 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. DocBench: A Comprehensive Benchmark for Expert-Level and Difficult Document Parsing
May 31, 2026Document parsing and recognition are fundamental capabilities for vision-language models (VLMs) and document processing systems. However, existing Optical Character Recognition (OCR) and document parsing benchmarks are increasingly limited in coverage and difficulty: many focus on common document genres or uniformly sampled pages where modern parsers already perform strongly, while offering limited annotation for expert-domain structures such as chemical formula, music notation, complex tables, and cross-page layouts. We introduce Dr. DocBench, a difficulty-aware benchmark for expert-level document parsing. Built from a large-scale multilingual book corpus, Dr. DocBench spans 52 BISAC subject domains and selects challenging documents through parser-failure-based sampling, targeting cases where multiple state-of-the-art systems struggle. It contains 4,514 annotated pages from long documents averaging around 100 pages, with 65k high-quality page- and block-level annotations for layout, reading order, hierarchical relations, and domain-specific visual contents. Evaluations of pipeline-based parsers and general-purpose VLMs show that strong performance on existing benchmarks does not transfer to our expert-level document parsing. Our analysis reveals substantial failures across subjects, content types, and structural attributes, highlighting Dr. DocBench as a comprehensive testbed for diagnosing and advancing document intelligence.
Efficient Quantum Circuits for the Hilbert Transform
Jan 15, 2026The quantum Fourier transform and quantum wavelet transform have been cornerstones of quantum information processing. However, for non-stationary signals and anomaly detection, the Hilbert transform can be a more powerful tool, yet no prior work has provided efficient quantum implementations for the discrete Hilbert transform. This letter presents a novel construction for a quantum Hilbert transform in polylogarithmic size and logarithmic depth for a signal of length $N$, exponentially fewer operations than classical algorithms for the same mapping. We generalize this algorithm to create any $d$-dimensional Hilbert transform in depth $O(d\log N)$. Simulations demonstrate effectiveness for tasks such as power systems control and image processing, with exact agreement with classical results.
EventPoint: Self-Supervised Local Descriptor Learning for Event Cameras
Sep 01, 2021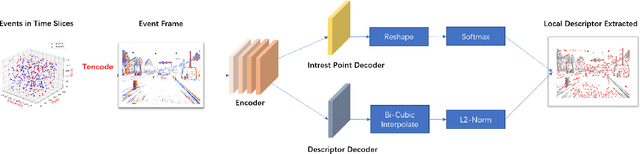

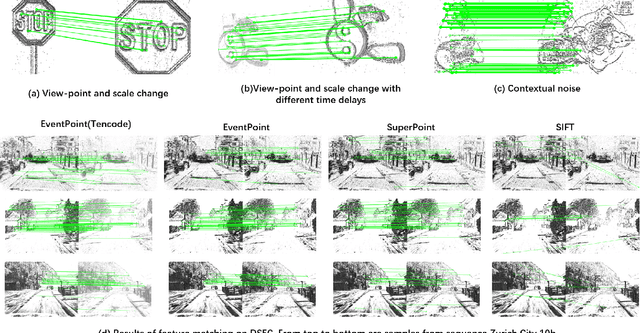
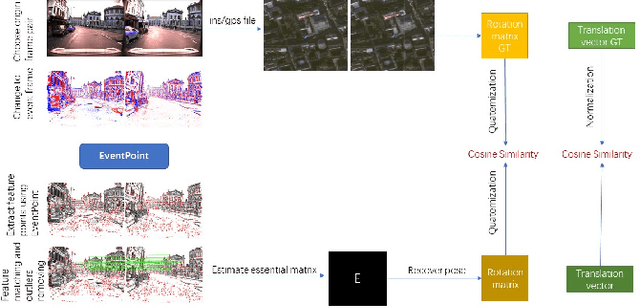
We proposes a method of extracting intrest points and descriptors using self-supervised learning method on frame-based event data, which is called EventPoint. Different from other feature extraction methods on event data, we train our model on real event-form driving dataset--DSEC with the self-supervised learning method we proposed, the training progress fully consider the characteristics of event data.To verify the effectiveness of our work,we conducted several complete evaluations: we emulated DART and carried out feature matching experiments on N-caltech101 dataset, the results shows that the effect of EventPoint is better than DART; We use Vid2e tool provided by UZH to convert Oxford robotcar data into event-based format, and combined with INS information provided to carry out the global pose estimation experiment which is important in SLAM. As far as we know, this is the first work to carry out this challenging task.Sufficient experimental data show that EventPoint can get better results while achieve real time on CPU.