 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Strict Identity Mappings in Deep Residual Networks
May 16, 2018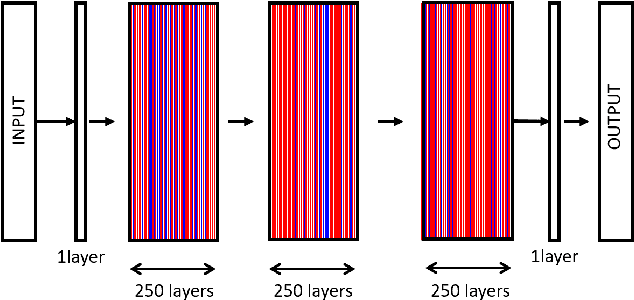
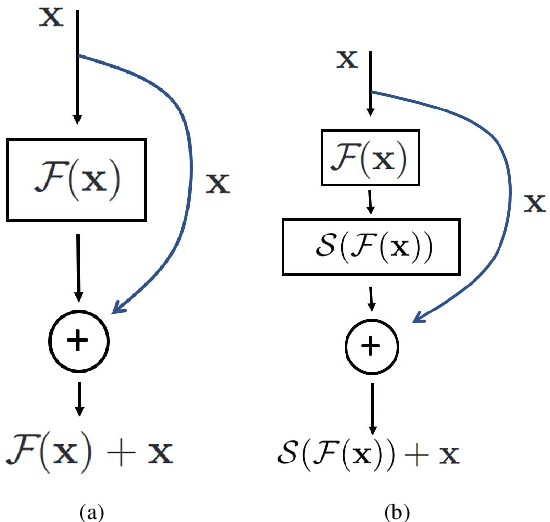
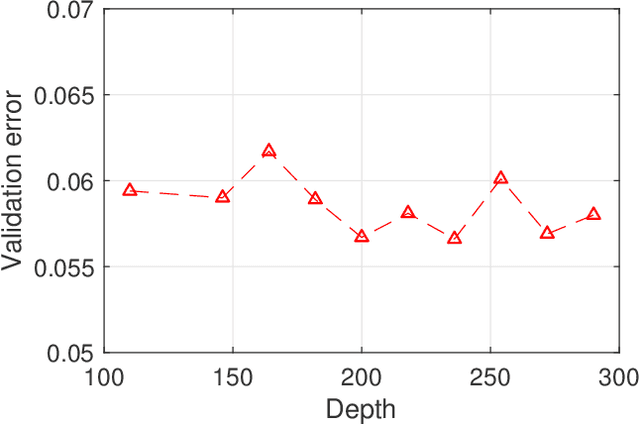
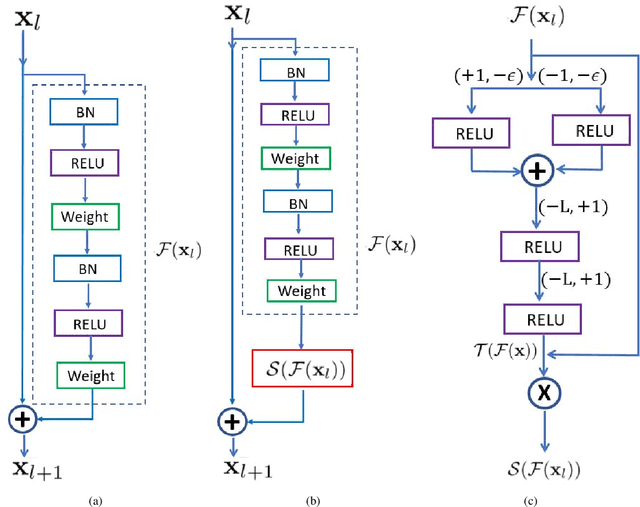
A family of super deep networks, referred to as residual networks or ResNet, achieved record-beating performance in various visual tasks such as image recognition, object detection, and semantic segmentation. The ability to train very deep networks naturally pushed the researchers to use enormous resources to achieve the best performance. Consequently, in many applications super deep residual networks were employed for just a marginal improvement in performance. In this paper, we propose epsilon-ResNet that allows us to automatically discard redundant layers, which produces responses that are smaller than a threshold epsilon, with a marginal or no loss in performance. The epsilon-ResNet architecture can be achieved using a few additional rectified linear units in the original ResNet. Our method does not use any additional variables nor numerous trials like other hyper-parameter optimization techniques. The layer selection is achieved using a single training process and the evaluation is performed on CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets. In some instances, we achieve about 80% reduction in the number of parameters.
Analytical Modeling of Vanishing Points and Curves in Catadioptric Cameras
Apr 25, 2018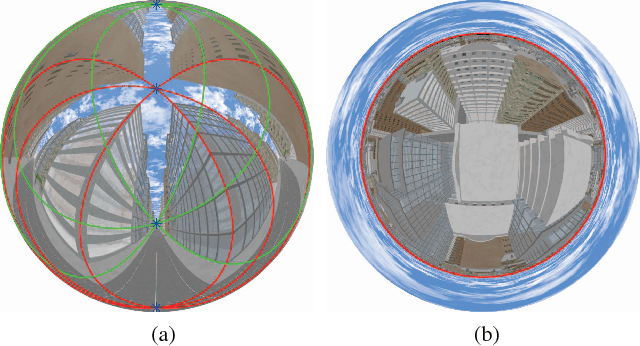
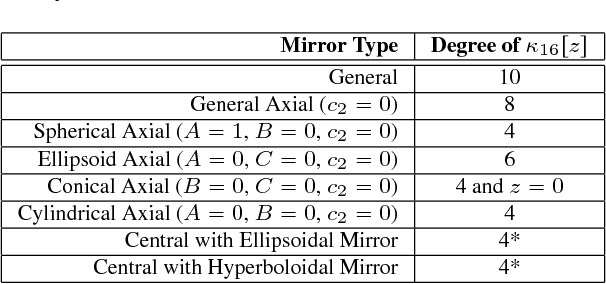
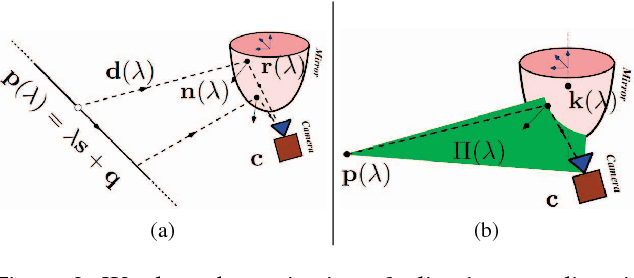
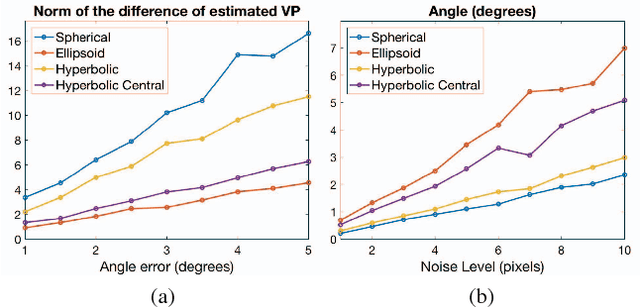
Vanishing points and vanishing lines are classical geometrical concepts in perspective cameras that have a lineage dating back to 3 centuries. A vanishing point is a point on the image plane where parallel lines in 3D space appear to converge, whereas a vanishing line passes through 2 or more vanishing points. While such concepts are simple and intuitive in perspective cameras, their counterparts in catadioptric cameras (obtained using mirrors and lenses) are more involved. For example, lines in the 3D space map to higher degree curves in catadioptric cameras. The projection of a set of 3D parallel lines converges on a single point in perspective images, whereas they converge to more than one point in catadioptric cameras. To the best of our knowledge, we are not aware of any systematic development of analytical models for vanishing points and vanishing curves in different types of catadioptric cameras. In this paper, we derive parametric equations for vanishing points and vanishing curves using the calibration parameters, mirror shape coefficients, and direction vectors of parallel lines in 3D space. We show compelling experimental results on vanishing point estimation and absolute pose estimation for a wide range of catadioptric cameras in both simulations and real experiments.
Class Subset Selection for Transfer Learning using Submodularity
Mar 30, 2018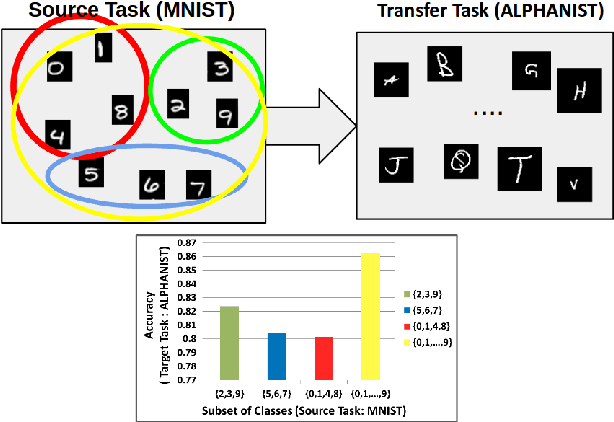
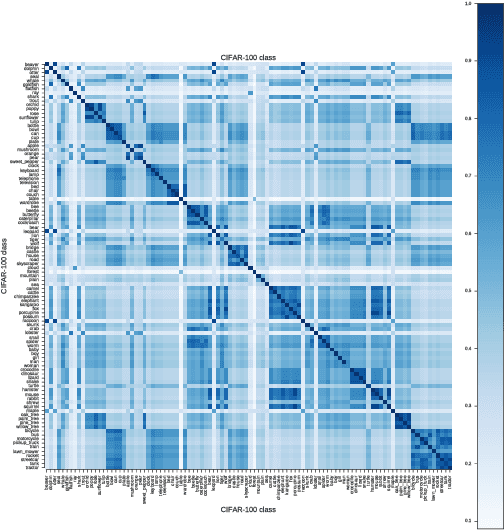

In recent years, it is common practice to extract fully-connected layer (fc) features that were learned while performing image classification on a source dataset, such as ImageNet, and apply them generally to a wide range of other tasks. The general usefulness of some large training datasets for transfer learning is not yet well understood, and raises a number of questions. For example, in the context of transfer learning, what is the role of a specific class in the source dataset, and how is the transferability of fc features affected when they are trained using various subsets of the set of all classes in the source dataset? In this paper, we address the question of how to select an optimal subset of the set of classes, subject to a budget constraint, that will more likely generate good features for other tasks. To accomplish this, we use a submodular set function to model the accuracy achievable on a new task when the features have been learned on a given subset of classes of the source dataset. An optimal subset is identified as the set that maximizes this submodular function. The maximization can be accomplished using an efficient greedy algorithm that comes with guarantees on the optimality of the solution. We empirically validate our submodular model by successfully identifying subsets of classes that produce good features for new tasks.
Submodular Function Maximization for Group Elevator Scheduling
Jun 28, 2017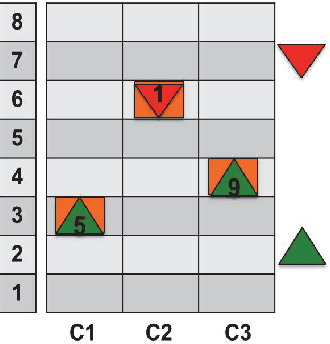
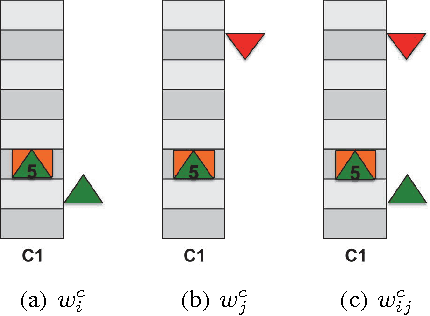
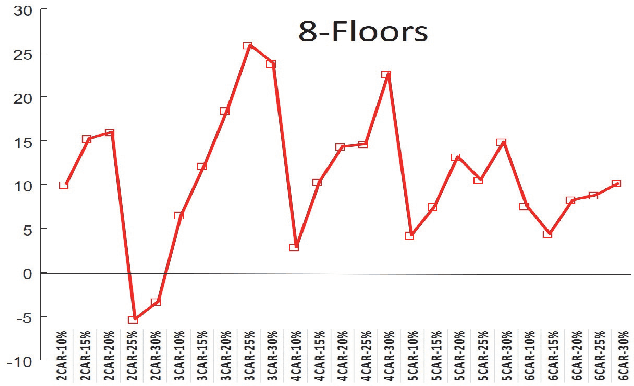
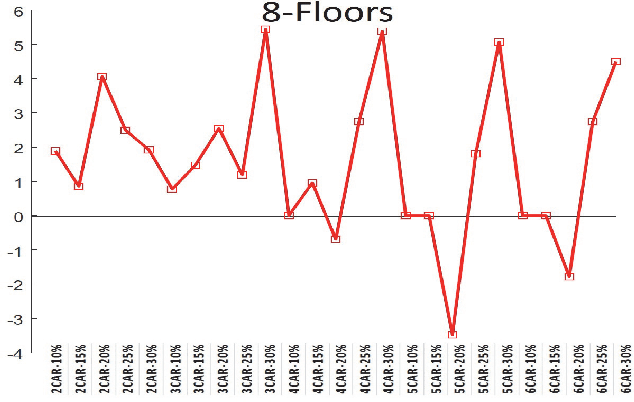
We propose a novel approach for group elevator scheduling by formulating it as the maximization of submodular function under a matroid constraint. In particular, we propose to model the total waiting time of passengers using a quadratic Boolean function. The unary and pairwise terms in the function denote the waiting time for single and pairwise allocation of passengers to elevators, respectively. We show that this objective function is submodular. The matroid constraints ensure that every passenger is allocated to exactly one elevator. We use a greedy algorithm to maximize the submodular objective function, and derive provable guarantees on the optimality of the solution. We tested our algorithm using Elevate 8, a commercial-grade elevator simulator that allows simulation with a wide range of elevator settings. We achieve significant improvement over the existing algorithms.
CASENet: Deep Category-Aware Semantic Edge Detection
May 27, 2017
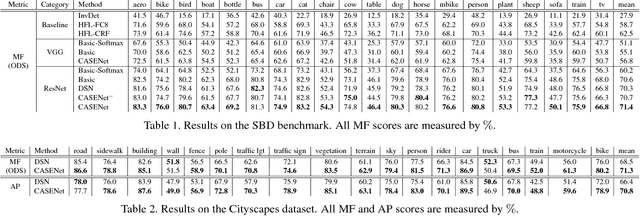

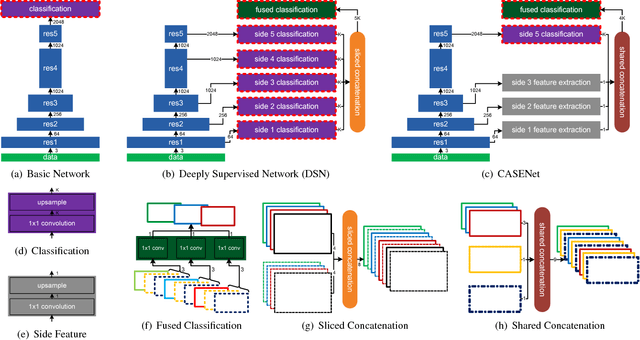
Boundary and edge cues are highly beneficial in improving a wide variety of vision tasks such as semantic segmentation, object recognition, stereo, and object proposal generation. Recently, the problem of edge detection has been revisited and significant progress has been made with deep learning. While classical edge detection is a challenging binary problem in itself, the category-aware semantic edge detection by nature is an even more challenging multi-label problem. We model the problem such that each edge pixel can be associated with more than one class as they appear in contours or junctions belonging to two or more semantic classes. To this end, we propose a novel end-to-end deep semantic edge learning architecture based on ResNet and a new skip-layer architecture where category-wise edge activations at the top convolution layer share and are fused with the same set of bottom layer features. We then propose a multi-label loss function to supervise the fused activations. We show that our proposed architecture benefits this problem with better performance, and we outperform the current state-of-the-art semantic edge detection methods by a large margin on standard data sets such as SBD and Cityscapes.
Efficient Minimization of Higher Order Submodular Functions using Monotonic Boolean Functions
Jan 23, 2017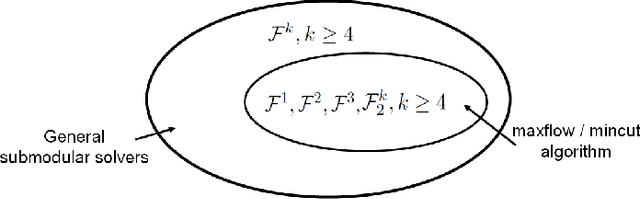
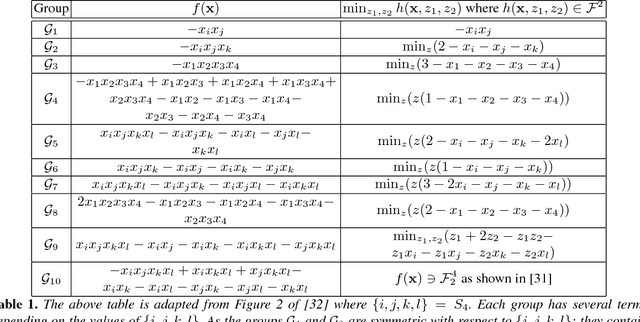

Submodular function minimization is a key problem in a wide variety of applications in machine learning, economics, game theory, computer vision, and many others. The general solver has a complexity of $O(n^3 \log^2 n . E +n^4 {\log}^{O(1)} n)$ where $E$ is the time required to evaluate the function and $n$ is the number of variables \cite{Lee2015}. On the other hand, many computer vision and machine learning problems are defined over special subclasses of submodular functions that can be written as the sum of many submodular cost functions defined over cliques containing few variables. In such functions, the pseudo-Boolean (or polynomial) representation \cite{BorosH02} of these subclasses are of degree (or order, or clique size) $k$ where $k \ll n$. In this work, we develop efficient algorithms for the minimization of this useful subclass of submodular functions. To do this, we define novel mapping that transform submodular functions of order $k$ into quadratic ones. The underlying idea is to use auxiliary variables to model the higher order terms and the transformation is found using a carefully constructed linear program. In particular, we model the auxiliary variables as monotonic Boolean functions, allowing us to obtain a compact transformation using as few auxiliary variables as possible.
High-Performance and Tunable Stereo Reconstruction
Feb 17, 2016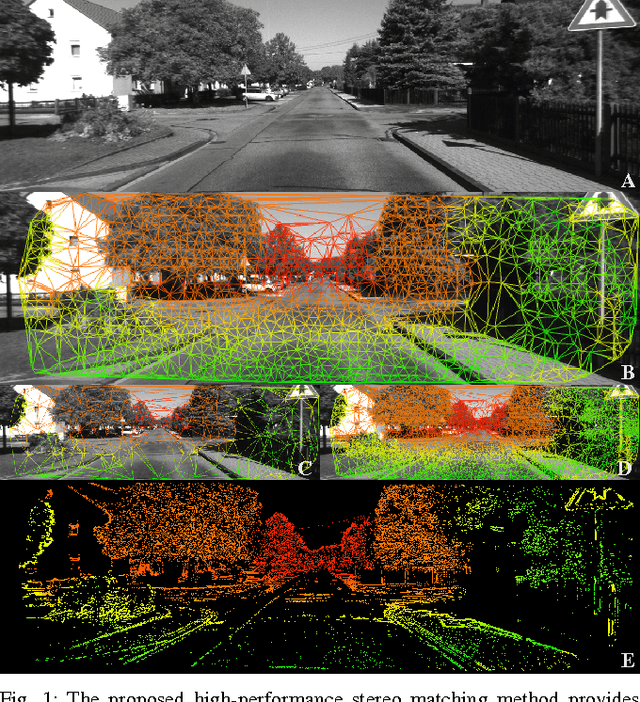



Traditional stereo algorithms have focused their efforts on reconstruction quality and have largely avoided prioritizing for run time performance. Robots, on the other hand, require quick maneuverability and effective computation to observe its immediate environment and perform tasks within it. In this work, we propose a high-performance and tunable stereo disparity estimation method, with a peak frame-rate of 120Hz (VGA resolution, on a single CPU-thread), that can potentially enable robots to quickly reconstruct their immediate surroundings and maneuver at high-speeds. Our key contribution is a disparity estimation algorithm that iteratively approximates the scene depth via a piece-wise planar mesh from stereo imagery, with a fast depth validation step for semi-dense reconstruction. The mesh is initially seeded with sparsely matched keypoints, and is recursively tessellated and refined as needed (via a resampling stage), to provide the desired stereo disparity accuracy. The inherent simplicity and speed of our approach, with the ability to tune it to a desired reconstruction quality and runtime performance makes it a compelling solution for applications in high-speed vehicles.
Layered Interpretation of Street View Images
Jul 29, 2015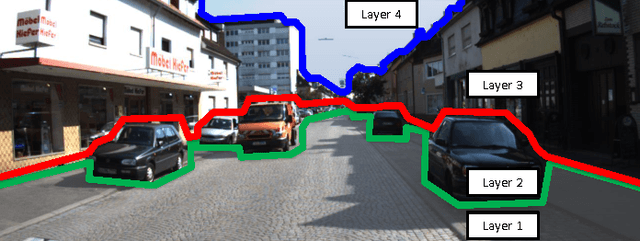
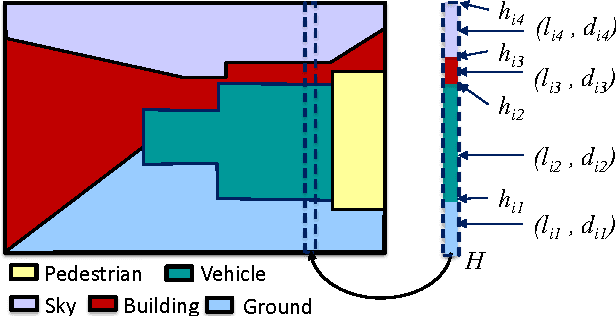

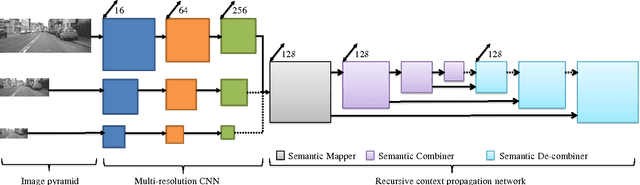
We propose a layered street view model to encode both depth and semantic information on street view images for autonomous driving. Recently, stixels, stix-mantics, and tiered scene labeling methods have been proposed to model street view images. We propose a 4-layer street view model, a compact representation over the recently proposed stix-mantics model. Our layers encode semantic classes like ground, pedestrians, vehicles, buildings, and sky in addition to the depths. The only input to our algorithm is a pair of stereo images. We use a deep neural network to extract the appearance features for semantic classes. We use a simple and an efficient inference algorithm to jointly estimate both semantic classes and layered depth values. Our method outperforms other competing approaches in Daimler urban scene segmentation dataset. Our algorithm is massively parallelizable, allowing a GPU implementation with a processing speed about 9 fps.