 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleCom: Scalable Sparsified Gradient Compression for Communication-Efficient Distributed Training
Apr 21, 2021
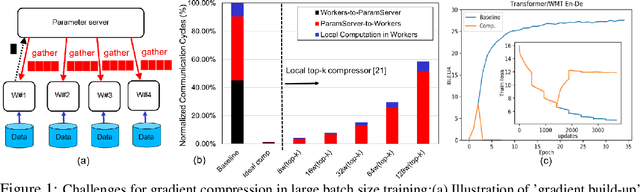
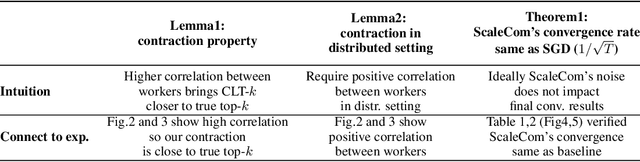
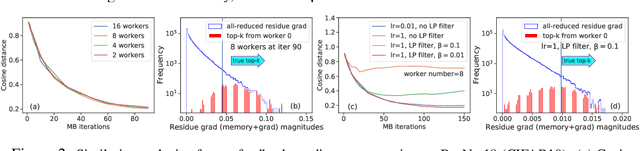
Large-scale distributed training of Deep Neural Networks (DNNs) on state-of-the-art platforms is expected to be severely communication constrained. To overcome this limitation, numerous gradient compression techniques have been proposed and have demonstrated high compression ratios. However, most existing methods do not scale well to large scale distributed systems (due to gradient build-up) and/or fail to evaluate model fidelity (test accuracy) on large datasets. To mitigate these issues, we propose a new compression technique, Scalable Sparsified Gradient Compression (ScaleCom), that leverages similarity in the gradient distribution amongst learners to provide significantly improved scalability. Using theoretical analysis, we show that ScaleCom provides favorable convergence guarantees and is compatible with gradient all-reduce techniques. Furthermore, we experimentally demonstrate that ScaleCom has small overheads, directly reduces gradient traffic and provides high compression rates (65-400X) and excellent scalability (up to 64 learners and 8-12X larger batch sizes over standard training) across a wide range of applications (image, language, and speech) without significant accuracy loss.
Adversarial Examples for Unsupervised Machine Learning Models
Mar 02, 2021

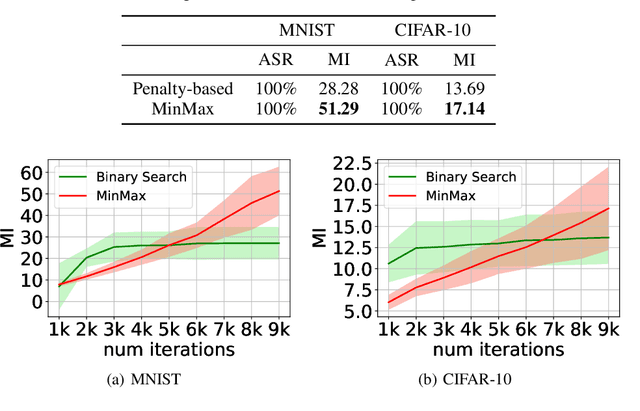
Adversarial examples causing evasive predictions are widely used to evaluate and improve the robustness of machine learning models. However, current studies on adversarial examples focus on supervised learning tasks, relying on the ground-truth data label, a targeted objective, or supervision from a trained classifier. In this paper, we propose a framework of generating adversarial examples for unsupervised models and demonstrate novel applications to data augmentation. Our framework exploits a mutual information neural estimator as an information-theoretic similarity measure to generate adversarial examples without supervision. We propose a new MinMax algorithm with provable convergence guarantees for efficient generation of unsupervised adversarial examples. Our framework can also be extended to supervised adversarial examples. When using unsupervised adversarial examples as a simple plug-in data augmentation tool for model retraining, significant improvements are consistently observed across different unsupervised tasks and datasets, including data reconstruction, representation learning, and contrastive learning. Our results show novel methods and advantages in studying and improving robustness of unsupervised learning problems via adversarial examples. Our codes are available at https://github.com/IBM/UAE.
Federated Acoustic Modeling For Automatic Speech Recognition
Feb 08, 2021


Data privacy and protection is a crucial issue for any automatic speech recognition (ASR) service provider when dealing with clients. In this paper, we investigate federated acoustic modeling using data from multiple clients. A client's data is stored on a local data server and the clients communicate only model parameters with a central server, and not their data. The communication happens infrequently to reduce the communication cost. To mitigate the non-iid issue, client adaptive federated training (CAFT) is proposed to canonicalize data across clients. The experiments are carried out on 1,150 hours of speech data from multiple domains. Hybrid LSTM acoustic models are trained via federated learning and their performance is compared to traditional centralized acoustic model training. The experimental results demonstrate the effectiveness of the proposed federated acoustic modeling strategy. We also show that CAFT can further improve the performance of the federated acoustic model.
Learned Fine-Tuner for Incongruous Few-Shot Learning
Oct 20, 2020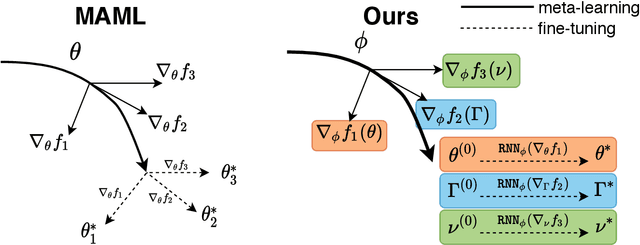
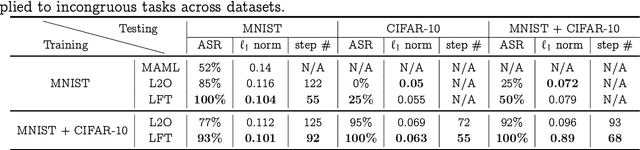
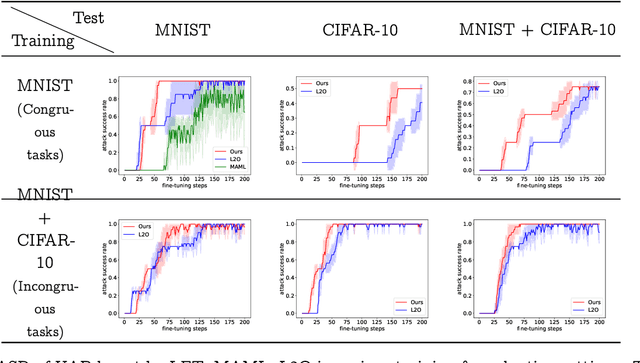
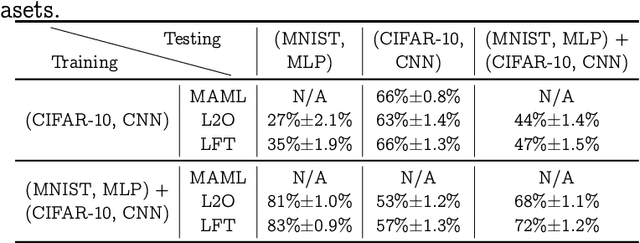
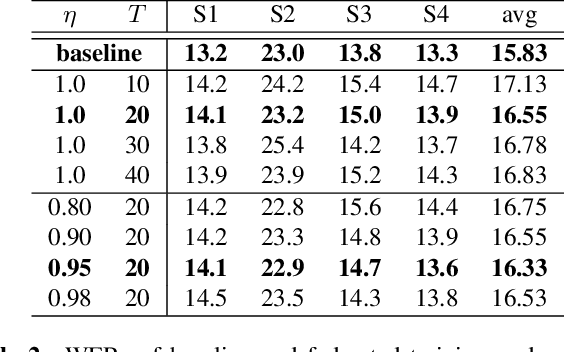
Model-agnostic meta-learning (MAML) effectively meta-learns an initialization of model parameters for few-shot learning where all learning problems share the same format of model parameters -- congruous meta-learning. We extend MAML to incongruous meta-learning where different yet related few-shot learning problems may not share any model parameters. A Learned Fine Tuner (LFT) is used to replace hand-designed optimizers such as SGD for the task-specific fine-tuning. Here, MAML instead meta-learns the parameters of this LFT across incongruous tasks leveraging the learning-to-optimize (L2O) framework such that models fine-tuned with LFT (even from random initializations) adapt quickly to new tasks. As novel contributions, we show that the use of LFT within MAML (i) offers the capability to tackle few-shot learning tasks by meta-learning across incongruous yet related problems (e.g., classification over images of different sizes and model architectures), and (ii) can efficiently work with first-order and derivative-free few-shot learning problems. Theoretically, we quantify the difference between LFT (for MAML) and L2O. Empirically, we demonstrate the effectiveness of LFT through both synthetic and real problems and a novel application of generating universal adversarial attacks across different image sources in the few-shot learning regime.
Randomized Bregman Coordinate Descent Methods for Non-Lipschitz Optimization
Jan 15, 2020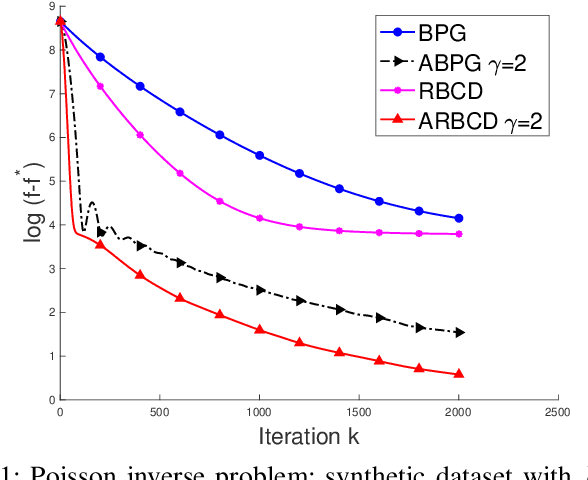
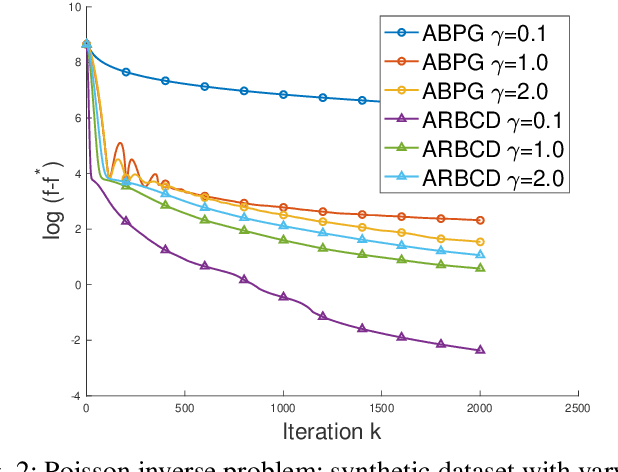
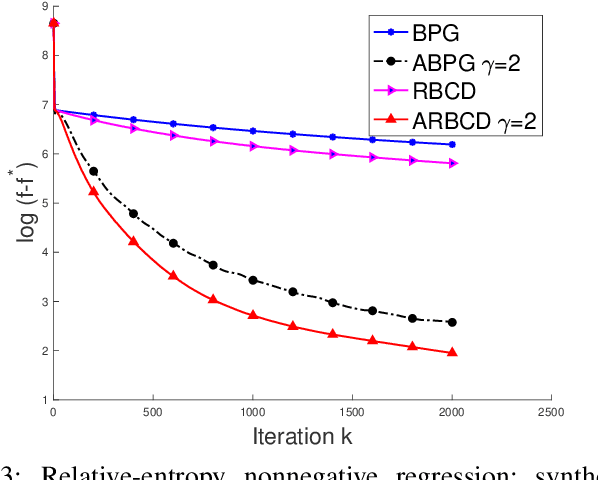
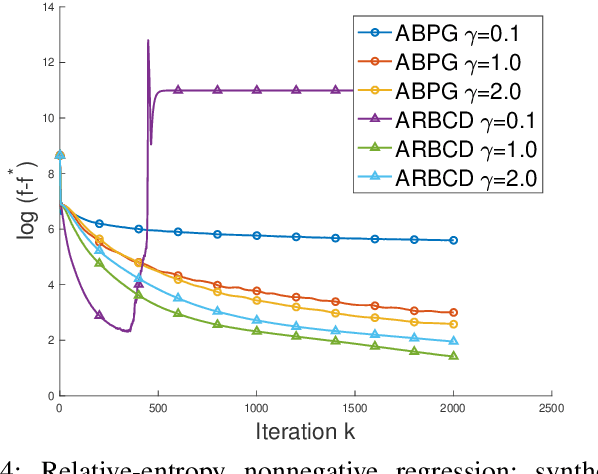
We propose a new \textit{randomized Bregman (block) coordinate descent} (RBCD) method for minimizing a composite problem, where the objective function could be either convex or nonconvex, and the smooth part are freed from the global Lipschitz-continuous (partial) gradient assumption. Under the notion of relative smoothness based on the Bregman distance, we prove that every limit point of the generated sequence is a stationary point. Further, we show that the iteration complexity of the proposed method is $O(n\varepsilon^{-2})$ to achieve $\epsilon$-stationary point, where $n$ is the number of blocks of coordinates. If the objective is assumed to be convex, the iteration complexity is improved to $O(n\epsilon^{-1} )$. If, in addition, the objective is strongly convex (relative to the reference function), the global linear convergence rate is recovered. We also present the accelerated version of the RBCD method, which attains an $O(n\varepsilon^{-1/\gamma} )$ iteration complexity for the convex case, where the scalar $\gamma\in [1,2]$ is determined by the \textit{generalized translation variant} of the Bregman distance. Convergence analysis without assuming the global Lipschitz-continuous (partial) gradient sets our results apart from the existing works in the composite problems.
Distributed Learning in the Non-Convex World: From Batch to Streaming Data, and Beyond
Jan 14, 2020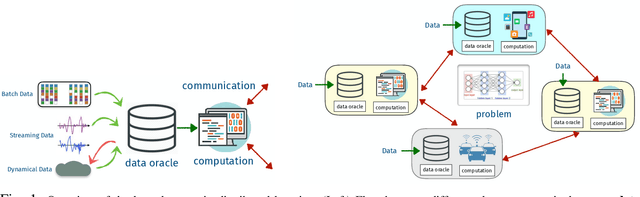
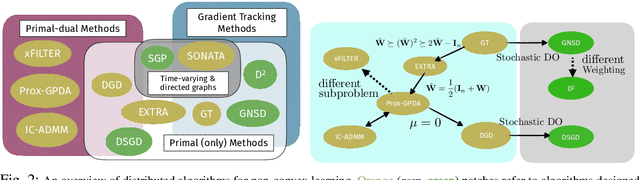
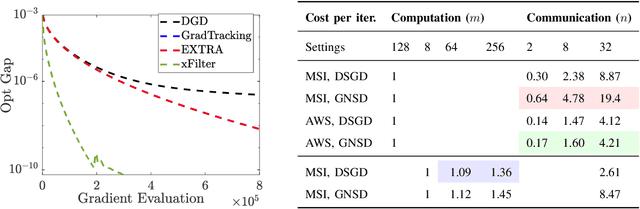
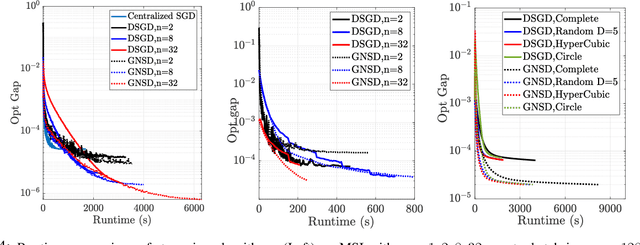
Distributed learning has become a critical enabler of the massively connected world envisioned by many. This article discusses four key elements of scalable distributed processing and real-time intelligence --- problems, data, communication and computation. Our aim is to provide a fresh and unique perspective about how these elements should work together in an effective and coherent manner. In particular, we {provide a selective review} about the recent techniques developed for optimizing non-convex models (i.e., problem classes), processing batch and streaming data (i.e., data types), over the networks in a distributed manner (i.e., communication and computation paradigm). We describe the intuitions and connections behind a core set of popular distributed algorithms, emphasizing how to trade off between computation and communication costs. Practical issues and future research directions will also be discussed.
Leveraging Two Reference Functions in Block Bregman Proximal Gradient Descent for Non-convex and Non-Lipschitz Problems
Dec 16, 2019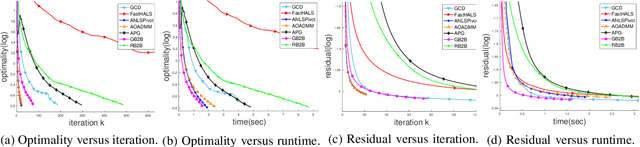
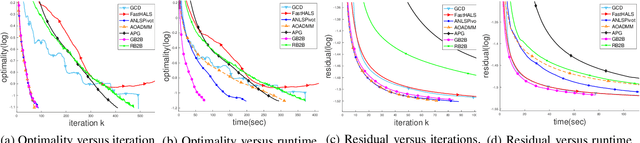
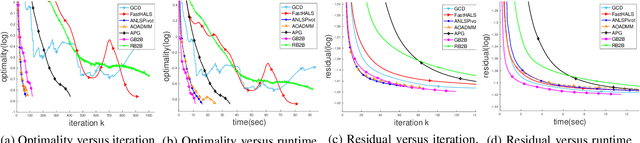
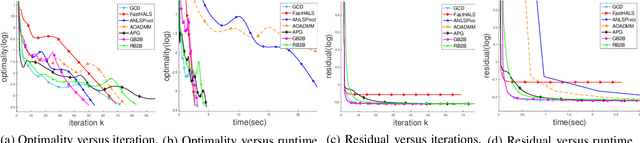
In the applications of signal processing and data analytics, there is a wide class of non-convex problems whose objective function is freed from the common global Lipschitz continuous gradient assumption (e.g., the nonnegative matrix factorization (NMF) problem). Recently, this type of problem with some certain special structures has been solved by Bregman proximal gradient (BPG). This inspires us to propose a new Block-wise two-references Bregman proximal gradient (B2B) method, which adopts two reference functions so that a closed-form solution in the Bregman projection is obtained. Based on the relative smoothness, we prove the global convergence of the proposed algorithms for various block selection rules. In particular, we establish the global convergence rate of $O(\frac{\sqrt{s}}{\sqrt{k}})$ for the greedy and randomized block updating rule for B2B, which is $O(\sqrt{s})$ times faster than the cyclic variant, i.e., $O(\frac{s}{\sqrt{k}} )$, where $s$ is the number of blocks, and $k$ is the number of iterations. Multiple numerical results are provided to illustrate the superiority of the proposed B2B compared to the state-of-the-art works in solving NMF problems.
Learn Electronic Health Records by Fully Decentralized Federated Learning
Dec 10, 2019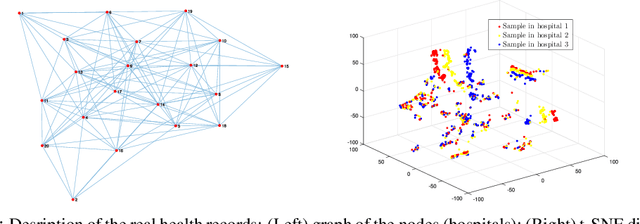
Federated learning opens a number of research opportunities due to its high communication efficiency in distributed training problems within a star network. In this paper, we focus on improving the communication efficiency for fully decentralized federated learning over a graph, where the algorithm performs local updates for several iterations and then enables communications among the nodes. In such a way, the communication rounds of exchanging the common interest of parameters can be saved significantly without loss of optimality of the solutions. Multiple numerical simulations based on large, real-world electronic health record databases showcase the superiority of the decentralized federated learning compared with classic methods.
Online Meta-Learning on Non-convex Setting
Oct 22, 2019
The online meta-learning framework is designed for the continual lifelong learning setting. It bridges two fields: meta-learning which tries to extract prior knowledge from existing tasks for fast learning of future tasks, and online-learning which focuses on the sequential setting in which problems are revealed one by one. In this paper, we generalize the original framework from convex to non-convex setting, and introduce the local regret as the alternative performance measure. We then apply this framework to stochastic settings, and show theoretically that it enjoys a logarithmic local regret, and is robust to any hyperparameter initialization. The empirical test on a real-world task demonstrates its superiority compared with traditional methods.
Improving the Sample and Communication Complexity for Decentralized Non-Convex Optimization: A Joint Gradient Estimation and Tracking Approach
Oct 13, 2019

Many modern large-scale machine learning problems benefit from decentralized and stochastic optimization. Recent works have shown that utilizing both decentralized computing and local stochastic gradient estimates can outperform state-of-the-art centralized algorithms, in applications involving highly non-convex problems, such as training deep neural networks. In this work, we propose a decentralized stochastic algorithm to deal with certain smooth non-convex problems where there are $m$ nodes in the system, and each node has a large number of samples (denoted as $n$). Differently from the majority of the existing decentralized learning algorithms for either stochastic or finite-sum problems, our focus is given to both reducing the total communication rounds among the nodes, while accessing the minimum number of local data samples. In particular, we propose an algorithm named D-GET (decentralized gradient estimation and tracking), which jointly performs decentralized gradient estimation (which estimates the local gradient using a subset of local samples) and gradient tracking (which tracks the global full gradient using local estimates). We show that, to achieve certain $\epsilon$ stationary solution of the deterministic finite sum problem, the proposed algorithm achieves an $\mathcal{O}(mn^{1/2}\epsilon^{-1})$ sample complexity and an $\mathcal{O}(\epsilon^{-1})$ communication complexity. These bounds significantly improve upon the best existing bounds of $\mathcal{O}(mn\epsilon^{-1})$ and $\mathcal{O}(\epsilon^{-1})$, respectively. Similarly, for online problems, the proposed method achieves an $\mathcal{O}(m \epsilon^{-3/2})$ sample complexity and an $\mathcal{O}(\epsilon^{-1})$ communication complexity, while the best existing bounds are $\mathcal{O}(m\epsilon^{-2})$ and $\mathcal{O}(\epsilon^{-2})$, respectively.