 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMars: Situated Inductive Reasoning in an Open-World Environment
Oct 10, 2024



Large Language Models (LLMs) trained on massive corpora have shown remarkable success in knowledge-intensive tasks. Yet, most of them rely on pre-stored knowledge. Inducing new general knowledge from a specific environment and performing reasoning with the acquired knowledge -- \textit{situated inductive reasoning}, is crucial and challenging for machine intelligence. In this paper, we design Mars, an interactive environment devised for situated inductive reasoning. It introduces counter-commonsense game mechanisms by modifying terrain, survival setting and task dependency while adhering to certain principles. In Mars, agents need to actively interact with their surroundings, derive useful rules and perform decision-making tasks in specific contexts. We conduct experiments on various RL-based and LLM-based methods, finding that they all struggle on this challenging situated inductive reasoning benchmark. Furthermore, we explore \textit{Induction from Reflection}, where we instruct agents to perform inductive reasoning from history trajectory. The superior performance underscores the importance of inductive reasoning in Mars. Through Mars, we aim to galvanize advancements in situated inductive reasoning and set the stage for developing the next generation of AI systems that can reason in an adaptive and context-sensitive way.
CORE: Common Random Reconstruction for Distributed Optimization with Provable Low Communication Complexity
Sep 23, 2023With distributed machine learning being a prominent technique for large-scale machine learning tasks, communication complexity has become a major bottleneck for speeding up training and scaling up machine numbers. In this paper, we propose a new technique named Common randOm REconstruction(CORE), which can be used to compress the information transmitted between machines in order to reduce communication complexity without other strict conditions. Especially, our technique CORE projects the vector-valued information to a low-dimensional one through common random vectors and reconstructs the information with the same random noises after communication. We apply CORE to two distributed tasks, respectively convex optimization on linear models and generic non-convex optimization, and design new distributed algorithms, which achieve provably lower communication complexities. For example, we show for linear models CORE-based algorithm can encode the gradient vector to $\mathcal{O}(1)$-bits (against $\mathcal{O}(d)$), with the convergence rate not worse, preceding the existing results.
LEMMA: A Multi-view Dataset for Learning Multi-agent Multi-task Activities
Jul 31, 2020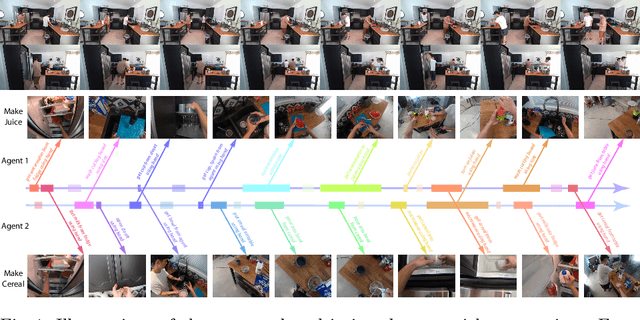
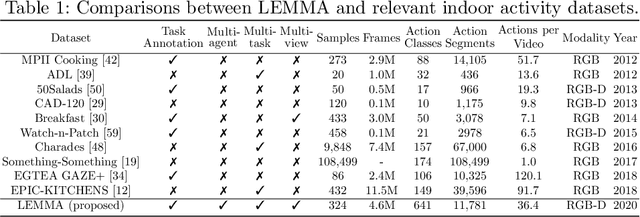

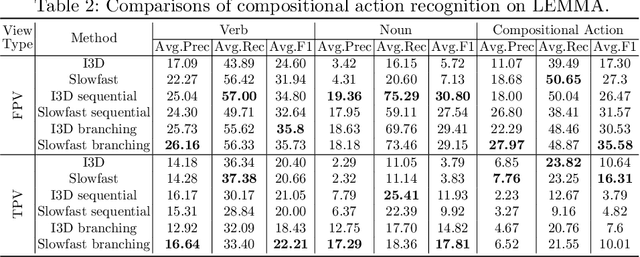
Understanding and interpreting human actions is a long-standing challenge and a critical indicator of perception in artificial intelligence. However, a few imperative components of daily human activities are largely missed in prior literature, including the goal-directed actions, concurrent multi-tasks, and collaborations among multi-agents. We introduce the LEMMA dataset to provide a single home to address these missing dimensions with meticulously designed settings, wherein the number of tasks and agents varies to highlight different learning objectives. We densely annotate the atomic-actions with human-object interactions to provide ground-truths of the compositionality, scheduling, and assignment of daily activities. We further devise challenging compositional action recognition and action/task anticipation benchmarks with baseline models to measure the capability of compositional action understanding and temporal reasoning. We hope this effort would drive the machine vision community to examine goal-directed human activities and further study the task scheduling and assignment in the real world.