 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch Knowledge Graphs: the Shifting Paradigm of Scholarly Information Representation
Jun 08, 2025Sharing and reusing research artifacts, such as datasets, publications, or methods is a fundamental part of scientific activity, where heterogeneity of resources and metadata and the common practice of capturing information in unstructured publications pose crucial challenges. Reproducibility of research and finding state-of-the-art methods or data have become increasingly challenging. In this context, the concept of Research Knowledge Graphs (RKGs) has emerged, aiming at providing an easy to use and machine-actionable representation of research artifacts and their relations. That is facilitated through the use of established principles for data representation, the consistent adoption of globally unique persistent identifiers and the reuse and linking of vocabularies and data. This paper provides the first conceptualisation of the RKG vision, a categorisation of in-use RKGs together with a description of RKG building blocks and principles. We also survey real-world RKG implementations differing with respect to scale, schema, data, used vocabulary, and reliability of the contained data. We also characterise different RKG construction methodologies and provide a forward-looking perspective on the diverse applications, opportunities, and challenges associated with the RKG vision.
VADIS -- a VAriable Detection, Interlinking and Summarization system
Dec 20, 2023The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
Towards Automated Survey Variable Search and Summarization in Social Science Publications
Sep 14, 2022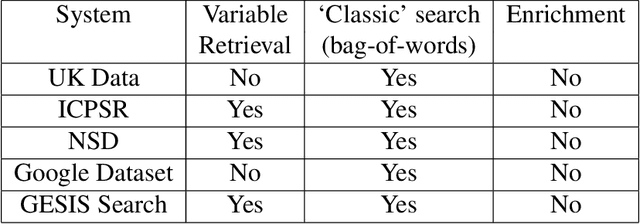
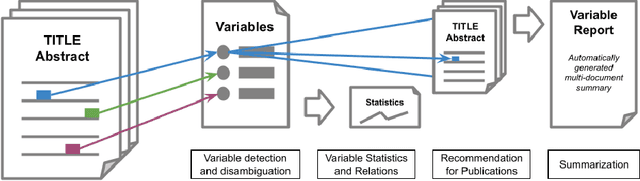
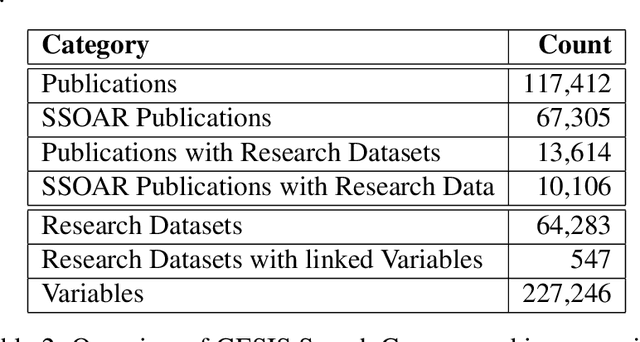
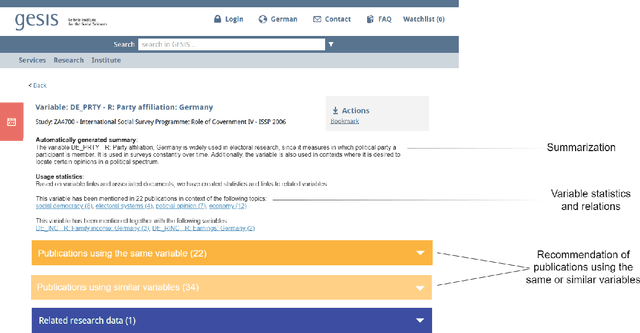
Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
Investigating Software Usage in the Social Sciences: A Knowledge Graph Approach
Mar 24, 2020
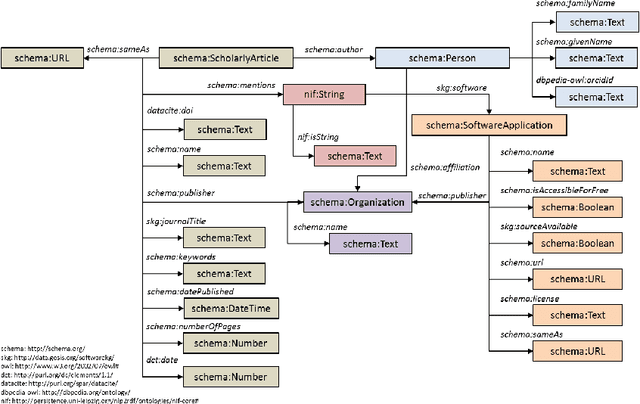

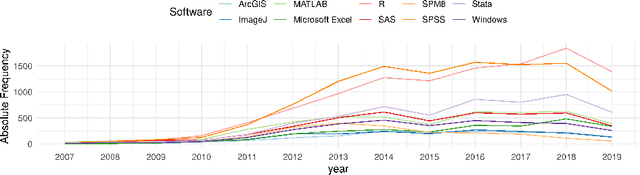
Knowledge about the software used in scientific investigations is necessary for different reasons, including provenance of the results, measuring software impact to attribute developers, and bibliometric software citation analysis in general. Additionally, providing information about whether and how the software and the source code are available allows an assessment about the state and role of open source software in science in general. While such analyses can be done manually, large scale analyses require the application of automated methods of information extraction and linking. In this paper, we present SoftwareKG - a knowledge graph that contains information about software mentions from more than 51,000 scientific articles from the social sciences. A silver standard corpus, created by a distant and weak supervision approach, and a gold standard corpus, created by manual annotation, were used to train an LSTM based neural network to identify software mentions in scientific articles. The model achieves a recognition rate of .82 F-score in exact matches. As a result, we identified more than 133,000 software mentions. For entity disambiguation, we used the public domain knowledge base DBpedia. Furthermore, we linked the entities of the knowledge graph to other knowledge bases such as the Microsoft Academic Knowledge Graph, the Software Ontology, and Wikidata. Finally, we illustrate, how SoftwareKG can be used to assess the role of software in the social sciences.