 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Embedding Complexity in Domain-invariant Representations
Oct 13, 2019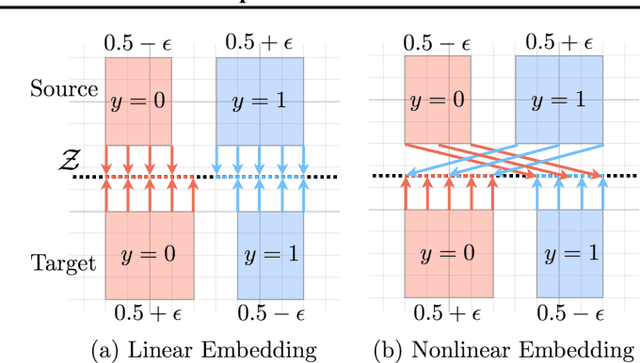
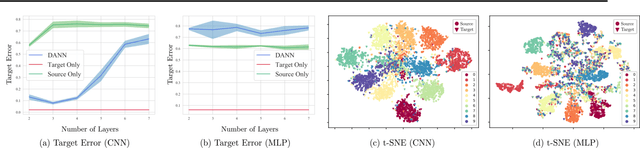
Unsupervised domain adaptation aims to generalize the hypothesis trained in a source domain to an unlabeled target domain. One popular approach to this problem is to learn domain-invariant embeddings for both domains. In this work, we study, theoretically and empirically, the effect of the embedding complexity on generalization to the target domain. In particular, this complexity affects an upper bound on the target risk; this is reflected in experiments, too. Next, we specify our theoretical framework to multilayer neural networks. As a result, we develop a strategy that mitigates sensitivity to the embedding complexity, and empirically achieves performance on par with or better than the best layer-dependent complexity tradeoff.
Flexible Modeling of Diversity with Strongly Log-Concave Distributions
Jun 12, 2019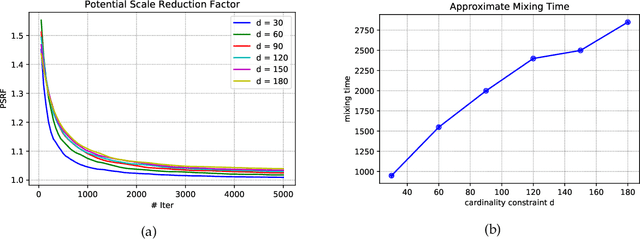
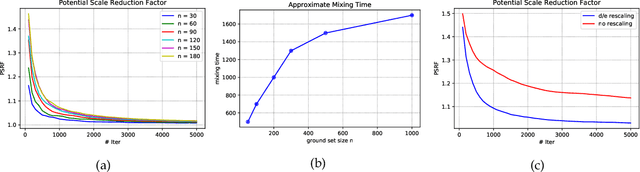
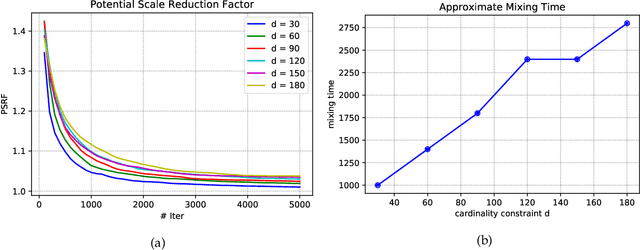
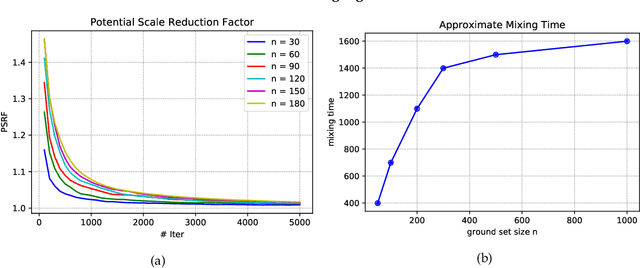
Strongly log-concave (SLC) distributions are a rich class of discrete probability distributions over subsets of some ground set. They are strictly more general than strongly Rayleigh (SR) distributions such as the well-known determinantal point process. While SR distributions offer elegant models of diversity, they lack an easy control over how they express diversity. We propose SLC as the right extension of SR that enables easier, more intuitive control over diversity, illustrating this via examples of practical importance. We develop two fundamental tools needed to apply SLC distributions to learning and inference: sampling and mode finding. For sampling we develop an MCMC sampler and give theoretical mixing time bounds. For mode finding, we establish a weak log-submodularity property for SLC functions and derive optimization guarantees for a distorted greedy algorithm.
Are Girls Neko or Shōjo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization
Jun 05, 2019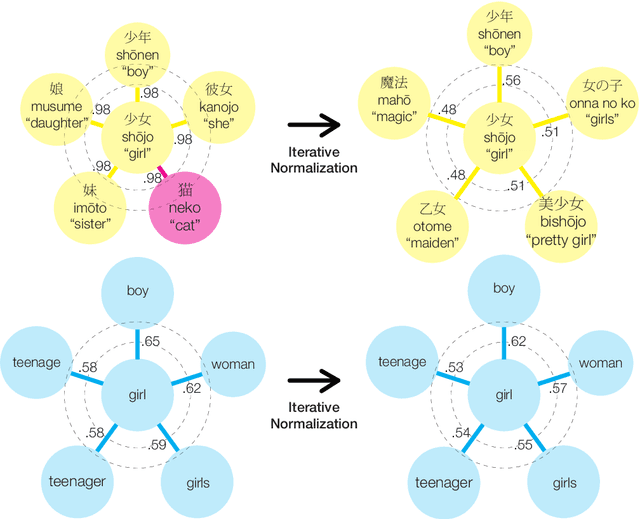
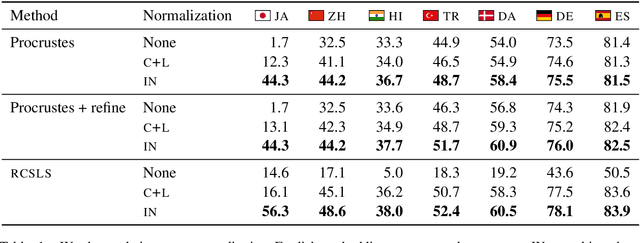
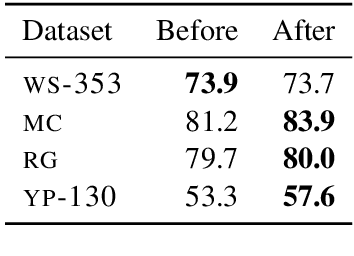
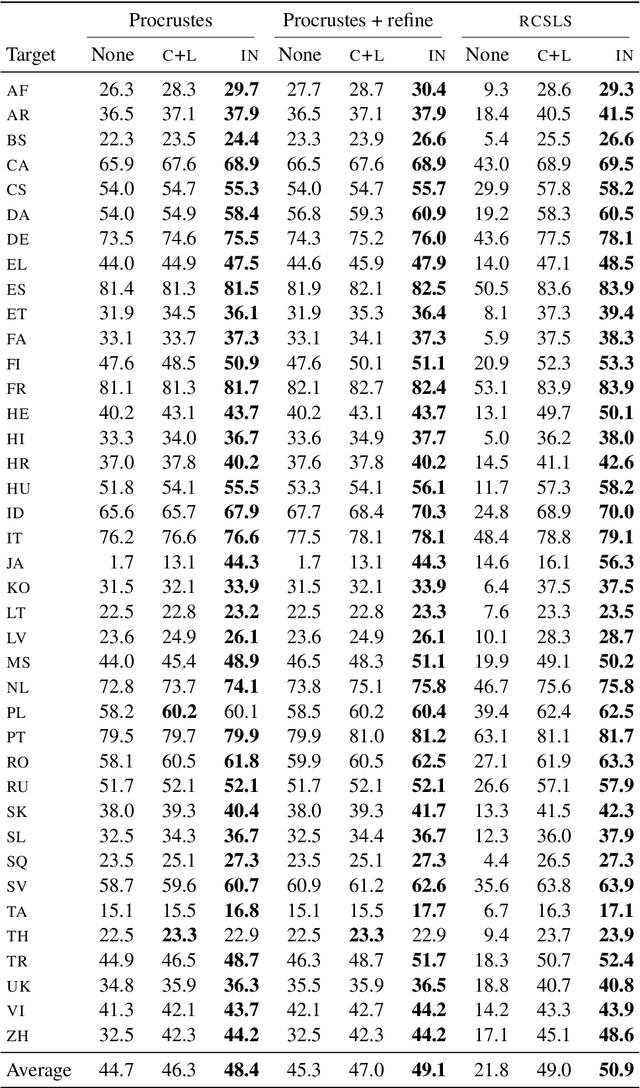
Cross-lingual word embeddings (CLWE) underlie many multilingual natural language processing systems, often through orthogonal transformations of pre-trained monolingual embeddings. However, orthogonal mapping only works on language pairs whose embeddings are naturally isomorphic. For non-isomorphic pairs, our method (Iterative Normalization) transforms monolingual embeddings to make orthogonal alignment easier by simultaneously enforcing that (1) individual word vectors are unit length, and (2) each language's average vector is zero. Iterative Normalization consistently improves word translation accuracy of three CLWE methods, with the largest improvement observed on English-Japanese (from 2% to 44% test accuracy).
What Can Neural Networks Reason About?
May 31, 2019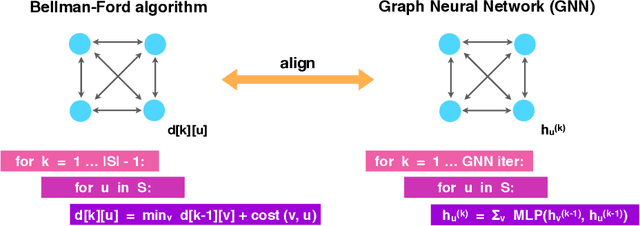
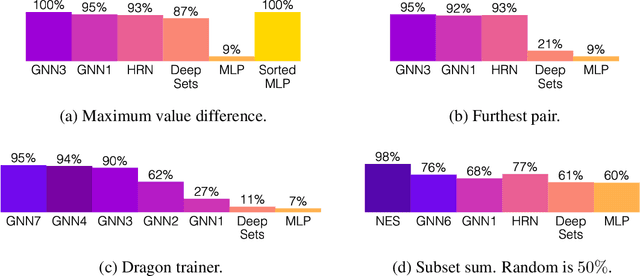
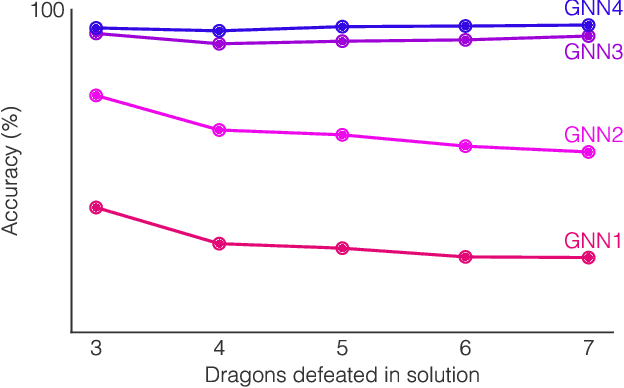
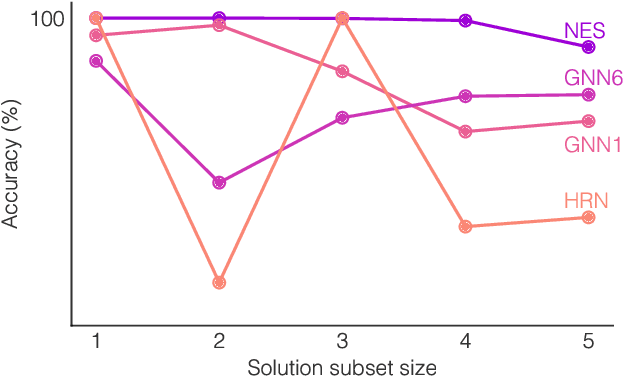
Neural networks have successfully been applied to solving reasoning tasks, ranging from learning simple concepts like "close to", to intricate questions whose reasoning procedures resemble algorithms. Empirically, not all network structures work equally well for reasoning. For example, Graph Neural Networks have achieved impressive empirical results, while less structured neural networks may fail to learn to reason. Theoretically, there is currently limited understanding of the interplay between reasoning tasks and network learning. In this paper, we develop a framework to characterize which tasks a neural network can learn well, by studying how well its structure aligns with the algorithmic structure of the relevant reasoning procedure. This suggests that Graph Neural Networks can learn dynamic programming, a powerful algorithmic strategy that solves a broad class of reasoning problems, such as relational question answering, sorting, intuitive physics, and shortest paths. Our perspective also implies strategies to design neural architectures for complex reasoning. On several abstract reasoning tasks, we see empirically that our theory aligns well with practice.
Minimizing approximately submodular functions
May 29, 2019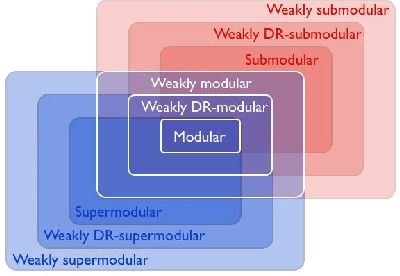
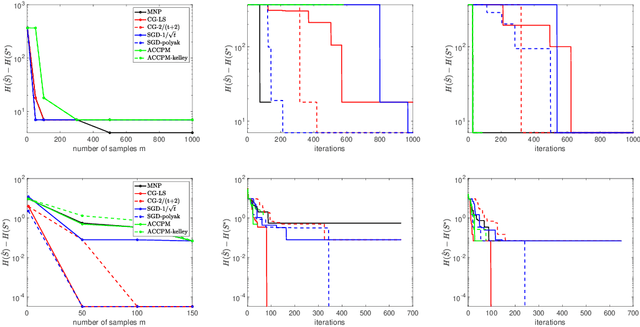
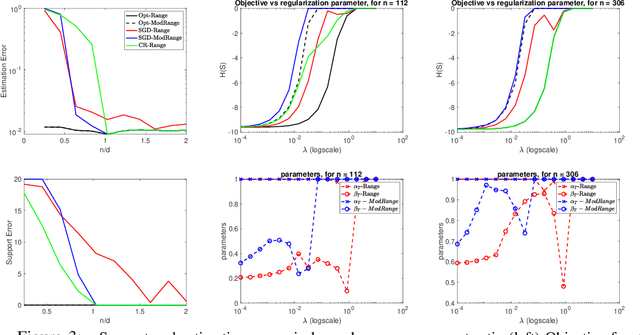
The problem of minimizing a submodular function is well studied; several polynomial-time algorithms have been developed to solve it exactly or up to arbitrary accuracy. However, in many applications, the objective functions are not exactly submodular. In this paper, we show that a classical algorithm used for submodular minimization performs well even for a class of non-submodular functions, namely weakly DR-submodular functions. We provide the first approximation guarantee for non-submodular minimization. This broadly expands the range of applications of submodular minimization techniques.
Distributionally Robust Optimization and Generalization in Kernel Methods
May 27, 2019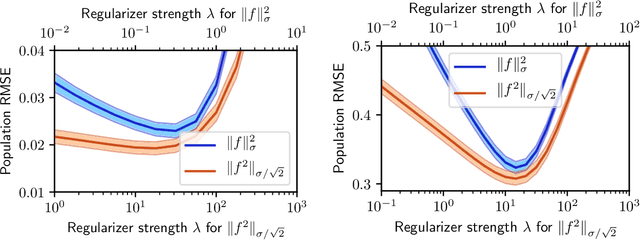
Distributionally robust optimization (DRO) has attracted attention in machine learning due to its connections to regularization, generalization, and robustness. Existing work has considered uncertainty sets based on phi-divergences and Wasserstein distances, each of which have drawbacks. In this paper, we study DRO with uncertainty sets measured via maximum mean discrepancy (MMD). We show that MMD DRO is roughly equivalent to regularization by the Hilbert norm and, as a byproduct, reveal deep connections to classic results in statistical learning. In particular, we obtain an alternative proof of a generalization bound for Gaussian kernel ridge regression via a DRO lense. The proof also suggests a new regularizer. Our results apply beyond kernel methods: we derive a generically applicable approximation of MMD DRO, and show that it generalizes recent work on variance-based regularization.
Learning Generative Models across Incomparable Spaces
May 15, 2019

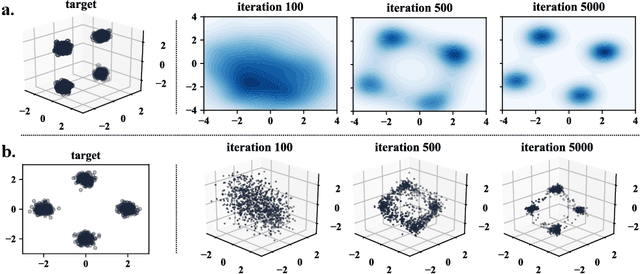

Generative Adversarial Networks have shown remarkable success in learning a distribution that faithfully recovers a reference distribution in its entirety. However, in some cases, we may want to only learn some aspects (e.g., cluster or manifold structure), while modifying others (e.g., style, orientation or dimension). In this work, we propose an approach to learn generative models across such incomparable spaces, and demonstrate how to steer the learned distribution towards target properties. A key component of our model is the Gromov-Wasserstein distance, a notion of discrepancy that compares distributions relationally rather than absolutely. While this framework subsumes current generative models in identically reproducing distributions, its inherent flexibility allows application to tasks in manifold learning, relational learning and cross-domain learning.
* International Conference on Machine Learning (ICML)
Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks
Dec 31, 2018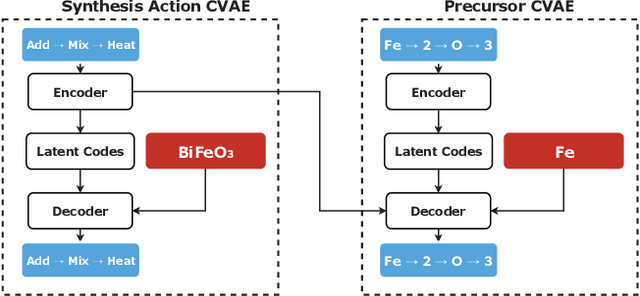
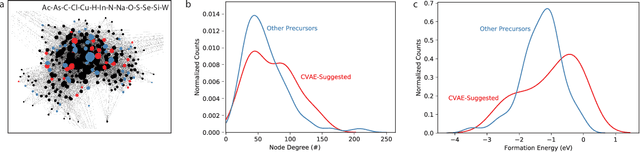
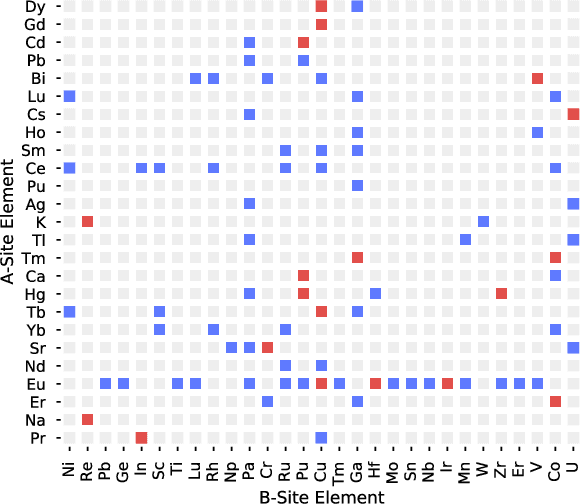

Leveraging new data sources is a key step in accelerating the pace of materials design and discovery. To complement the strides in synthesis planning driven by historical, experimental, and computed data, we present an automated method for connecting scientific literature to synthesis insights. Starting from natural language text, we apply word embeddings from language models, which are fed into a named entity recognition model, upon which a conditional variational autoencoder is trained to generate syntheses for arbitrary materials. We show the potential of this technique by predicting precursors for two perovskite materials, using only training data published over a decade prior to their first reported syntheses. We demonstrate that the model learns representations of materials corresponding to synthesis-related properties, and that the model's behavior complements existing thermodynamic knowledge. Finally, we apply the model to perform synthesizability screening for proposed novel perovskite compounds.
Adversarially Robust Optimization with Gaussian Processes
Nov 01, 2018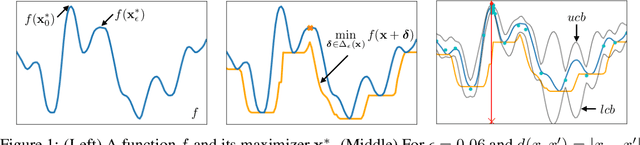
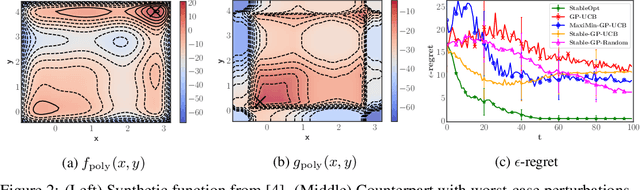
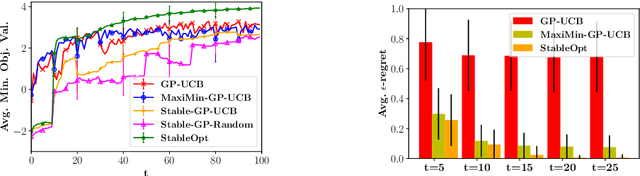
In this paper, we consider the problem of Gaussian process (GP) optimization with an added robustness requirement: The returned point may be perturbed by an adversary, and we require the function value to remain as high as possible even after this perturbation. This problem is motivated by settings in which the underlying functions during optimization and implementation stages are different, or when one is interested in finding an entire region of good inputs rather than only a single point. We show that standard GP optimization algorithms do not exhibit the desired robustness properties, and provide a novel confidence-bound based algorithm StableOpt for this purpose. We rigorously establish the required number of samples for StableOpt to find a near-optimal point, and we complement this guarantee with an algorithm-independent lower bound. We experimentally demonstrate several potential applications of interest using real-world data sets, and we show that StableOpt consistently succeeds in finding a stable maximizer where several baseline methods fail.
How Powerful are Graph Neural Networks?
Oct 01, 2018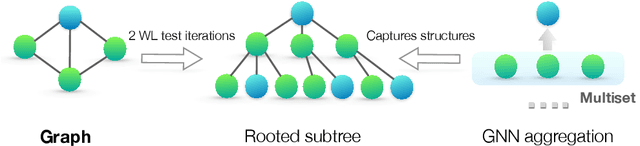
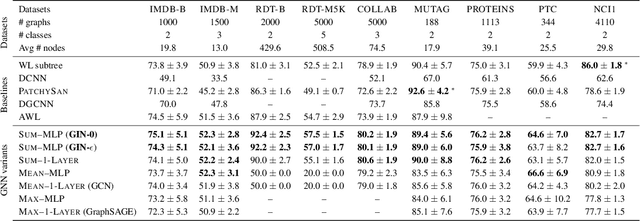


Graph Neural Networks (GNNs) for representation learning of graphs broadly follow a neighborhood aggregation framework, where the representation vector of a node is computed by recursively aggregating and transforming feature vectors of its neighboring nodes. Many GNN variants have been proposed and have achieved state-of-the-art results on both node and graph classification tasks. However, despite GNNs revolutionizing graph representation learning, there is limited understanding of their representational properties and limitations. Here, we present a theoretical framework for analyzing the expressive power of GNNs in capturing different graph structures. Our results characterize the discriminative power of popular GNN variants, such as Graph Convolutional Networks and GraphSAGE, and show that they cannot learn to distinguish certain simple graph structures. We then develop a simple architecture that is provably the most expressive among the class of GNNs and is as powerful as the Weisfeiler-Lehman graph isomorphism test. We empirically validate our theoretical findings on a number of graph classification benchmarks, and demonstrate that our model achieves state-of-the-art performance.