 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-speed multiwavelength photonic temporal integration using silicon photonics
May 07, 2025Optical systems have been pivotal for energy-efficient computing, performing high-speed, parallel operations in low-loss carriers. While these predominantly analog optical accelerators bypass digitization to perform parallel floating-point computations, scaling optical hardware to map large-vector sizes for AI tasks remains challenging. Here, we overcome this limitation by unfolding scalar operations in time and introducing a photonic-heater-in-lightpath (PHIL) unit for all-optical temporal integration. Counterintuitively, we exploit a slow heat dissipation process to integrate optical signals modulated at 50 GHz bridging the speed gap between the widely applied thermo-optic effects and ultrafast photonics. This architecture supports optical end-to-end signal processing, eliminates inefficient electro-optical conversions, and enables both linear and nonlinear operations within a unified framework. Our results demonstrate a scalable path towards high-speed photonic computing through thermally driven integration.
Goal-driven Command Recommendations for Analysts
Nov 12, 2020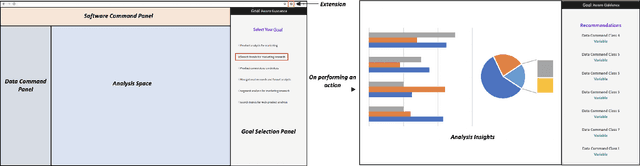
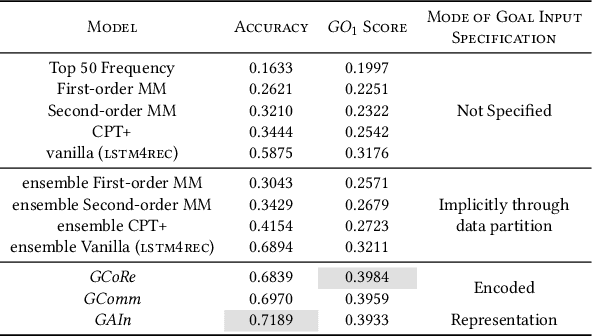
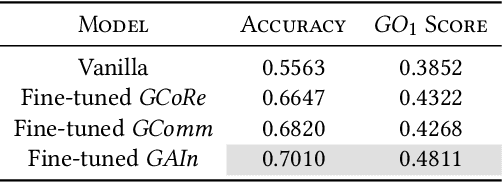
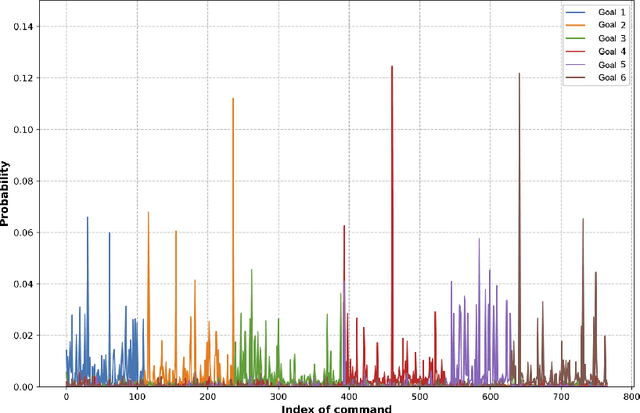
Recent times have seen data analytics software applications become an integral part of the decision-making process of analysts. The users of these software applications generate a vast amount of unstructured log data. These logs contain clues to the user's goals, which traditional recommender systems may find difficult to model implicitly from the log data. With this assumption, we would like to assist the analytics process of a user through command recommendations. We categorize the commands into software and data categories based on their purpose to fulfill the task at hand. On the premise that the sequence of commands leading up to a data command is a good predictor of the latter, we design, develop, and validate various sequence modeling techniques. In this paper, we propose a framework to provide goal-driven data command recommendations to the user by leveraging unstructured logs. We use the log data of a web-based analytics software to train our neural network models and quantify their performance, in comparison to relevant and competitive baselines. We propose a custom loss function to tailor the recommended data commands according to the goal information provided exogenously. We also propose an evaluation metric that captures the degree of goal orientation of the recommendations. We demonstrate the promise of our approach by evaluating the models with the proposed metric and showcasing the robustness of our models in the case of adversarial examples, where the user activity is misaligned with selected goal, through offline evaluation.
OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction
Oct 07, 2020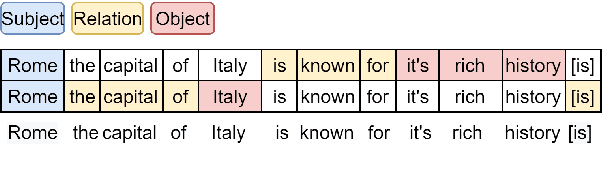

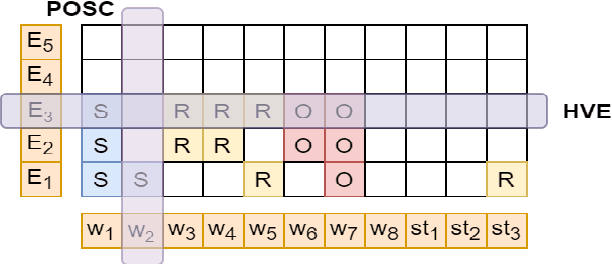
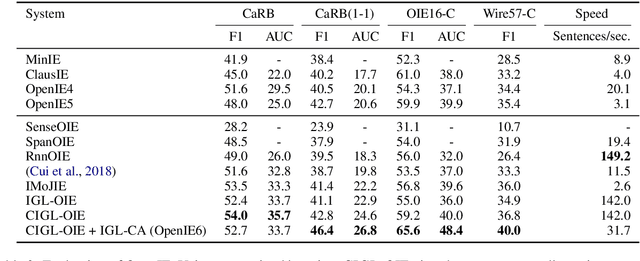
A recent state-of-the-art neural open information extraction (OpenIE) system generates extractions iteratively, requiring repeated encoding of partial outputs. This comes at a significant computational cost. On the other hand, sequence labeling approaches for OpenIE are much faster, but worse in extraction quality. In this paper, we bridge this trade-off by presenting an iterative labeling-based system that establishes a new state of the art for OpenIE, while extracting 10x faster. This is achieved through a novel Iterative Grid Labeling (IGL) architecture, which treats OpenIE as a 2-D grid labeling task. We improve its performance further by applying coverage (soft) constraints on the grid at training time. Moreover, on observing that the best OpenIE systems falter at handling coordination structures, our OpenIE system also incorporates a new coordination analyzer built with the same IGL architecture. This IGL based coordination analyzer helps our OpenIE system handle complicated coordination structures, while also establishing a new state of the art on the task of coordination analysis, with a 12.3 pts improvement in F1 over previous analyzers. Our OpenIE system, OpenIE6, beats the previous systems by as much as 4 pts in F1, while being much faster.
IMoJIE: Iterative Memory-Based Joint Open Information Extraction
May 17, 2020
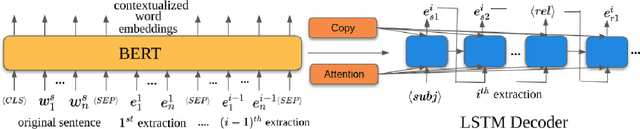


While traditional systems for Open Information Extraction were statistical and rule-based, recently neural models have been introduced for the task. Our work builds upon CopyAttention, a sequence generation OpenIE model (Cui et. al., 2018). Our analysis reveals that CopyAttention produces a constant number of extractions per sentence, and its extracted tuples often express redundant information. We present IMoJIE, an extension to CopyAttention, which produces the next extraction conditioned on all previously extracted tuples. This approach overcomes both shortcomings of CopyAttention, resulting in a variable number of diverse extractions per sentence. We train IMoJIE on training data bootstrapped from extractions of several non-neural systems, which have been automatically filtered to reduce redundancy and noise. IMoJIE outperforms CopyAttention by about 18 F1 pts, and a BERT-based strong baseline by 2 F1 pts, establishing a new state of the art for the task.