 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkshop on Autonomous Driving at CVPR 2021: Technical Report for Streaming Perception Challenge
Jul 27, 2021
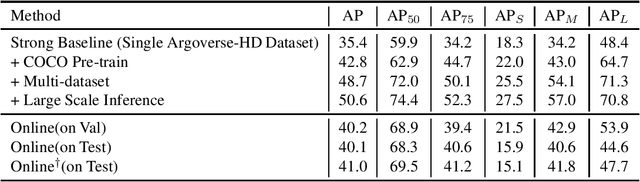
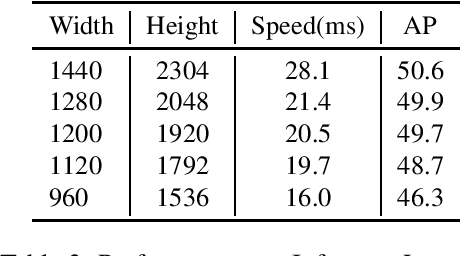
In this report, we introduce our real-time 2D object detection system for the realistic autonomous driving scenario. Our detector is built on a newly designed YOLO model, called YOLOX. On the Argoverse-HD dataset, our system achieves 41.0 streaming AP, which surpassed second place by 7.8/6.1 on detection-only track/fully track, respectively. Moreover, equipped with TensorRT, our model achieves the 30FPS inference speed with a high-resolution input size (e.g., 1440-2304). Code and models will be available at https://github.com/Megvii-BaseDetection/YOLOX
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
Apr 14, 2021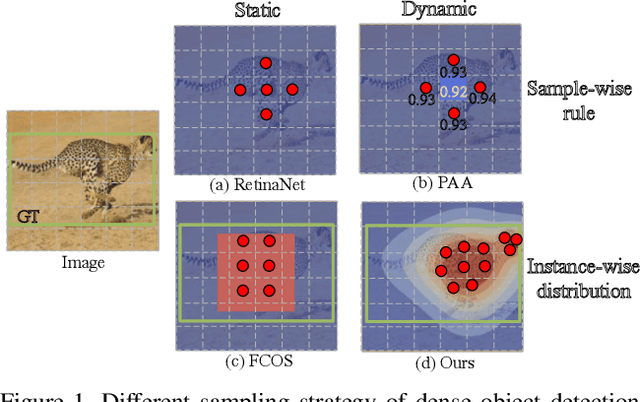
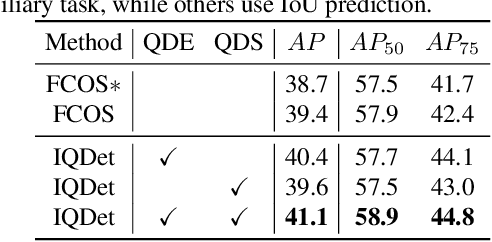
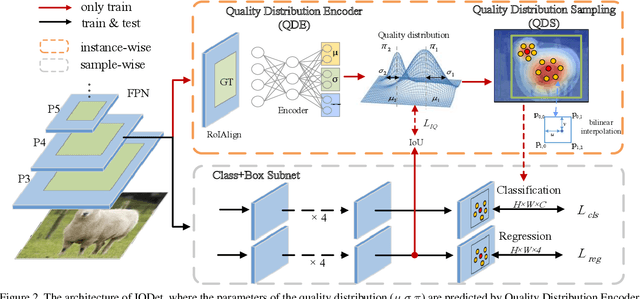
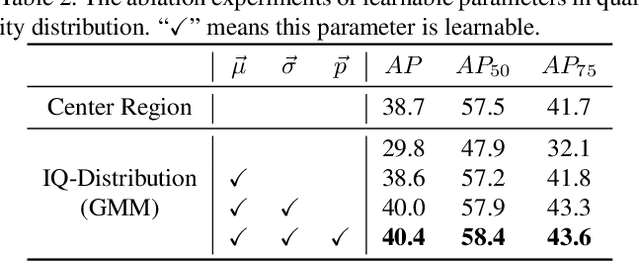
We propose a dense object detector with an instance-wise sampling strategy, named IQDet. Instead of using human prior sampling strategies, we first extract the regional feature of each ground-truth to estimate the instance-wise quality distribution. According to a mixture model in spatial dimensions, the distribution is more noise-robust and adapted to the semantic pattern of each instance. Based on the distribution, we propose a quality sampling strategy, which automatically selects training samples in a probabilistic manner and trains with more high-quality samples. Extensive experiments on MS COCO show that our method steadily improves baseline by nearly 2.4 AP without bells and whistles. Moreover, our best model achieves 51.6 AP, outperforming all existing state-of-the-art one-stage detectors and it is completely cost-free in inference time.
OTA: Optimal Transport Assignment for Object Detection
Mar 26, 2021
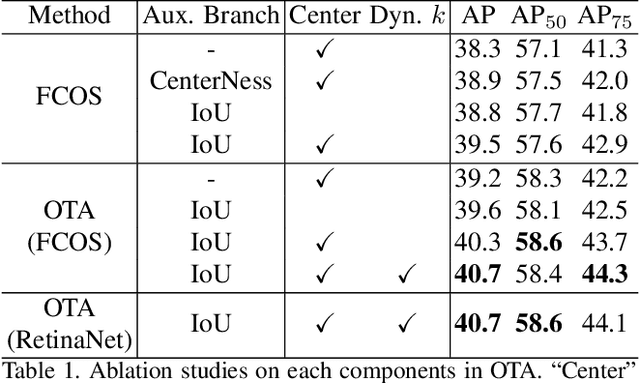
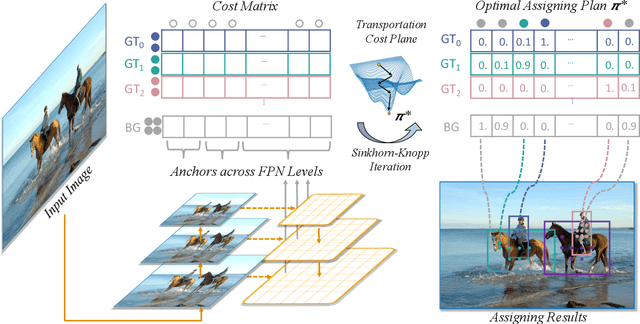
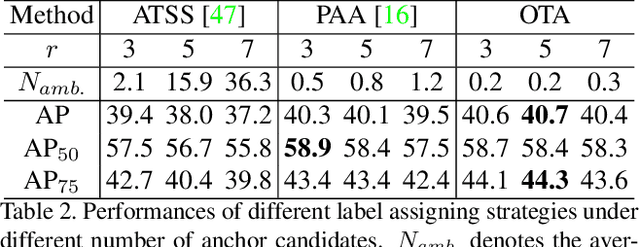
Recent advances in label assignment in object detection mainly seek to independently define positive/negative training samples for each ground-truth (gt) object. In this paper, we innovatively revisit the label assignment from a global perspective and propose to formulate the assigning procedure as an Optimal Transport (OT) problem -- a well-studied topic in Optimization Theory. Concretely, we define the unit transportation cost between each demander (anchor) and supplier (gt) pair as the weighted summation of their classification and regression losses. After formulation, finding the best assignment solution is converted to solve the optimal transport plan at minimal transportation costs, which can be solved via Sinkhorn-Knopp Iteration. On COCO, a single FCOS-ResNet-50 detector equipped with Optimal Transport Assignment (OTA) can reach 40.7% mAP under 1X scheduler, outperforming all other existing assigning methods. Extensive experiments conducted on COCO and CrowdHuman further validate the effectiveness of our proposed OTA, especially its superiority in crowd scenarios. The code is available at https://github.com/Megvii-BaseDetection/OTA.
Momentum^2 Teacher: Momentum Teacher with Momentum Statistics for Self-Supervised Learning
Jan 19, 2021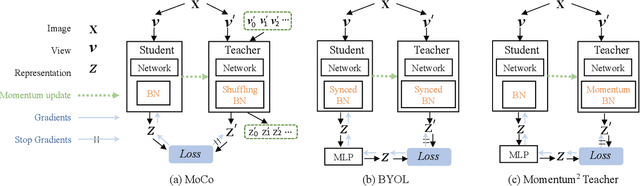
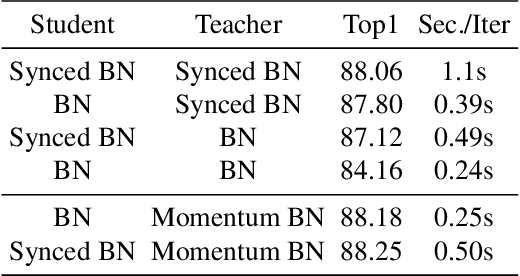
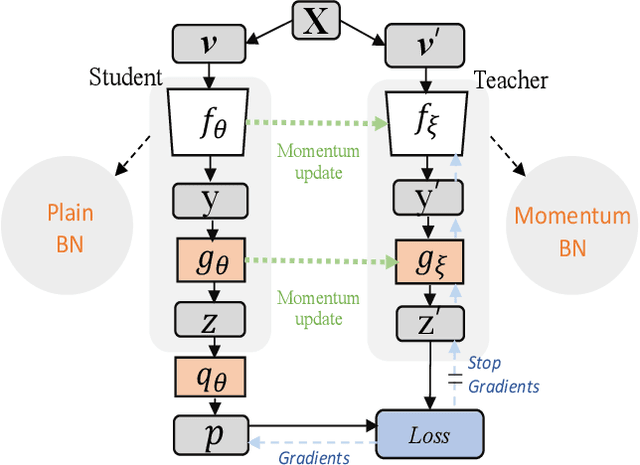
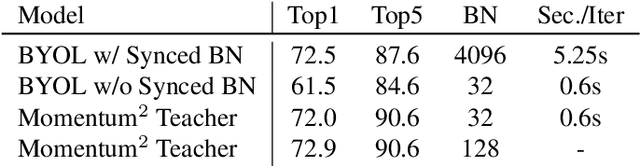
In this paper, we present a novel approach, Momentum$^2$ Teacher, for student-teacher based self-supervised learning. The approach performs momentum update on both network weights and batch normalization (BN) statistics. The teacher's weight is a momentum update of the student, and the teacher's BN statistics is a momentum update of those in history. The Momentum$^2$ Teacher is simple and efficient. It can achieve the state of the art results (74.5\%) under ImageNet linear evaluation protocol using small-batch size(\eg, 128), without requiring large-batch training on special hardware like TPU or inefficient across GPU operation (\eg, shuffling BN, synced BN). Our implementation and pre-trained models will be given on GitHub\footnote{https://github.com/zengarden/momentum2-teacher}.
LLA: Loss-aware Label Assignment for Dense Pedestrian Detection
Jan 12, 2021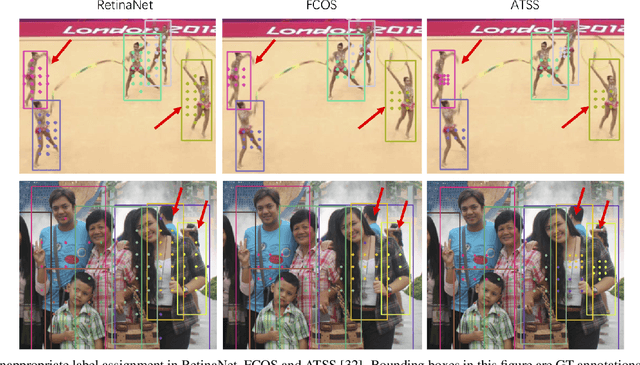
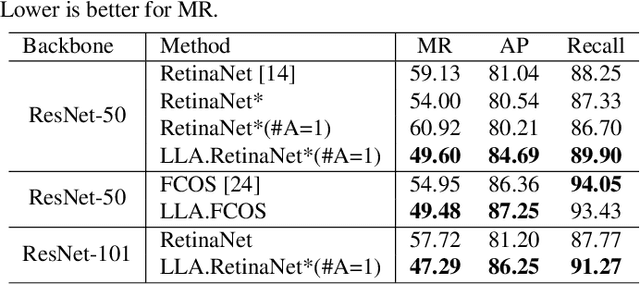


Label assignment has been widely studied in general object detection because of its great impact on detectors' performance. However, none of these works focus on label assignment in dense pedestrian detection. In this paper, we propose a simple yet effective assigning strategy called Loss-aware Label Assignment (LLA) to boost the performance of pedestrian detectors in crowd scenarios. LLA first calculates classification (cls) and regression (reg) losses between each anchor and ground-truth (GT) pair. A joint loss is then defined as the weighted summation of cls and reg losses as the assigning indicator. Finally, anchors with top K minimum joint losses for a certain GT box are assigned as its positive anchors. Anchors that are not assigned to any GT box are considered negative. Loss-aware label assignment is based on an observation that anchors with lower joint loss usually contain richer semantic information and thus can better represent their corresponding GT boxes. Experiments on CrowdHuman and CityPersons show that such a simple label assigning strategy can boost MR by 9.53% and 5.47% on two famous one-stage detectors - RetinaNet and FCOS, respectively, demonstrating the effectiveness of LLA.
Self-EMD: Self-Supervised Object Detection without ImageNet
Dec 08, 2020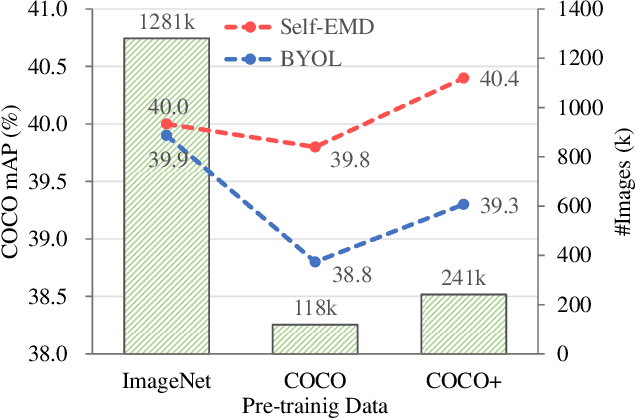
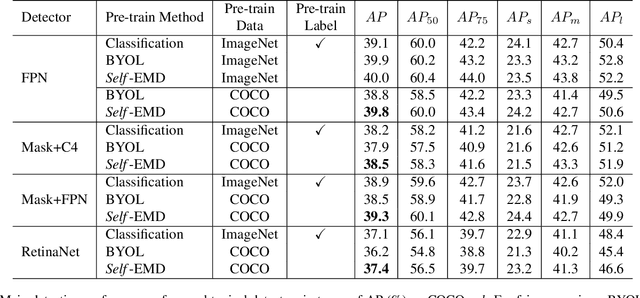

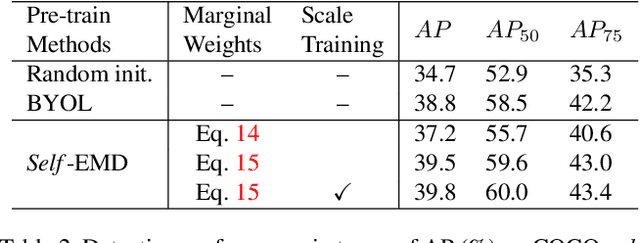
In this paper, we propose a novel self-supervised representation learning method, Self-EMD, for object detection. Our method directly trained on unlabeled non-iconic image dataset like COCO, instead of commonly used iconic-object image dataset like ImageNet. We keep the convolutional feature maps as the image embedding to preserve spatial structures and adopt Earth Mover's Distance (EMD) to compute the similarity between two embeddings. Our Faster R-CNN (ResNet50-FPN) baseline achieves 39.8% mAP on COCO, which is on par with the state of the art self-supervised methods pre-trained on ImageNet. More importantly, it can be further improved to 40.4% mAP with more unlabeled images, showing its great potential for leveraging more easily obtained unlabeled data. Code will be made available.
BorderDet: Border Feature for Dense Object Detection
Jul 21, 2020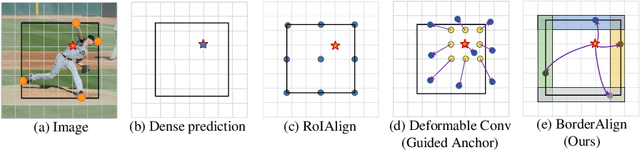
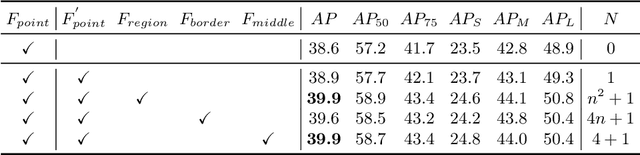
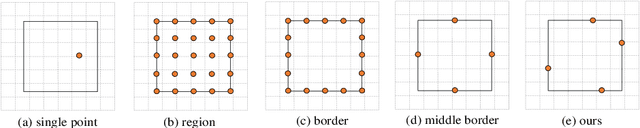
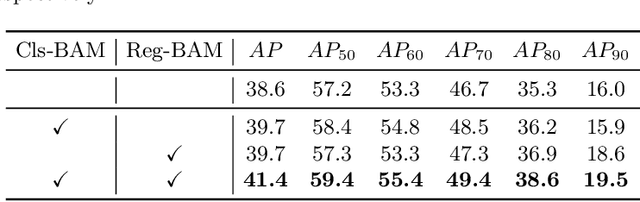
Dense object detectors rely on the sliding-window paradigm that predicts the object over a regular grid of image. Meanwhile, the feature maps on the point of the grid are adopted to generate the bounding box predictions. The point feature is convenient to use but may lack the explicit border information for accurate localization. In this paper, We propose a simple and efficient operator called Border-Align to extract "border features" from the extreme point of the border to enhance the point feature. Based on the BorderAlign, we design a novel detection architecture called BorderDet, which explicitly exploits the border information for stronger classification and more accurate localization. With ResNet-50 backbone, our method improves single-stage detector FCOS by 2.8 AP gains (38.6 v.s. 41.4). With the ResNeXt-101-DCN backbone, our BorderDet obtains 50.3 AP, outperforming the existing state-of-the-art approaches. The code is available at (https://github.com/Megvii-BaseDetection/BorderDet).
Multi-Scale Positive Sample Refinement for Few-Shot Object Detection
Jul 18, 2020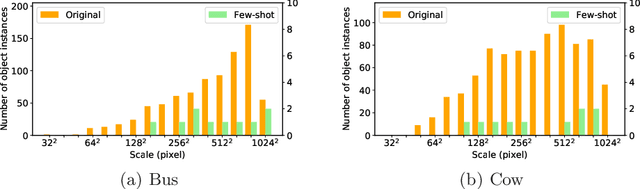

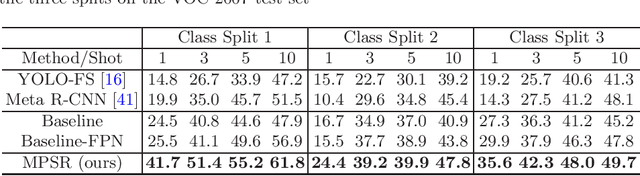
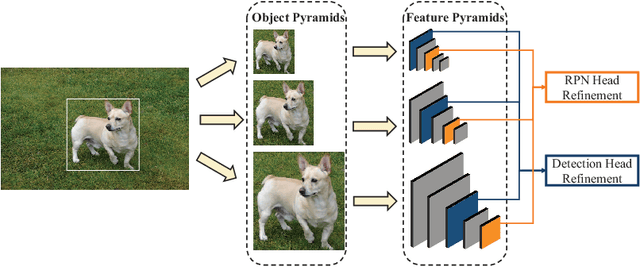
Few-shot object detection (FSOD) helps detectors adapt to unseen classes with few training instances, and is useful when manual annotation is time-consuming or data acquisition is limited. Unlike previous attempts that exploit few-shot classification techniques to facilitate FSOD, this work highlights the necessity of handling the problem of scale variations, which is challenging due to the unique sample distribution. To this end, we propose a Multi-scale Positive Sample Refinement (MPSR) approach to enrich object scales in FSOD. It generates multi-scale positive samples as object pyramids and refines the prediction at various scales. We demonstrate its advantage by integrating it as an auxiliary branch to the popular architecture of Faster R-CNN with FPN, delivering a strong FSOD solution. Several experiments are conducted on PASCAL VOC and MS COCO, and the proposed approach achieves state of the art results and significantly outperforms other counterparts, which shows its effectiveness. Code is available at https://github.com/jiaxi-wu/MPSR.
AutoAssign: Differentiable Label Assignment for Dense Object Detection
Jul 07, 2020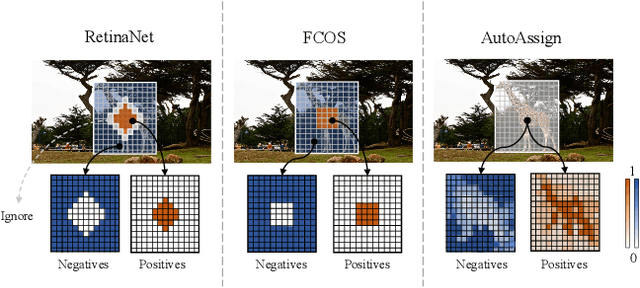
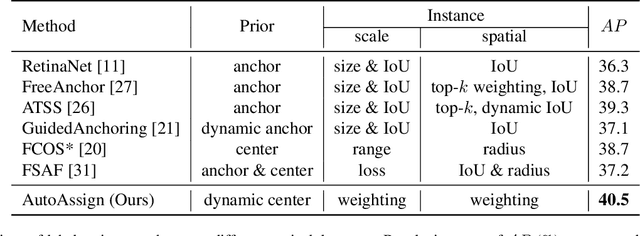

In this paper, we propose an anchor-free object detector with a fully differentiable label assignment strategy, named AutoAssign. It automatically determines positive/negative samples by generating positive and negative weight maps to modify each location's prediction dynamically. Specifically, we present a center weighting module to adjust the category-specific prior distributions and a confidence weighting module to adapt the specific assign strategy of each instance. The entire label assignment process is differentiable and requires no additional modification to transfer to different datasets and tasks. Extensive experiments on MS COCO show that our method steadily surpasses other best sampling strategies by $ \sim $ 1\% AP with various backbones. Moreover, our best model achieves 52.1\% AP, outperforming all existing one-stage detectors. Besides, experiments on other datasets, \emph{e.g.}, PASCAL VOC, Objects365, and WiderFace, demonstrate the broad applicability of AutoAssign.
Cross-domain Object Detection through Coarse-to-Fine Feature Adaptation
Mar 23, 2020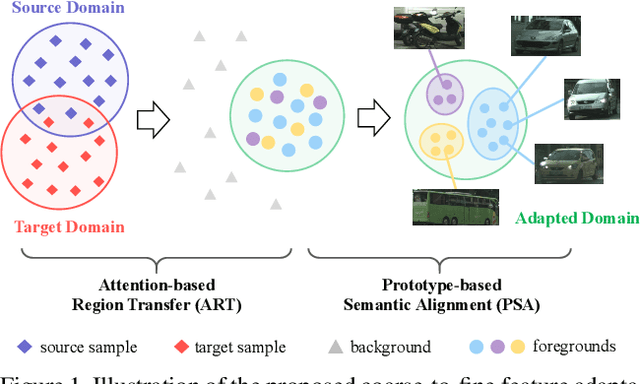
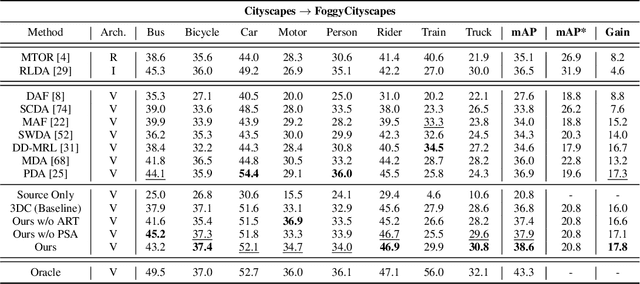
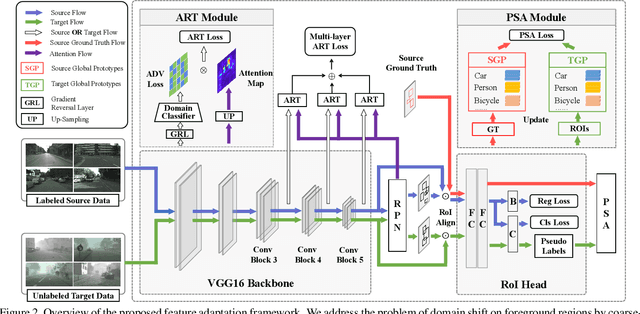
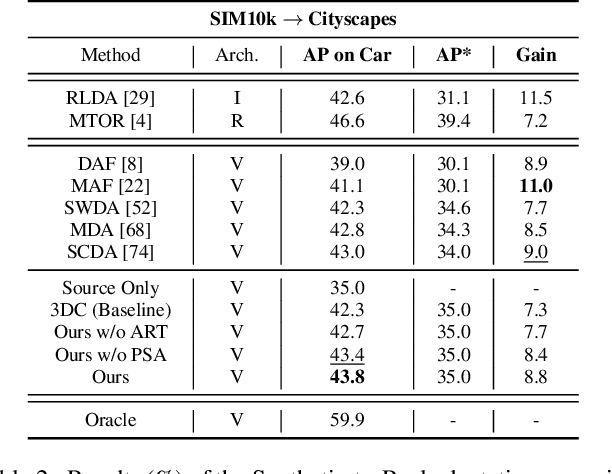
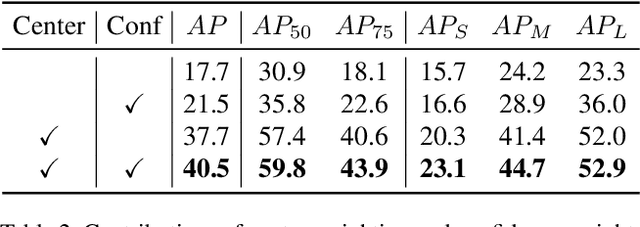
Recent years have witnessed great progress in deep learning based object detection. However, due to the domain shift problem, applying off-the-shelf detectors to an unseen domain leads to significant performance drop. To address such an issue, this paper proposes a novel coarse-to-fine feature adaptation approach to cross-domain object detection. At the coarse-grained stage, different from the rough image-level or instance-level feature alignment used in the literature, foreground regions are extracted by adopting the attention mechanism, and aligned according to their marginal distributions via multi-layer adversarial learning in the common feature space. At the fine-grained stage, we conduct conditional distribution alignment of foregrounds by minimizing the distance of global prototypes with the same category but from different domains. Thanks to this coarse-to-fine feature adaptation, domain knowledge in foreground regions can be effectively transferred. Extensive experiments are carried out in various cross-domain detection scenarios. The results are state-of-the-art, which demonstrate the broad applicability and effectiveness of the proposed approach.