ratio estimation and class probability estimation, justifying the use of any strictly proper scoring rule composite with a link function for multi-distribution DRE. We show that our framework leads to methods that strictly generalize their counterparts in binary DRE, as well as new methods that show comparable or superior performance on various downstream tasks.
BCD Nets: Scalable Variational Approaches for Bayesian Causal Discovery
Dec 06, 2021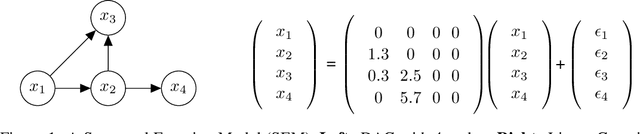

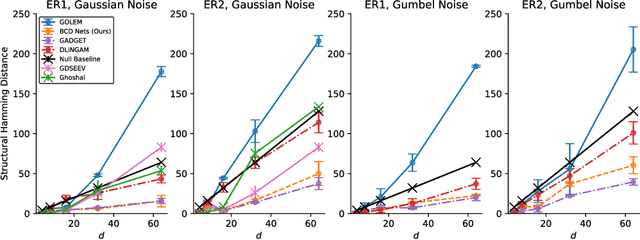

A structural equation model (SEM) is an effective framework to reason over causal relationships represented via a directed acyclic graph (DAG). Recent advances have enabled effective maximum-likelihood point estimation of DAGs from observational data. However, a point estimate may not accurately capture the uncertainty in inferring the underlying graph in practical scenarios, wherein the true DAG is non-identifiable and/or the observed dataset is limited. We propose Bayesian Causal Discovery Nets (BCD Nets), a variational inference framework for estimating a distribution over DAGs characterizing a linear-Gaussian SEM. Developing a full Bayesian posterior over DAGs is challenging due to the the discrete and combinatorial nature of graphs. We analyse key design choices for scalable VI over DAGs, such as 1) the parametrization of DAGs via an expressive variational family, 2) a continuous relaxation that enables low-variance stochastic optimization, and 3) suitable priors over the latent variables. We provide a series of experiments on real and synthetic data showing that BCD Nets outperform maximum-likelihood methods on standard causal discovery metrics such as structural Hamming distance in low data regimes.
HyperSPNs: Compact and Expressive Probabilistic Circuits
Dec 02, 2021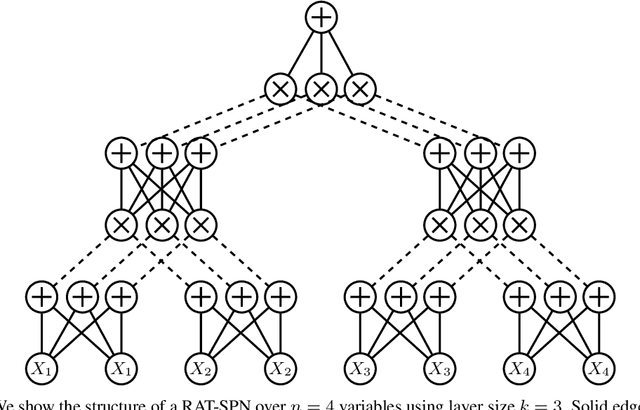
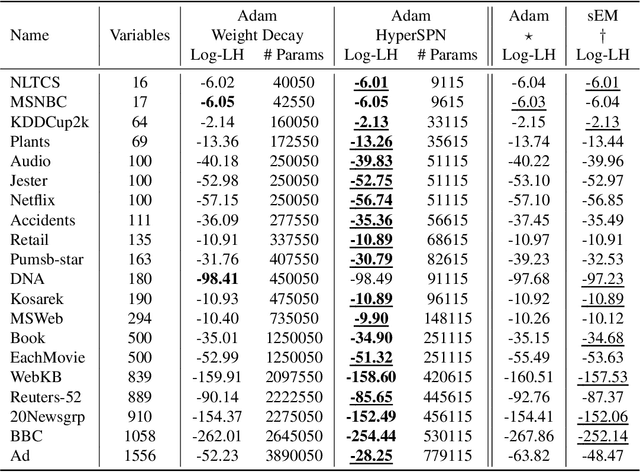
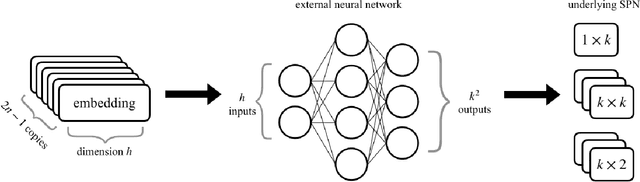
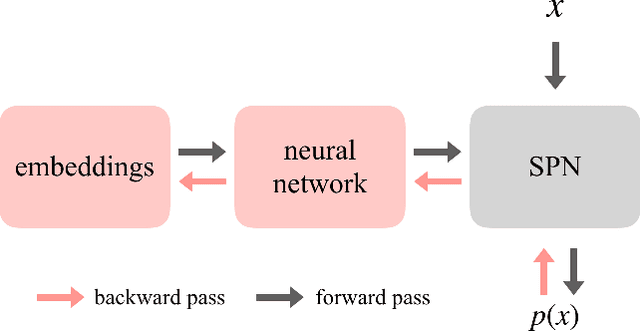
Probabilistic circuits (PCs) are a family of generative models which allows for the computation of exact likelihoods and marginals of its probability distributions. PCs are both expressive and tractable, and serve as popular choices for discrete density estimation tasks. However, large PCs are susceptible to overfitting, and only a few regularization strategies (e.g., dropout, weight-decay) have been explored. We propose HyperSPNs: a new paradigm of generating the mixture weights of large PCs using a small-scale neural network. Our framework can be viewed as a soft weight-sharing strategy, which combines the greater expressiveness of large models with the better generalization and memory-footprint properties of small models. We show the merits of our regularization strategy on two state-of-the-art PC families introduced in recent literature -- RAT-SPNs and EiNETs -- and demonstrate generalization improvements in both models on a suite of density estimation benchmarks in both discrete and continuous domains.
Density Ratio Estimation via Infinitesimal Classification
Nov 22, 2021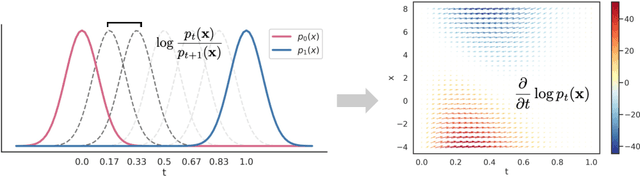
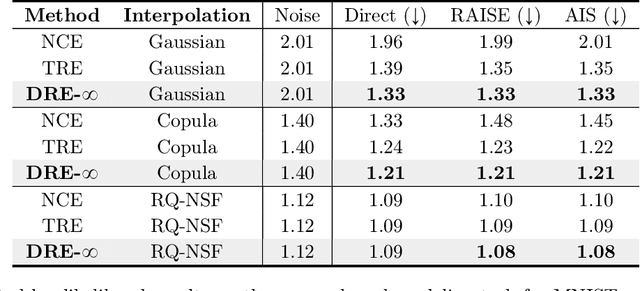

Density ratio estimation (DRE) is a fundamental machine learning technique for comparing two probability distributions. However, existing methods struggle in high-dimensional settings, as it is difficult to accurately compare probability distributions based on finite samples. In this work we propose DRE-\infty, a divide-and-conquer approach to reduce DRE to a series of easier subproblems. Inspired by Monte Carlo methods, we smoothly interpolate between the two distributions via an infinite continuum of intermediate bridge distributions. We then estimate the instantaneous rate of change of the bridge distributions indexed by time (the "time score") -- a quantity defined analogously to data (Stein) scores -- with a novel time score matching objective. Crucially, the learned time scores can then be integrated to compute the desired density ratio. In addition, we show that traditional (Stein) scores can be used to obtain integration paths that connect regions of high density in both distributions, improving performance in practice. Empirically, we demonstrate that our approach performs well on downstream tasks such as mutual information estimation and energy-based modeling on complex, high-dimensional datasets.
Solving Inverse Problems in Medical Imaging with Score-Based Generative Models
Nov 15, 2021
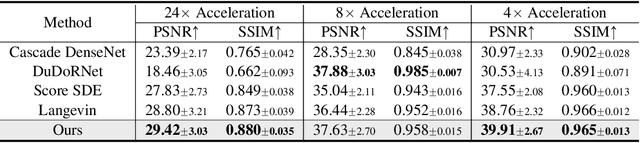

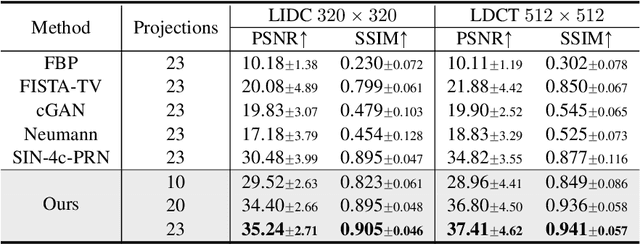
Reconstructing medical images from partial measurements is an important inverse problem in Computed Tomography (CT) and Magnetic Resonance Imaging (MRI). Existing solutions based on machine learning typically train a model to directly map measurements to medical images, leveraging a training dataset of paired images and measurements. These measurements are typically synthesized from images using a fixed physical model of the measurement process, which hinders the generalization capability of models to unknown measurement processes. To address this issue, we propose a fully unsupervised technique for inverse problem solving, leveraging the recently introduced score-based generative models. Specifically, we first train a score-based generative model on medical images to capture their prior distribution. Given measurements and a physical model of the measurement process at test time, we introduce a sampling method to reconstruct an image consistent with both the prior and the observed measurements. Our method does not assume a fixed measurement process during training, and can thus be flexibly adapted to different measurement processes at test time. Empirically, we observe comparable or better performance to supervised learning techniques in several medical imaging tasks in CT and MRI, while demonstrating significantly better generalization to unknown measurement processes.