 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraction and Hourglass Persistence for Learning on Graphs, Simplices, and Cells
Apr 19, 2026Persistent homology (PH) encodes global information, such as cycles, and is thus increasingly integrated into graph neural networks (GNNs). PH methods in GNNs typically traverse an increasing sequence of subgraphs. In this work, we first expose limitations of this inclusion procedure. To remedy these shortcomings, we analyze contractions as a principled topological operation, in particular, for graph representation learning. We study the persistence of contraction sequences, which we call Contraction Homology (CH). We establish that forward PH and CH differ in expressivity. We then introduce Hourglass Persistence, a class of topological descriptors that interleave a sequence of inclusions and contractions to boost expressivity, learnability, and stability. We also study related families parametrized by two paradigms. We also discuss how our framework extends to simplicial and cellular networks. We further design efficient algorithms that are pluggable into end-to-end differentiable GNN pipelines, enabling consistent empirical improvements over many PH methods across standard real-world graph datasets. Code is available at \href{https://github.com/Aalto-QuML/Hourglass}{this https URL}.
Charting the Design Space of Neural Graph Representations for Subgraph Matching
Oct 27, 2025Subgraph matching is vital in knowledge graph (KG) question answering, molecule design, scene graph, code and circuit search, etc. Neural methods have shown promising results for subgraph matching. Our study of recent systems suggests refactoring them into a unified design space for graph matching networks. Existing methods occupy only a few isolated patches in this space, which remains largely uncharted. We undertake the first comprehensive exploration of this space, featuring such axes as attention-based vs. soft permutation-based interaction between query and corpus graphs, aligning nodes vs. edges, and the form of the final scoring network that integrates neural representations of the graphs. Our extensive experiments reveal that judicious and hitherto-unexplored combinations of choices in this space lead to large performance benefits. Beyond better performance, our study uncovers valuable insights and establishes general design principles for neural graph representation and interaction, which may be of wider interest.
Contextual Tokenization for Graph Inverted Indices
Oct 26, 2025Retrieving graphs from a large corpus, that contain a subgraph isomorphic to a given query graph, is a core operation in many real-world applications. While recent multi-vector graph representations and scores based on set alignment and containment can provide accurate subgraph isomorphism tests, their use in retrieval remains limited by their need to score corpus graphs exhaustively. We introduce CORGII (Contextual Representation of Graphs for Inverted Indexing), a graph indexing framework in which, starting with a contextual dense graph representation, a differentiable discretization module computes sparse binary codes over a learned latent vocabulary. This text document-like representation allows us to leverage classic, highly optimized inverted indices, while supporting soft (vector) set containment scores. Pushing this paradigm further, we replace the classical, fixed impact weight of a `token' on a graph (such as TFIDF or BM25) with a data-driven, trainable impact weight. Finally, we explore token expansion to support multi-probing the index for smoother accuracy-efficiency tradeoffs. To our knowledge, CORGII is the first indexer of dense graph representations using discrete tokens mapping to efficient inverted lists. Extensive experiments show that CORGII provides better trade-offs between accuracy and efficiency, compared to several baselines.
Graph Edit Distance with General Costs Using Neural Set Divergence
Sep 26, 2024



Graph Edit Distance (GED) measures the (dis-)similarity between two given graphs, in terms of the minimum-cost edit sequence that transforms one graph to the other. However, the exact computation of GED is NP-Hard, which has recently motivated the design of neural methods for GED estimation. However, they do not explicitly account for edit operations with different costs. In response, we propose GRAPHEDX, a neural GED estimator that can work with general costs specified for the four edit operations, viz., edge deletion, edge addition, node deletion and node addition. We first present GED as a quadratic assignment problem (QAP) that incorporates these four costs. Then, we represent each graph as a set of node and edge embeddings and use them to design a family of neural set divergence surrogates. We replace the QAP terms corresponding to each operation with their surrogates. Computing such neural set divergence require aligning nodes and edges of the two graphs. We learn these alignments using a Gumbel-Sinkhorn permutation generator, additionally ensuring that the node and edge alignments are consistent with each other. Moreover, these alignments are cognizant of both the presence and absence of edges between node-pairs. Experiments on several datasets, under a variety of edit cost settings, show that GRAPHEDX consistently outperforms state-of-the-art methods and heuristics in terms of prediction error.
* Published at NeurIPS 2024
Adversarial Permutation Guided Node Representations for Link Prediction
Dec 13, 2020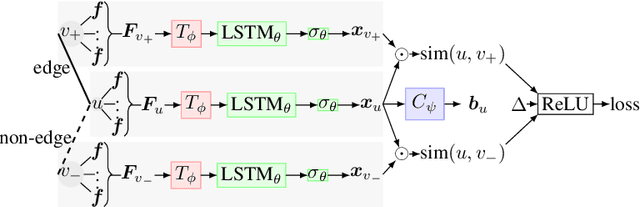
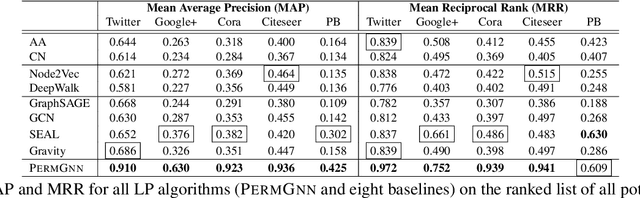
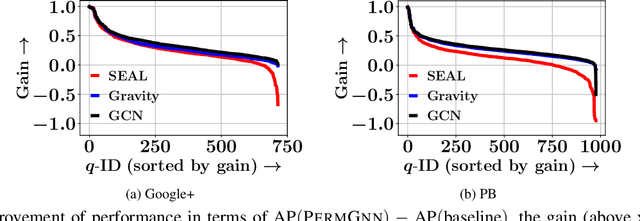

After observing a snapshot of a social network, a link prediction (LP) algorithm identifies node pairs between which new edges will likely materialize in future. Most LP algorithms estimate a score for currently non-neighboring node pairs, and rank them by this score. Recent LP systems compute this score by comparing dense, low dimensional vector representations of nodes. Graph neural networks (GNNs), in particular graph convolutional networks (GCNs), are popular examples. For two nodes to be meaningfully compared, their embeddings should be indifferent to reordering of their neighbors. GNNs typically use simple, symmetric set aggregators to ensure this property, but this design decision has been shown to produce representations with limited expressive power. Sequence encoders are more expressive, but are permutation sensitive by design. Recent efforts to overcome this dilemma turn out to be unsatisfactory for LP tasks. In response, we propose PermGNN, which aggregates neighbor features using a recurrent, order-sensitive aggregator and directly minimizes an LP loss while it is `attacked' by adversarial generator of neighbor permutations. By design, PermGNN{} has more expressive power compared to earlier symmetric aggregators. Next, we devise an optimization framework to map PermGNN's node embeddings to a suitable locality-sensitive hash, which speeds up reporting the top-$K$ most likely edges for the LP task. Our experiments on diverse datasets show that \our outperforms several state-of-the-art link predictors by a significant margin, and can predict the most likely edges fast.
Plagiarism Detection in Polyphonic Music using Monaural Signal Separation
Feb 27, 2015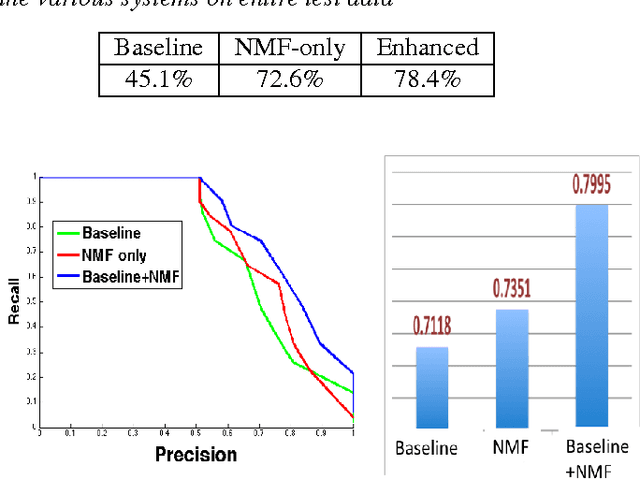
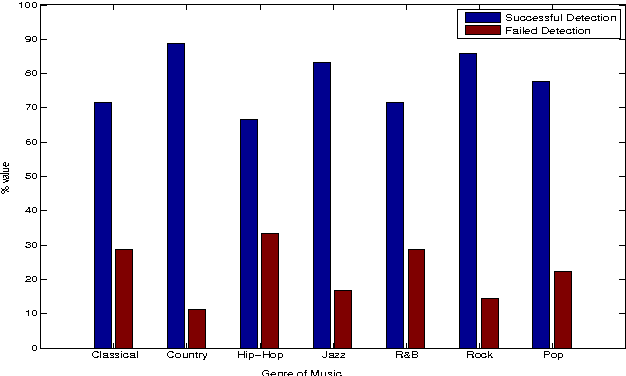
Given the large number of new musical tracks released each year, automated approaches to plagiarism detection are essential to help us track potential violations of copyright. Most current approaches to plagiarism detection are based on musical similarity measures, which typically ignore the issue of polyphony in music. We present a novel feature space for audio derived from compositional modelling techniques, commonly used in signal separation, that provides a mechanism to account for polyphony without incurring an inordinate amount of computational overhead. We employ this feature representation in conjunction with traditional audio feature representations in a classification framework which uses an ensemble of distance features to characterize pairs of songs as being plagiarized or not. Our experiments on a database of about 3000 musical track pairs show that the new feature space characterization produces significant improvements over standard baselines.
* Preprint version