 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Framework for Conformal Fairness
May 22, 2025



Conformal Prediction (CP) is a popular method for uncertainty quantification with machine learning models. While conformal prediction provides probabilistic guarantees regarding the coverage of the true label, these guarantees are agnostic to the presence of sensitive attributes within the dataset. In this work, we formalize \textit{Conformal Fairness}, a notion of fairness using conformal predictors, and provide a theoretically well-founded algorithm and associated framework to control for the gaps in coverage between different sensitive groups. Our framework leverages the exchangeability assumption (implicit to CP) rather than the typical IID assumption, allowing us to apply the notion of Conformal Fairness to data types and tasks that are not IID, such as graph data. Experiments were conducted on graph and tabular datasets to demonstrate that the algorithm can control fairness-related gaps in addition to coverage aligned with theoretical expectations.
Graph Sparsification for Enhanced Conformal Prediction in Graph Neural Networks
Oct 28, 2024



Conformal Prediction is a robust framework that ensures reliable coverage across machine learning tasks. Although recent studies have applied conformal prediction to graph neural networks, they have largely emphasized post-hoc prediction set generation. Improving conformal prediction during the training stage remains unaddressed. In this work, we tackle this challenge from a denoising perspective by introducing SparGCP, which incorporates graph sparsification and a conformal prediction-specific objective into GNN training. SparGCP employs a parameterized graph sparsification module to filter out task-irrelevant edges, thereby improving conformal prediction efficiency. Extensive experiments on real-world graph datasets demonstrate that SparGCP outperforms existing methods, reducing prediction set sizes by an average of 32\% and scaling seamlessly to large networks on commodity GPUs.
Benchmarking Graph Conformal Prediction: Empirical Analysis, Scalability, and Theoretical Insights
Sep 26, 2024

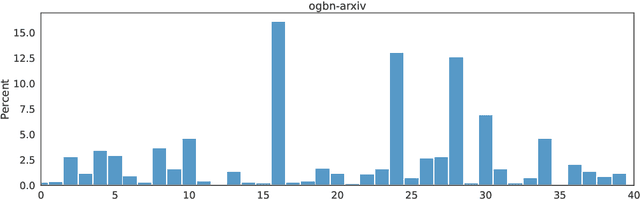

Conformal prediction has become increasingly popular for quantifying the uncertainty associated with machine learning models. Recent work in graph uncertainty quantification has built upon this approach for conformal graph prediction. The nascent nature of these explorations has led to conflicting choices for implementations, baselines, and method evaluation. In this work, we analyze the design choices made in the literature and discuss the tradeoffs associated with existing methods. Building on the existing implementations for existing methods, we introduce techniques to scale existing methods to large-scale graph datasets without sacrificing performance. Our theoretical and empirical results justify our recommendations for future scholarship in graph conformal prediction.