 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Transferable Table Question Answering
Sep 15, 2021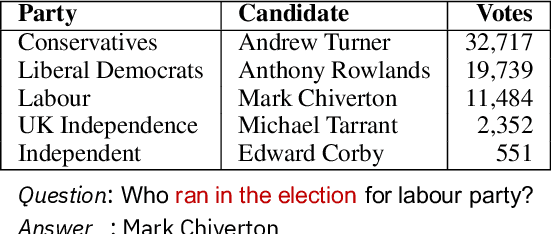
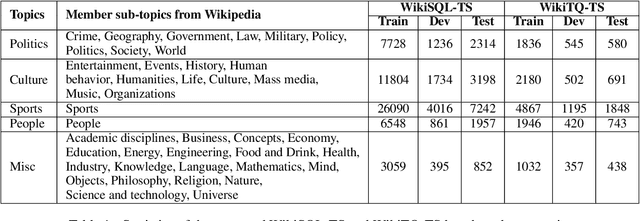
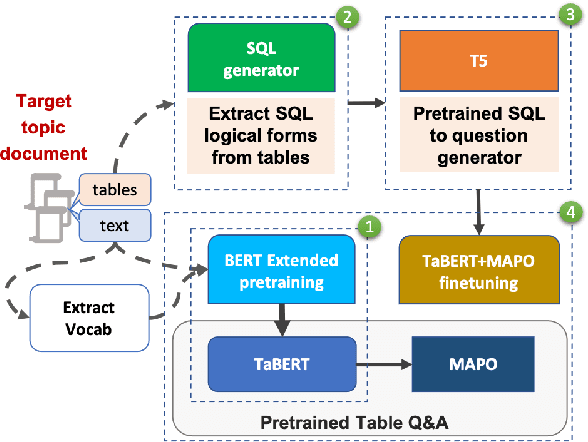
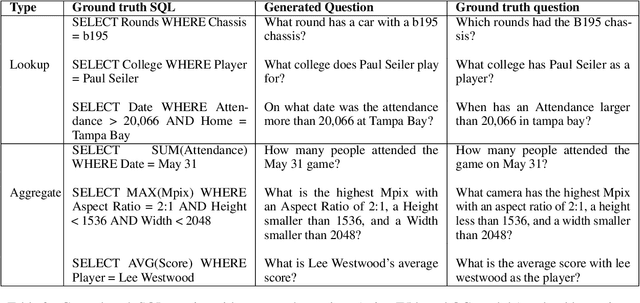
Weakly-supervised table question-answering(TableQA) models have achieved state-of-art performance by using pre-trained BERT transformer to jointly encoding a question and a table to produce structured query for the question. However, in practical settings TableQA systems are deployed over table corpora having topic and word distributions quite distinct from BERT's pretraining corpus. In this work we simulate the practical topic shift scenario by designing novel challenge benchmarks WikiSQL-TS and WikiTQ-TS, consisting of train-dev-test splits in five distinct topic groups, based on the popular WikiSQL and WikiTableQuestions datasets. We empirically show that, despite pre-training on large open-domain text, performance of models degrades significantly when they are evaluated on unseen topics. In response, we propose T3QA (Topic Transferable Table Question Answering) a pragmatic adaptation framework for TableQA comprising of: (1) topic-specific vocabulary injection into BERT, (2) a novel text-to-text transformer generator (such as T5, GPT2) based natural language question generation pipeline focused on generating topic specific training data, and (3) a logical form reranker. We show that T3QA provides a reasonably good baseline for our topic shift benchmarks. We believe our topic split benchmarks will lead to robust TableQA solutions that are better suited for practical deployment.
Integrating Transductive And Inductive Embeddings Improves Link Prediction Accuracy
Aug 23, 2021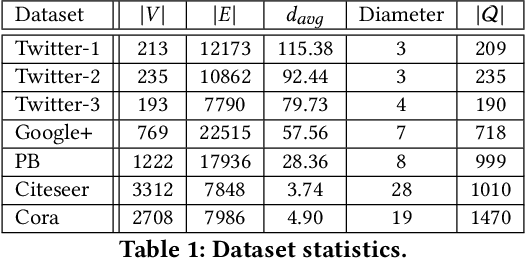
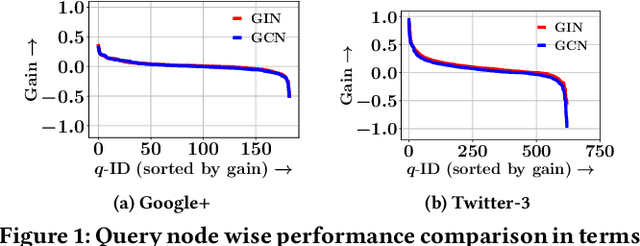
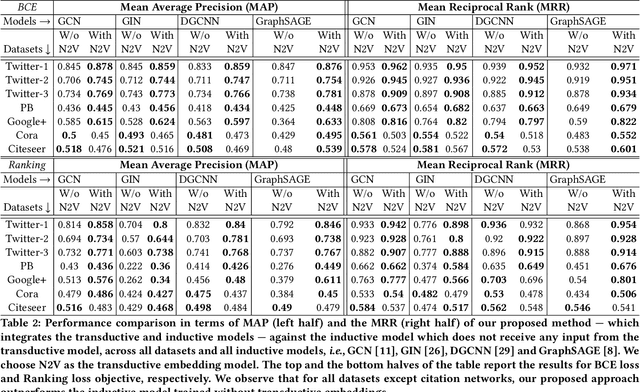
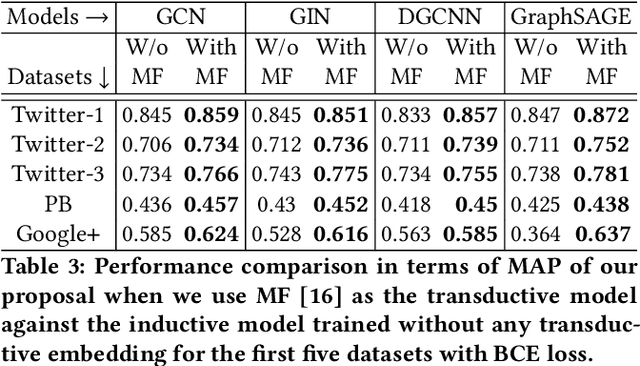
In recent years, inductive graph embedding models, \emph{viz.}, graph neural networks (GNNs) have become increasingly accurate at link prediction (LP) in online social networks. The performance of such networks depends strongly on the input node features, which vary across networks and applications. Selecting appropriate node features remains application-dependent and generally an open question. Moreover, owing to privacy and ethical issues, use of personalized node features is often restricted. In fact, many publicly available data from online social network do not contain any node features (e.g., demography). In this work, we provide a comprehensive experimental analysis which shows that harnessing a transductive technique (e.g., Node2Vec) for obtaining initial node representations, after which an inductive node embedding technique takes over, leads to substantial improvements in link prediction accuracy. We demonstrate that, for a wide variety of GNN variants, node representation vectors obtained from Node2Vec serve as high quality input features to GNNs, thereby improving LP performance.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021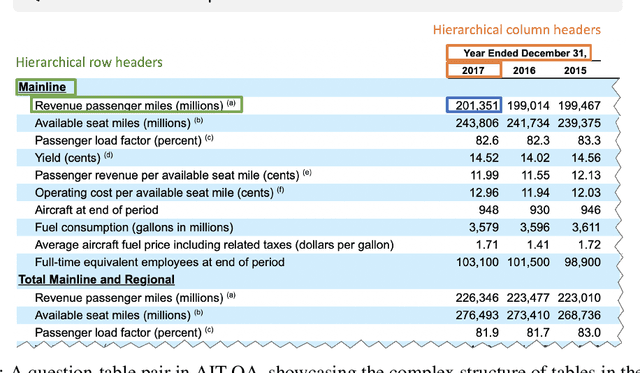
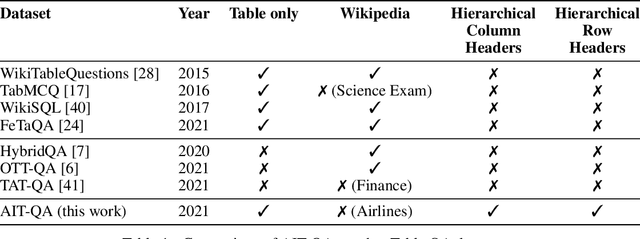
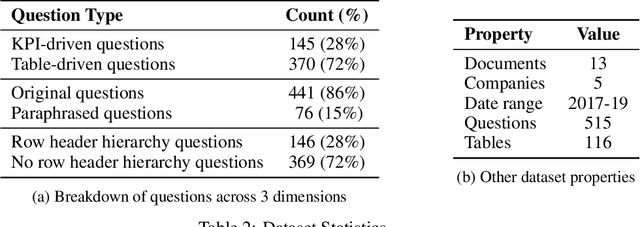
Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
Incomplete Gamma Integrals for Deep Cascade Prediction using Content, Network, and Exogenous Signals
Jun 13, 2021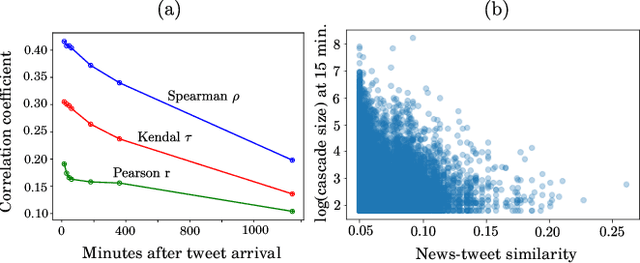

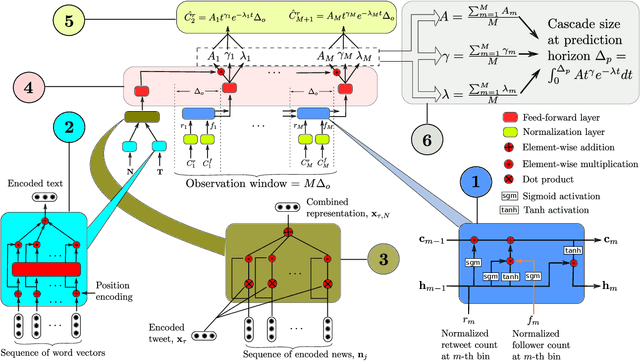
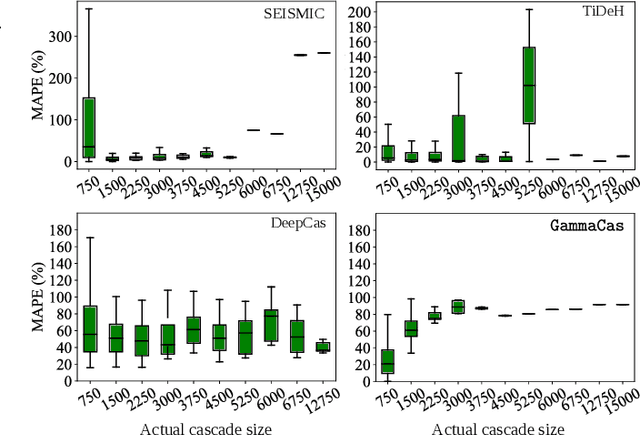
The behaviour of information cascades (such as retweets) has been modelled extensively. While point process-based generative models have long been in use for estimating cascade growths, deep learning has greatly enhanced diverse feature integration. We observe two significant temporal signals in cascade data that have not been emphasized or reported to our knowledge. First, the popularity of the cascade root is known to influence cascade size strongly; but the effect falls off rapidly with time. Second, there is a measurable positive correlation between the novelty of the root content (with respect to a streaming external corpus) and the relative size of the resulting cascade. Responding to these observations, we propose GammaCas, a new cascade growth model as a parametric function of time, which combines deep influence signals from content (e.g., tweet text), network features (e.g., followers of the root user), and exogenous event sources (e.g., online news). Specifically, our model processes these signals through a customized recurrent network, whose states then provide the parameters of the cascade rate function, which is integrated over time to predict the cascade size. The network parameters are trained end-to-end using observed cascades. GammaCas outperforms seven recent and diverse baselines significantly on a large-scale dataset of retweet cascades coupled with time-aligned online news -- it beats the best baseline with an 18.98% increase in terms of Kendall's $\tau$ correlation and $35.63$ reduction in Mean Absolute Percentage Error. Extensive ablation and case studies unearth interesting insights regarding retweet cascade dynamics.
Question Answering Over Temporal Knowledge Graphs
Jun 03, 2021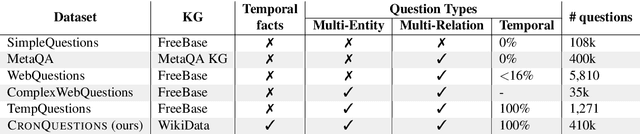
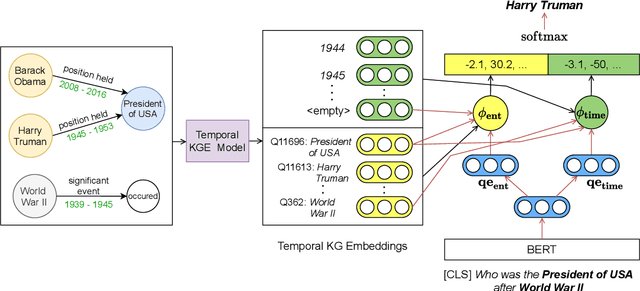

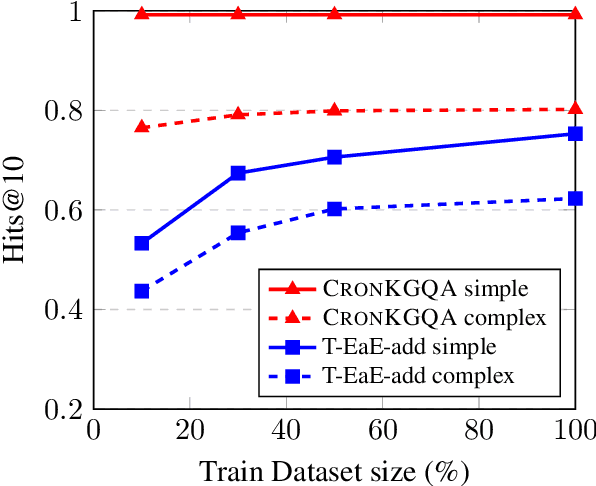
Temporal Knowledge Graphs (Temporal KGs) extend regular Knowledge Graphs by providing temporal scopes (start and end times) on each edge in the KG. While Question Answering over KG (KGQA) has received some attention from the research community, QA over Temporal KGs (Temporal KGQA) is a relatively unexplored area. Lack of broad coverage datasets has been another factor limiting progress in this area. We address this challenge by presenting CRONQUESTIONS, the largest known Temporal KGQA dataset, clearly stratified into buckets of structural complexity. CRONQUESTIONS expands the only known previous dataset by a factor of 340x. We find that various state-of-the-art KGQA methods fall far short of the desired performance on this new dataset. In response, we also propose CRONKGQA, a transformer-based solution that exploits recent advances in Temporal KG embeddings, and achieves performance superior to all baselines, with an increase of 120% in accuracy over the next best performing method. Through extensive experiments, we give detailed insights into the workings of CRONKGQA, as well as situations where significant further improvements appear possible. In addition to the dataset, we have released our code as well.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021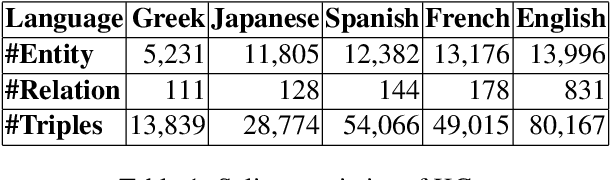
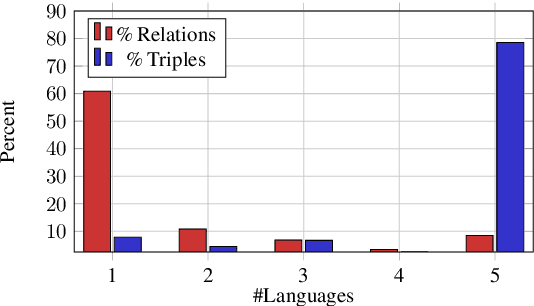
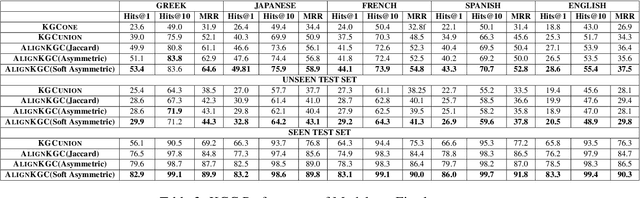

Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
Select, Substitute, Search: A New Benchmark for Knowledge-Augmented Visual Question Answering
Mar 23, 2021
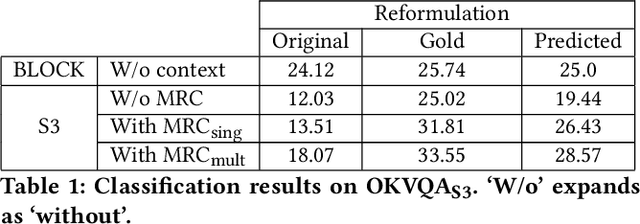

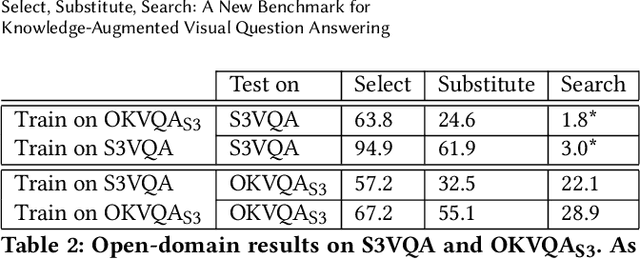
Multimodal IR, spanning text corpus, knowledge graph and images, called outside knowledge visual question answering (OKVQA), is of much recent interest. However, the popular data set has serious limitations. A surprisingly large fraction of queries do not assess the ability to integrate cross-modal information. Instead, some are independent of the image, some depend on speculation, some require OCR or are otherwise answerable from the image alone. To add to the above limitations, frequency-based guessing is very effective because of (unintended) widespread answer overlaps between the train and test folds. Overall, it is hard to determine when state-of-the-art systems exploit these weaknesses rather than really infer the answers, because they are opaque and their 'reasoning' process is uninterpretable. An equally important limitation is that the dataset is designed for the quantitative assessment only of the end-to-end answer retrieval task, with no provision for assessing the correct(semantic) interpretation of the input query. In response, we identify a key structural idiom in OKVQA ,viz., S3 (select, substitute and search), and build a new data set and challenge around it. Specifically, the questioner identifies an entity in the image and asks a question involving that entity which can be answered only by consulting a knowledge graph or corpus passage mentioning the entity. Our challenge consists of (i)OKVQAS3, a subset of OKVQA annotated based on the structural idiom and (ii)S3VQA, a new dataset built from scratch. We also present a neural but structurally transparent OKVQA system, S3, that explicitly addresses our challenge dataset, and outperforms recent competitive baselines.
Joint Autoregressive and Graph Models for Software and Developer Social Networks
Jan 21, 2021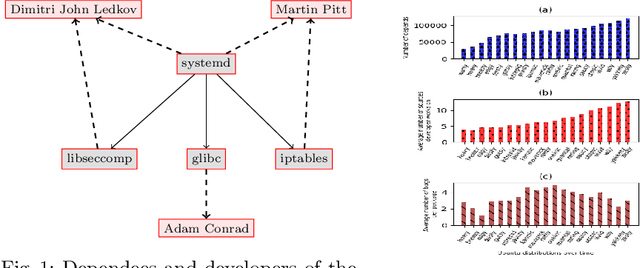

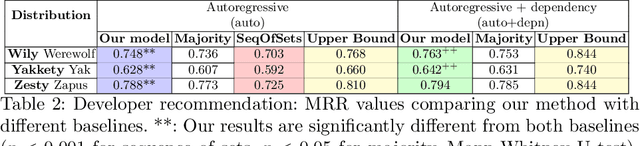
Social network research has focused on hyperlink graphs, bibliographic citations, friend/follow patterns, influence spread, etc. Large software repositories also form a highly valuable networked artifact, usually in the form of a collection of packages, their developers, dependencies among them, and bug reports. This "social network of code" is rarely studied by social network researchers. We introduce two new problems in this setting. These problems are well-motivated in the software engineering community but not closely studied by social network scientists. The first is to identify packages that are most likely to be troubled by bugs in the immediate future, thereby demanding the greatest attention. The second is to recommend developers to packages for the next development cycle. Simple autoregression can be applied to historical data for both problems, but we propose a novel method to integrate network-derived features and demonstrate that our method brings additional benefits. Apart from formalizing these problems and proposing new baseline approaches, we prepare and contribute a substantial dataset connecting multiple attributes built from the long-term history of 20 releases of Ubuntu, growing to over 25,000 packages with their dependency links, maintained by over 3,800 developers, with over 280k bug reports.
Adversarial Permutation Guided Node Representations for Link Prediction
Dec 13, 2020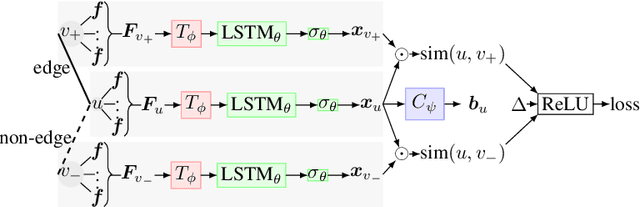
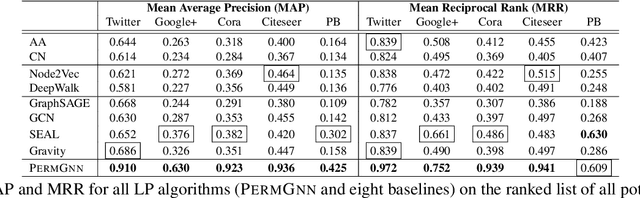
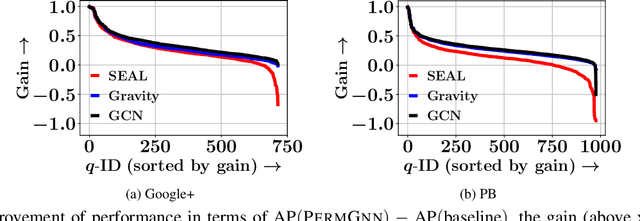

After observing a snapshot of a social network, a link prediction (LP) algorithm identifies node pairs between which new edges will likely materialize in future. Most LP algorithms estimate a score for currently non-neighboring node pairs, and rank them by this score. Recent LP systems compute this score by comparing dense, low dimensional vector representations of nodes. Graph neural networks (GNNs), in particular graph convolutional networks (GCNs), are popular examples. For two nodes to be meaningfully compared, their embeddings should be indifferent to reordering of their neighbors. GNNs typically use simple, symmetric set aggregators to ensure this property, but this design decision has been shown to produce representations with limited expressive power. Sequence encoders are more expressive, but are permutation sensitive by design. Recent efforts to overcome this dilemma turn out to be unsatisfactory for LP tasks. In response, we propose PermGNN, which aggregates neighbor features using a recurrent, order-sensitive aggregator and directly minimizes an LP loss while it is `attacked' by adversarial generator of neighbor permutations. By design, PermGNN{} has more expressive power compared to earlier symmetric aggregators. Next, we devise an optimization framework to map PermGNN's node embeddings to a suitable locality-sensitive hash, which speeds up reporting the top-$K$ most likely edges for the LP task. Our experiments on diverse datasets show that \our outperforms several state-of-the-art link predictors by a significant margin, and can predict the most likely edges fast.
OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction
Oct 07, 2020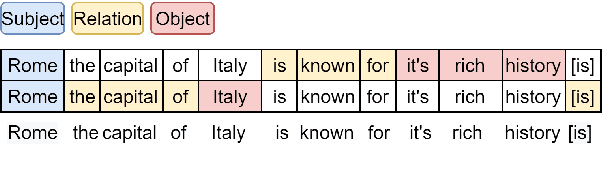

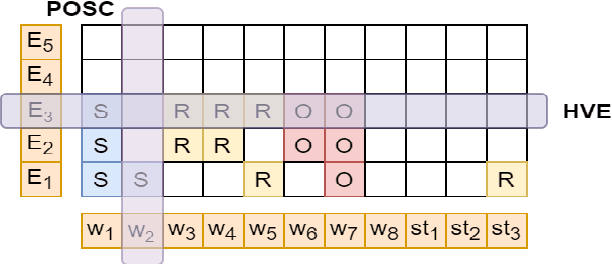
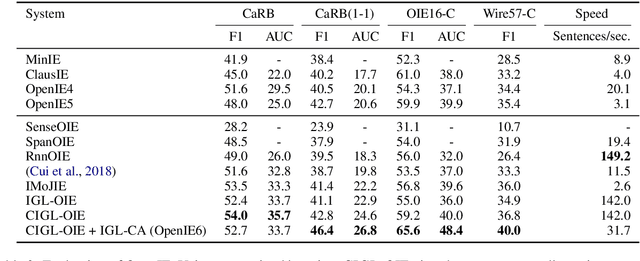
A recent state-of-the-art neural open information extraction (OpenIE) system generates extractions iteratively, requiring repeated encoding of partial outputs. This comes at a significant computational cost. On the other hand, sequence labeling approaches for OpenIE are much faster, but worse in extraction quality. In this paper, we bridge this trade-off by presenting an iterative labeling-based system that establishes a new state of the art for OpenIE, while extracting 10x faster. This is achieved through a novel Iterative Grid Labeling (IGL) architecture, which treats OpenIE as a 2-D grid labeling task. We improve its performance further by applying coverage (soft) constraints on the grid at training time. Moreover, on observing that the best OpenIE systems falter at handling coordination structures, our OpenIE system also incorporates a new coordination analyzer built with the same IGL architecture. This IGL based coordination analyzer helps our OpenIE system handle complicated coordination structures, while also establishing a new state of the art on the task of coordination analysis, with a 12.3 pts improvement in F1 over previous analyzers. Our OpenIE system, OpenIE6, beats the previous systems by as much as 4 pts in F1, while being much faster.