 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalent and Approximate Transformations of Deep Neural Networks
May 27, 2019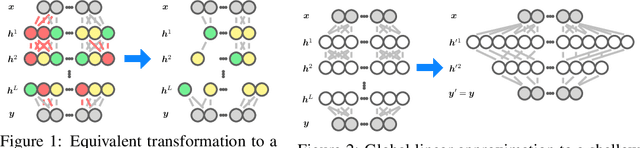
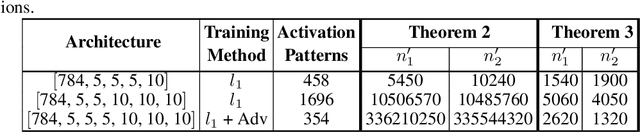
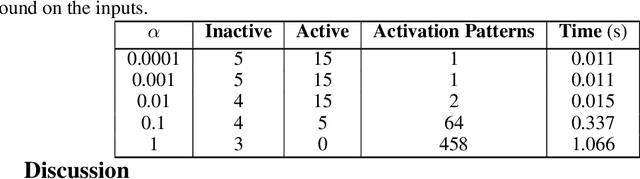
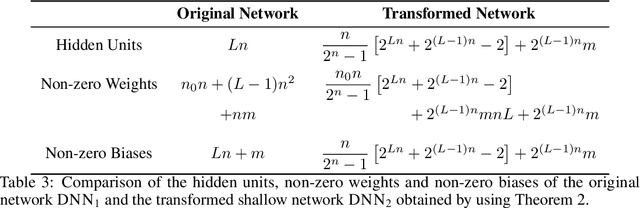
Two networks are equivalent if they produce the same output for any given input. In this paper, we study the possibility of transforming a deep neural network to another network with a different number of units or layers, which can be either equivalent, a local exact approximation, or a global linear approximation of the original network. On the practical side, we show that certain rectified linear units (ReLUs) can be safely removed from a network if they are always active or inactive for any valid input. If we only need an equivalent network for a smaller domain, then more units can be removed and some layers collapsed. On the theoretical side, we constructively show that for any feed-forward ReLU network, there exists a global linear approximation to a 2-hidden-layer shallow network with a fixed number of units. This result is a balance between the increasing number of units for arbitrary approximation with a single layer and the known upper bound of $\lceil log(n_0+1)\rceil +1$ layers for exact representation, where $n_0$ is the input dimension. While the transformed network may require an exponential number of units to capture the activation patterns of the original network, we show that it can be made substantially smaller by only accounting for the patterns that define linear regions. Based on experiments with ReLU networks on the MNIST dataset, we found that $l_1$-regularization and adversarial training reduces the number of linear regions significantly as the number of stable units increases due to weight sparsity. Therefore, we can also intentionally train ReLU networks to allow for effective loss-less compression and approximation.
Minimal Solvers for Mini-Loop Closures in 3D Multi-Scan Alignment
Apr 08, 2019


3D scan registration is a classical, yet a highly useful problem in the context of 3D sensors such as Kinect and Velodyne. While there are several existing methods, the techniques are usually incremental where adjacent scans are registered first to obtain the initial poses, followed by motion averaging and bundle-adjustment refinement. In this paper, we take a different approach and develop minimal solvers for jointly computing the initial poses of cameras in small loops such as 3-, 4-, and 5-cycles. Note that the classical registration of 2 scans can be done using a minimum of 3 point matches to compute 6 degrees of relative motion. On the other hand, to jointly compute the 3D registrations in n-cycles, we take 2 point matches between the first n-1 consecutive pairs (i.e., Scan 1 & Scan 2, ... , and Scan n-1 & Scan n) and 1 or 2 point matches between Scan 1 and Scan n. Overall, we use 5, 7, and 10 point matches for 3-, 4-, and 5-cycles, and recover 12, 18, and 24 degrees of transformation variables, respectively. Using simulations and real-data we show that the 3D registration using mini n-cycles are computationally efficient, and can provide alternate and better initial poses compared to standard pairwise methods.
* 10 pages, 5 figures, 5 tables
3DRegNet: A Deep Neural Network for 3D Point Registration
Apr 02, 2019
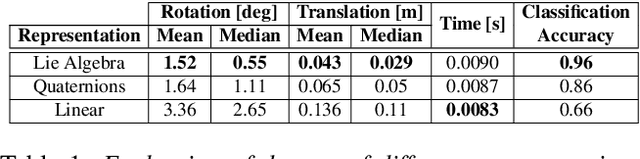
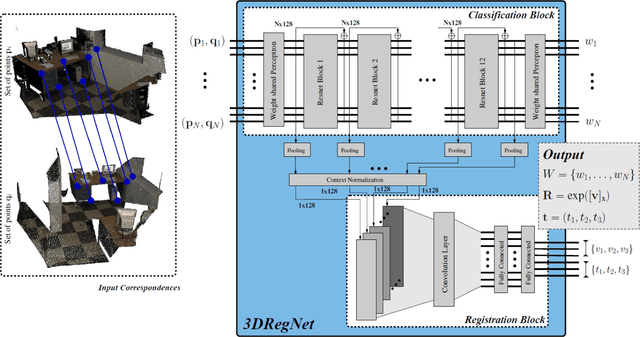

We present 3DRegNet, a deep learning algorithm for the registration of 3D scans. With the recent emergence of inexpensive 3D commodity sensors, it would be beneficial to develop a learning based 3D registration algorithm. Given a set of 3D point correspondences, we build a deep neural network using deep residual layers and convolutional layers to achieve two tasks: (1) classification of the point correspondences into correct/incorrect ones, and (2) regression of the motion parameters that can align the scans into a common reference frame. 3DRegNet has several advantages over classical methods. First, since 3DRegNet works on point correspondences and not on the original scans, our approach is significantly faster than many conventional approaches. Second, we show that the algorithm can be extended for multi-view scenarios, i.e., simultaneous handling of the registration for more than two scans. In contrast to pose regression networks that employ four variables to represent rotation using quaternions, we use Lie algebra to represent the rotation using only three variables. Extensive experiments on two challenging datasets (i.e. ICL-NUIM and SUN3D) demonstrate that we outperform other methods and achieve state-of-the-art results. The code will be made available.
Simultaneous Edge Alignment and Learning
Oct 26, 2018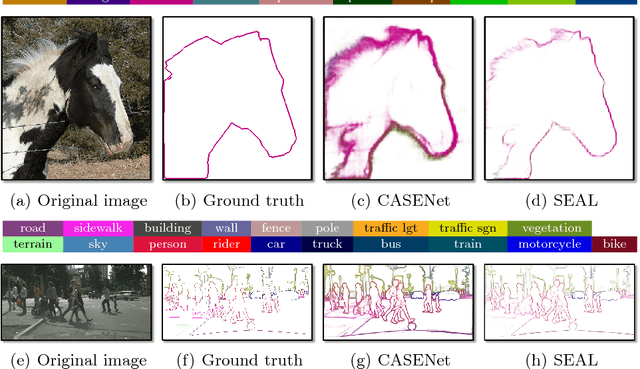



Edge detection is among the most fundamental vision problems for its role in perceptual grouping and its wide applications. Recent advances in representation learning have led to considerable improvements in this area. Many state of the art edge detection models are learned with fully convolutional networks (FCNs). However, FCN-based edge learning tends to be vulnerable to misaligned labels due to the delicate structure of edges. While such problem was considered in evaluation benchmarks, similar issue has not been explicitly addressed in general edge learning. In this paper, we show that label misalignment can cause considerably degraded edge learning quality, and address this issue by proposing a simultaneous edge alignment and learning framework. To this end, we formulate a probabilistic model where edge alignment is treated as latent variable optimization, and is learned end-to-end during network training. Experiments show several applications of this work, including improved edge detection with state of the art performance, and automatic refinement of noisy annotations.
Novel Single View Constraints for Manhattan 3D Line Reconstruction
Oct 08, 2018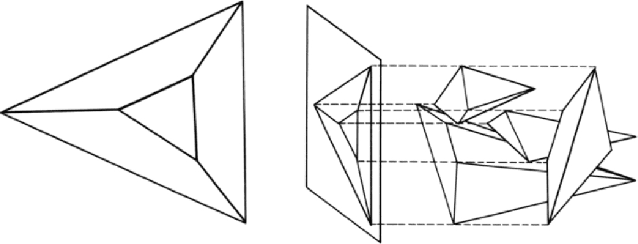

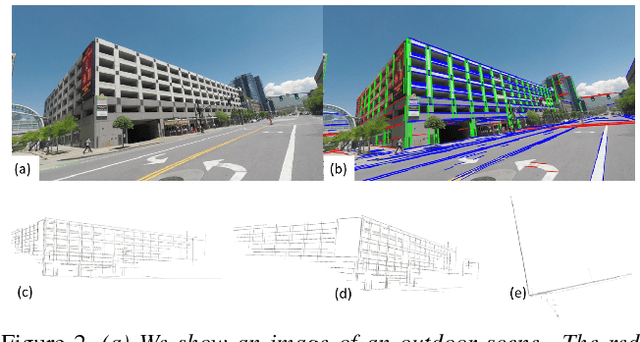
This paper proposes a novel and exact method to reconstruct line-based 3D structure from a single image using Manhattan world assumption. This problem is a distinctly unsolved problem because there can be multiple 3D reconstructions from a single image. Thus, we are often forced to look for priors like Manhattan world assumption and common scene structures. In addition to the standard orthogonality, perspective projection, and parallelism constraints, we investigate a few novel constraints based on the physical realizability of the 3D scene structure. We treat the line segments in the image to be part of a graph similar to straws and connectors game, where the goal is to back-project the line segments in 3D space and while ensuring that some of these 3D line segments connect with each other (i.e., truly intersect in 3D space) to form the 3D structure. We consider three sets of novel constraints while solving the reconstruction: (1) constraints on a series of Manhattan line intersections that form cycles, but are not all physically realizable, (2) constraints on true and false intersections in the case of nearby lines lying on the same Manhattan plane, and (3) constraints from the intersections on boundary and non-boundary line segments. The reconstruction is achieved using mixed integer linear programming (MILP), and we show compelling results on real images. Along with this paper, we will release a challenging Single View Line Reconstruction dataset with ground truth 3D line models for research purposes.
Empirical Bounds on Linear Regions of Deep Rectifier Networks
Oct 08, 2018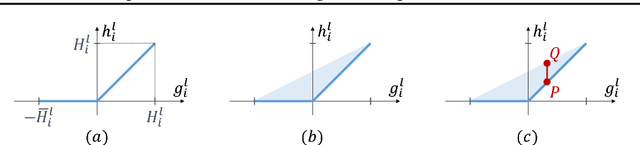
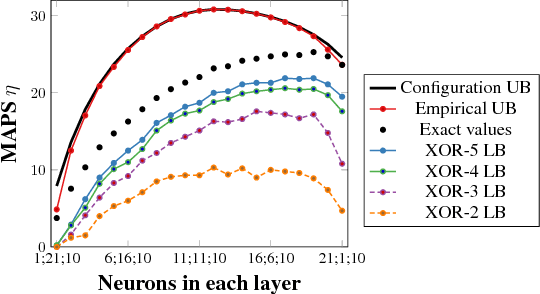
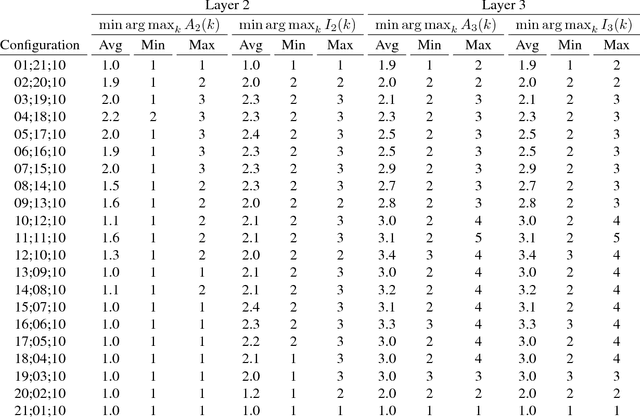
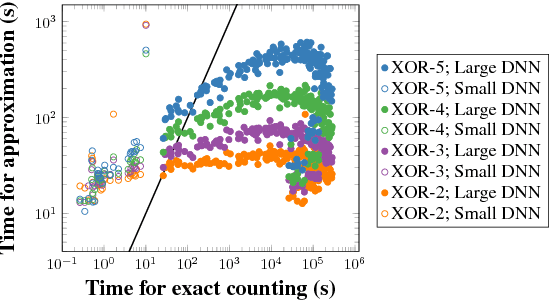
One form of characterizing the expressiveness of a piecewise linear neural network is by the number of linear regions, or pieces, of the function modeled. We have observed substantial progress in this topic through lower and upper bounds on the maximum number of linear regions and a counting procedure. However, these bounds only account for the dimensions of the network and the exact counting may take a prohibitive amount of time, therefore making it infeasible to benchmark the expressiveness of networks. In this work, we approximate the number of linear regions of specific rectifier networks with an algorithm for probabilistic lower bounds of mixed-integer linear sets. In addition, we present a tighter upper bound that leverages network coefficients. We test both on trained networks. The algorithm for probabilistic lower bounds is several orders of magnitude faster than exact counting and the values reach similar orders of magnitude, hence making our approach a viable method to compare the expressiveness of such networks. The refined upper bound is particularly stronger on networks with narrow layers.
Bounding and Counting Linear Regions of Deep Neural Networks
Sep 16, 2018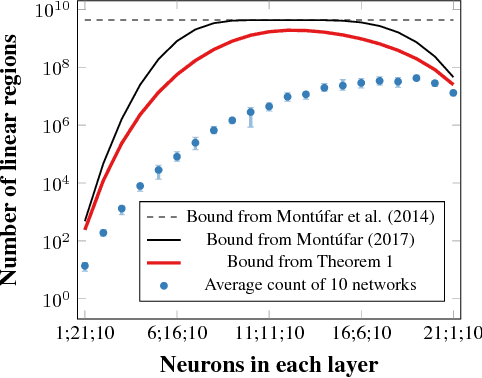

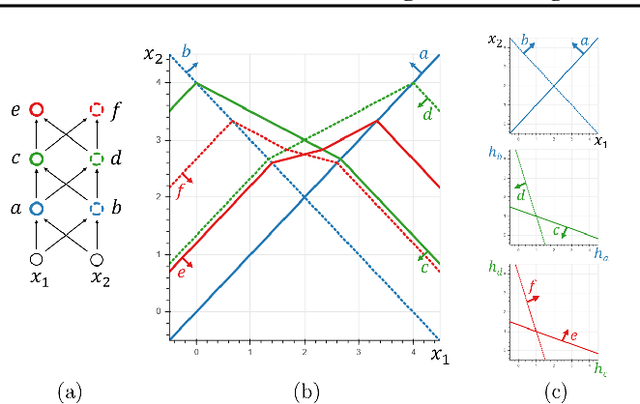
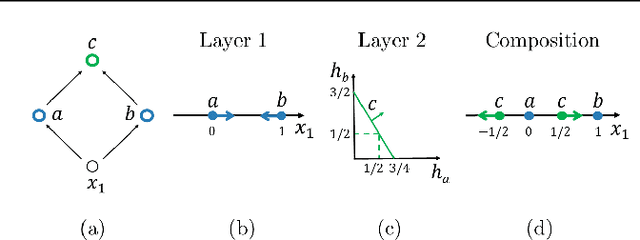
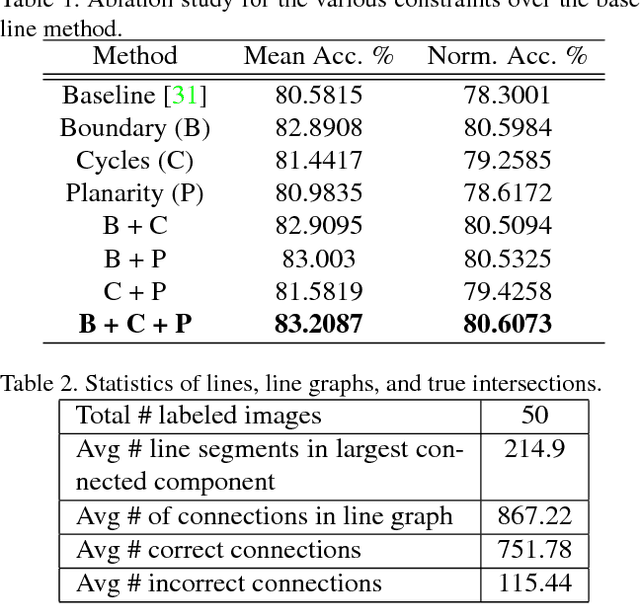
We investigate the complexity of deep neural networks (DNN) that represent piecewise linear (PWL) functions. In particular, we study the number of linear regions, i.e. pieces, that a PWL function represented by a DNN can attain, both theoretically and empirically. We present (i) tighter upper and lower bounds for the maximum number of linear regions on rectifier networks, which are exact for inputs of dimension one; (ii) a first upper bound for multi-layer maxout networks; and (iii) a first method to perform exact enumeration or counting of the number of regions by modeling the DNN with a mixed-integer linear formulation. These bounds come from leveraging the dimension of the space defining each linear region. The results also indicate that a deep rectifier network can only have more linear regions than every shallow counterpart with same number of neurons if that number exceeds the dimension of the input.
A Minimal Closed-Form Solution for Multi-Perspective Pose Estimation using Points and Lines
Jul 26, 2018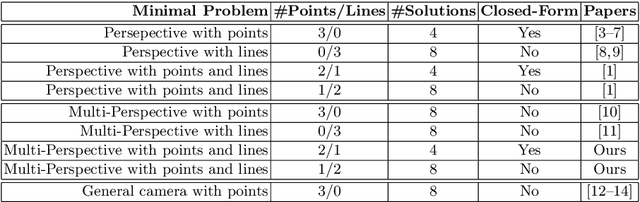
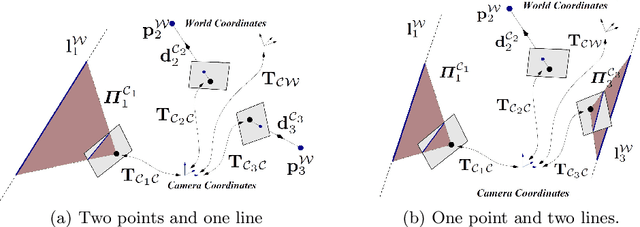

We propose a minimal solution for pose estimation using both points and lines for a multi-perspective camera. In this paper, we treat the multi-perspective camera as a collection of rigidly attached perspective cameras. These type of imaging devices are useful for several computer vision applications that require a large coverage such as surveillance, self-driving cars, and motion-capture studios. While prior methods have considered the cases using solely points or lines, the hybrid case involving both points and lines has not been solved for multi-perspective cameras. We present the solutions for two cases. In the first case, we are given 2D to 3D correspondences for two points and one line. In the later case, we are given 2D to 3D correspondences for one point and two lines. We show that the solution for the case of two points and one line can be formulated as a fourth degree equation. This is interesting because we can get a closed-form solution and thereby achieve high computational efficiency. The later case involving two lines and one point can be mapped to an eighth degree equation. We show simulations and real experiments to demonstrate the advantages and benefits over existing methods.
* 22 pages, 6 figures
VLASE: Vehicle Localization by Aggregating Semantic Edges
Jul 06, 2018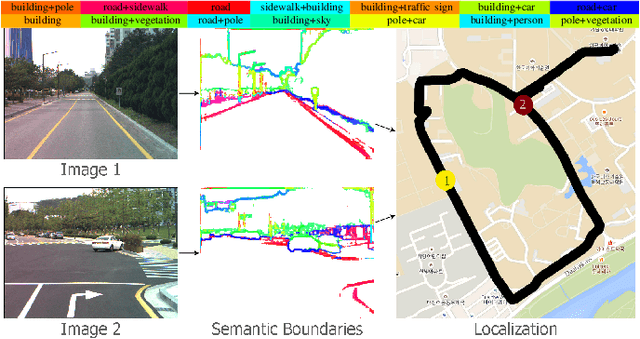
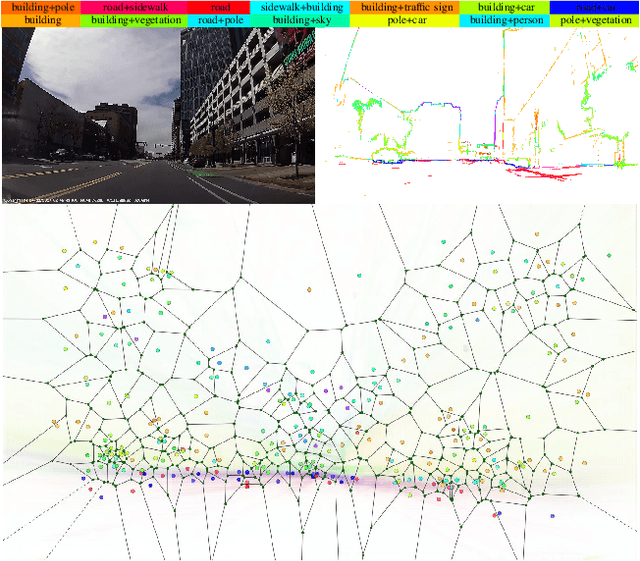
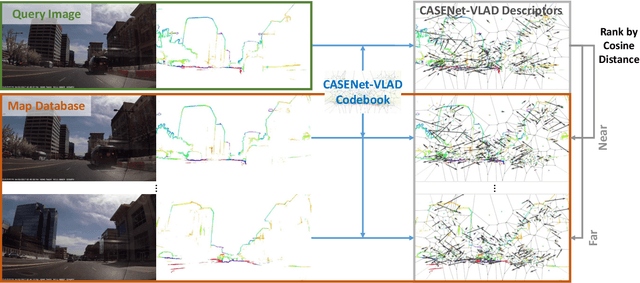
In this paper, we propose VLASE, a framework to use semantic edge features from images to achieve on-road localization. Semantic edge features denote edge contours that separate pairs of distinct objects such as building-sky, road- sidewalk, and building-ground. While prior work has shown promising results by utilizing the boundary between prominent classes such as sky and building using skylines, we generalize this approach to consider semantic edge features that arise from 19 different classes. Our localization algorithm is simple, yet very powerful. We extract semantic edge features using a recently introduced CASENet architecture and utilize VLAD framework to perform image retrieval. Our experiments show that we achieve improvement over some of the state-of-the-art localization algorithms such as SIFT-VLAD and its deep variant NetVLAD. We use ablation study to study the importance of different semantic classes and show that our unified approach achieves better performance compared to individual prominent features such as skylines.
How Could Polyhedral Theory Harness Deep Learning?
Jun 17, 2018The holy grail of deep learning is to come up with an automatic method to design optimal architectures for different applications. In other words, how can we effectively dimension and organize neurons along the network layers based on the computational resources, input size, and amount of training data? We outline promising research directions based on polyhedral theory and mixed-integer representability that may offer an analytical approach to this question, in contrast to the empirical techniques often employed.