 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Instruction-based Prompting for Fallacy Recognition
Jan 24, 2023Fallacies are used as seemingly valid arguments to support a position and persuade the audience about its validity. Recognizing fallacies is an intrinsically difficult task both for humans and machines. Moreover, a big challenge for computational models lies in the fact that fallacies are formulated differently across the datasets with differences in the input format (e.g., question-answer pair, sentence with fallacy fragment), genre (e.g., social media, dialogue, news), as well as types and number of fallacies (from 5 to 18 types per dataset). To move towards solving the fallacy recognition task, we approach these differences across datasets as multiple tasks and show how instruction-based prompting in a multitask setup based on the T5 model improves the results against approaches built for a specific dataset such as T5, BERT or GPT-3. We show the ability of this multitask prompting approach to recognize 28 unique fallacies across domains and genres and study the effect of model size and prompt choice by analyzing the per-class (i.e., fallacy type) results. Finally, we analyze the effect of annotation quality on model performance, and the feasibility of complementing this approach with external knowledge.
* In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8172 - 8187
Affective Idiosyncratic Responses to Music
Oct 17, 2022
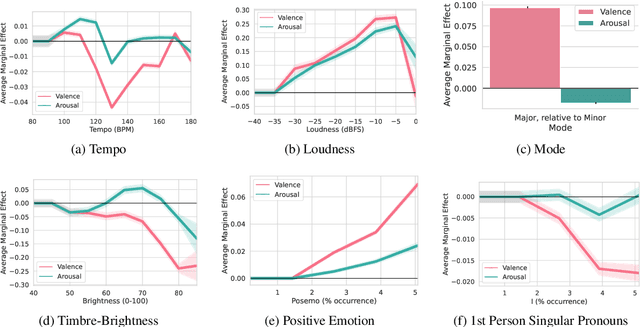
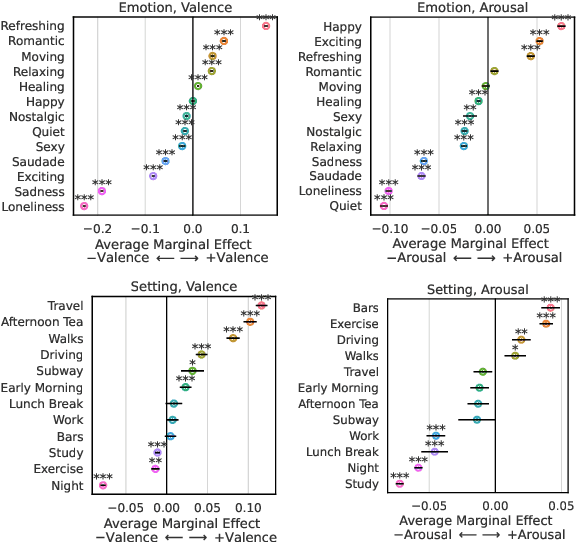
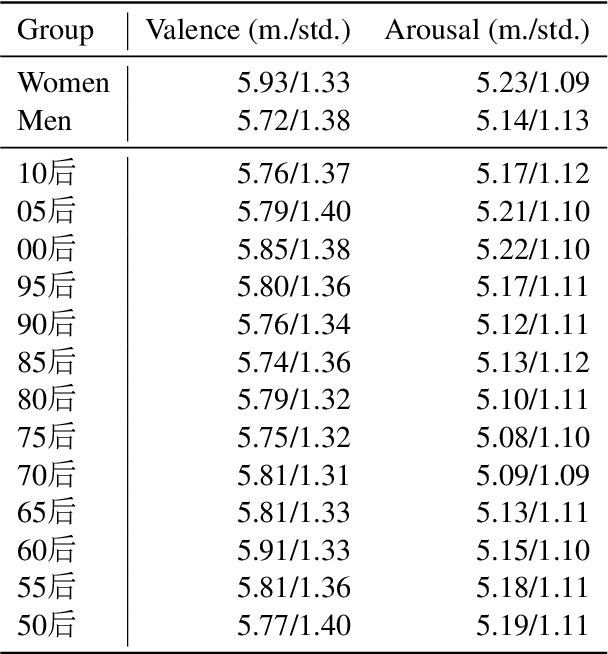
Affective responses to music are highly personal. Despite consensus that idiosyncratic factors play a key role in regulating how listeners emotionally respond to music, precisely measuring the marginal effects of these variables has proved challenging. To address this gap, we develop computational methods to measure affective responses to music from over 403M listener comments on a Chinese social music platform. Building on studies from music psychology in systematic and quasi-causal analyses, we test for musical, lyrical, contextual, demographic, and mental health effects that drive listener affective responses. Finally, motivated by the social phenomenon known as w\v{a}ng-y\`i-y\'un, we identify influencing factors of platform user self-disclosures, the social support they receive, and notable differences in discloser user activity.
NormSAGE: Multi-Lingual Multi-Cultural Norm Discovery from Conversations On-the-Fly
Oct 16, 2022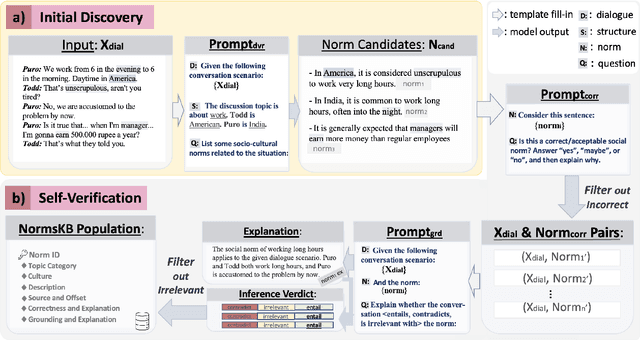
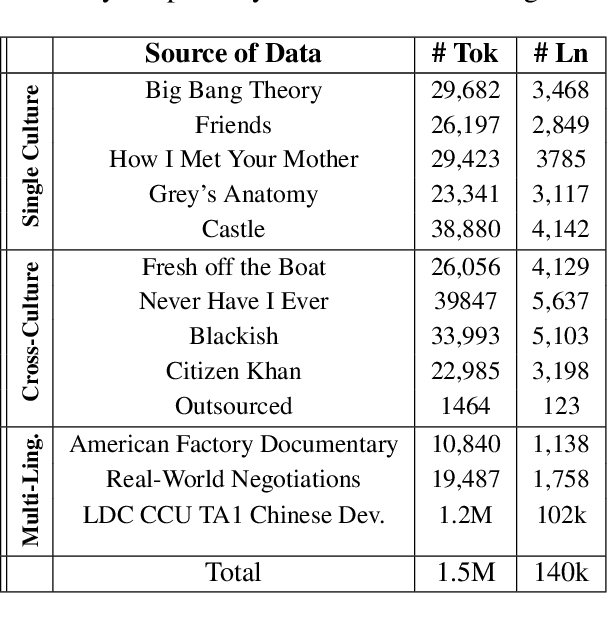
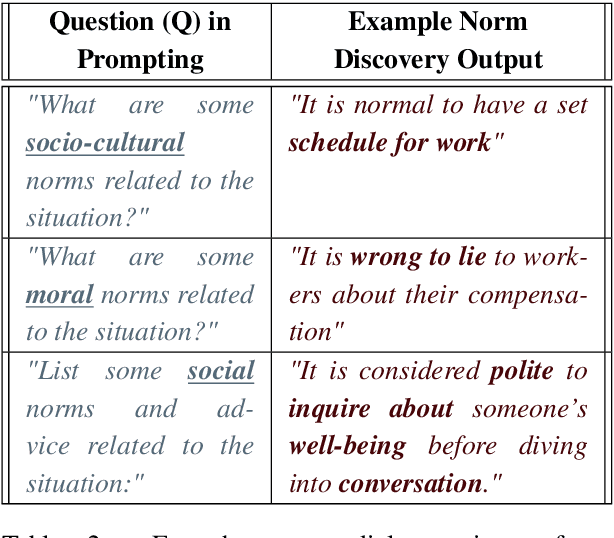

Norm discovery is important for understanding and reasoning about the acceptable behaviors and potential violations in human communication and interactions. We introduce NormSage, a framework for addressing the novel task of conversation-grounded multi-lingual, multi-cultural norm discovery, based on language model prompting and self-verification. NormSAGE leverages the expressiveness and implicit knowledge of the pretrained GPT-3 language model backbone, to elicit knowledge about norms through directed questions representing the norm discovery task and conversation context. It further addresses the risk of language model hallucination with a self-verification mechanism ensuring that the norms discovered are correct and are substantially grounded to their source conversations. Evaluation results show that our approach discovers significantly more relevant and insightful norms for conversations on-the-fly compared to baselines (>10+% in Likert scale rating). The norms discovered from Chinese conversation are also comparable to the norms discovered from English conversation in terms of insightfulness and correctness (<3% difference). In addition, the culture-specific norms are promising quality, allowing for 80% accuracy in culture pair human identification. Finally, our grounding process in norm discovery self-verification can be extended for instantiating the adherence and violation of any norm for a given conversation on-the-fly, with explainability and transparency. NormSAGE achieves an AUC of 95.4% in grounding, with natural language explanation matching human-written quality.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022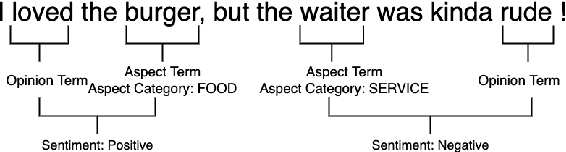
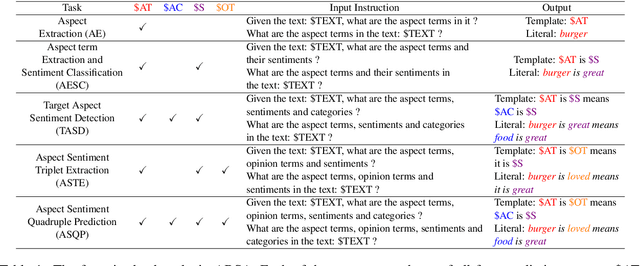
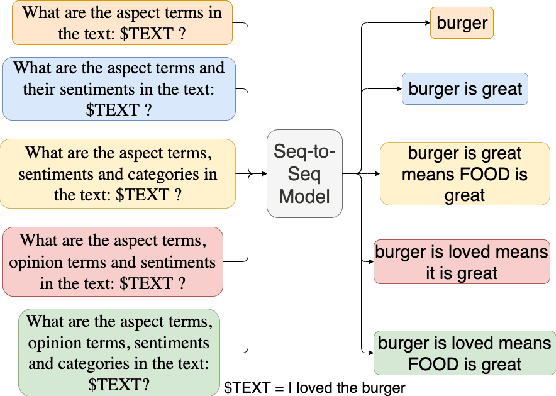
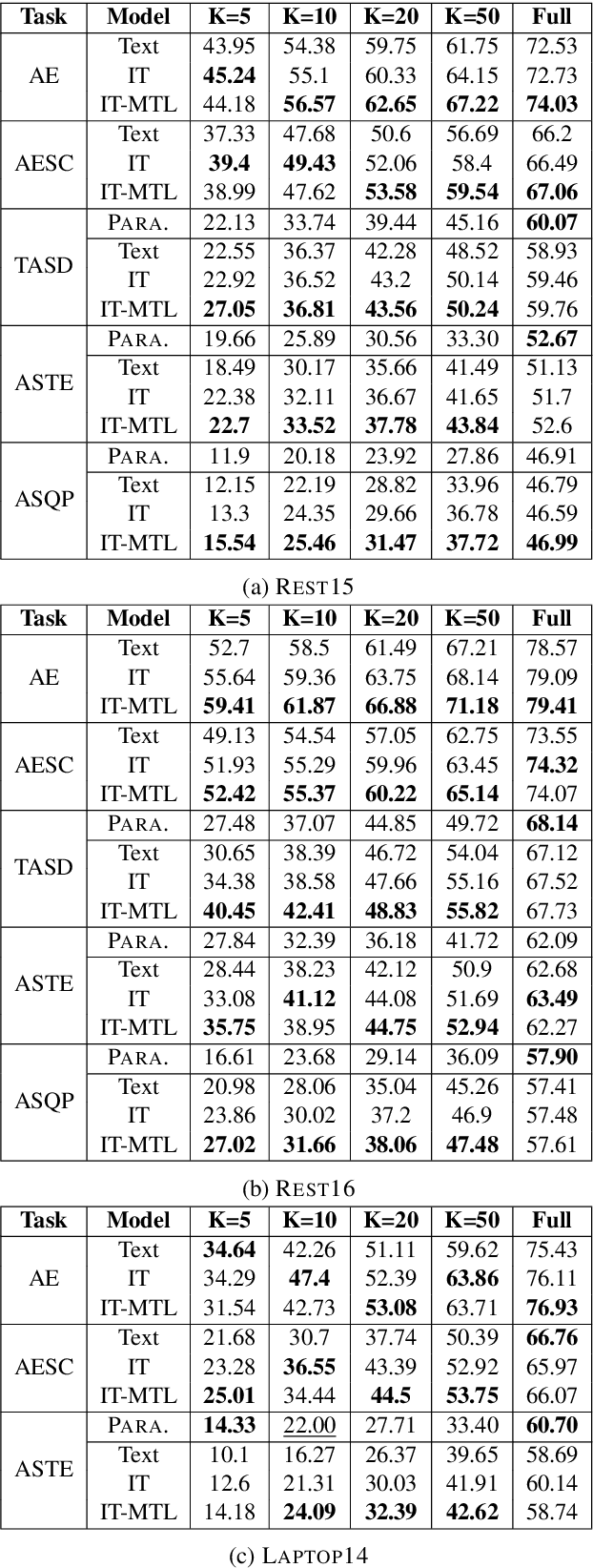
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.
FLUTE: Figurative Language Understanding and Textual Explanations
May 24, 2022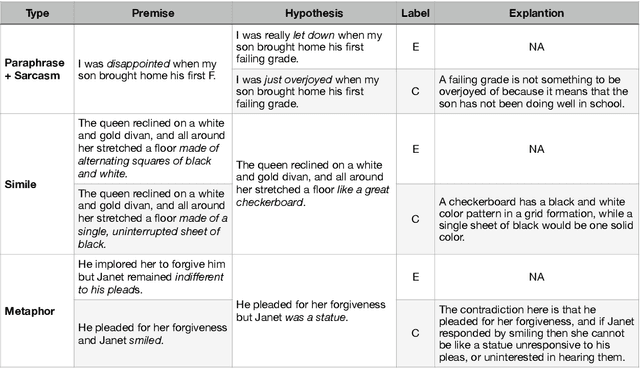
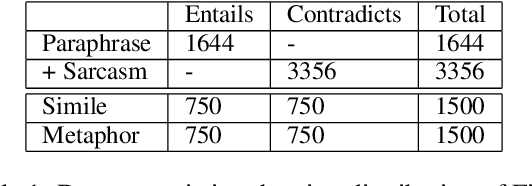

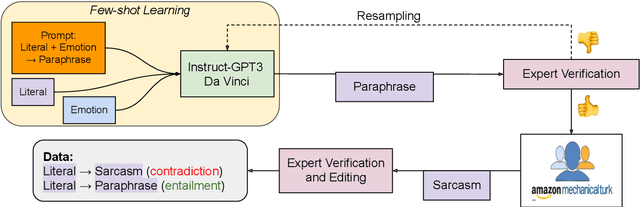
In spite of the prevalence of figurative language, transformer-based models struggle to demonstrate an understanding of it. Meanwhile, even classical natural language inference (NLI) tasks have been plagued by spurious correlations and annotation artifacts. Datasets like eSNLI have been released, allowing to probe whether language models are right for the right reasons. Yet no such data exists for figurative language, making it harder to asses genuine understanding of such expressions. In light of the above, we release FLUTE, a dataset of 8,000 figurative NLI instances with explanations, spanning three categories: Sarcasm, Simile, and Metaphor. We collect the data through the Human-AI collaboration framework based on GPT-3, crowdworkers, and expert annotation. We show how utilizing GPT-3 in conjunction with human experts can aid in scaling up the creation of datasets even for such complex linguistic phenomena as figurative language. Baseline performance of the T5 model shows our dataset is a challenging testbed for figurative language understanding.
Continual-T0: Progressively Instructing 50+ Tasks to Language Models Without Forgetting
May 24, 2022
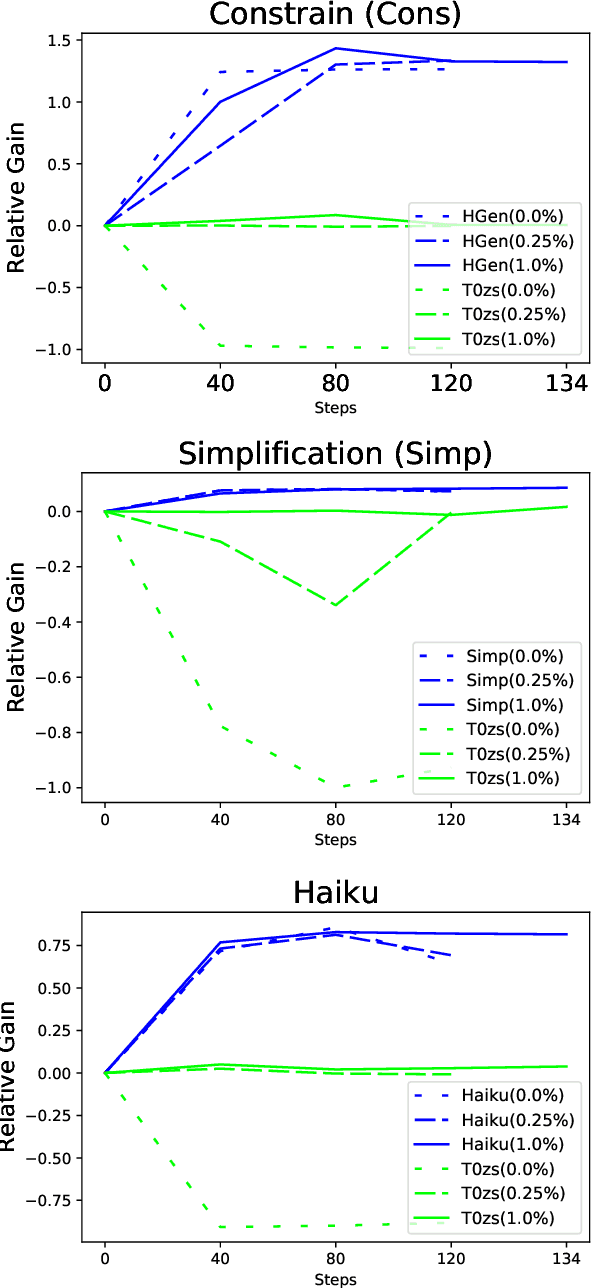
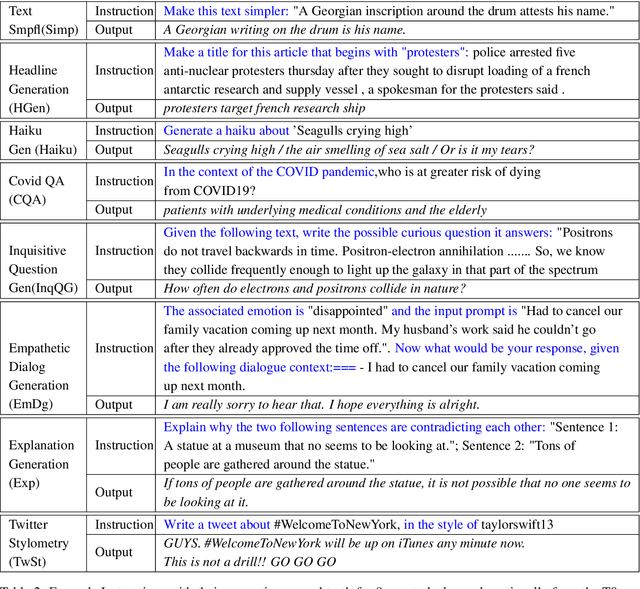
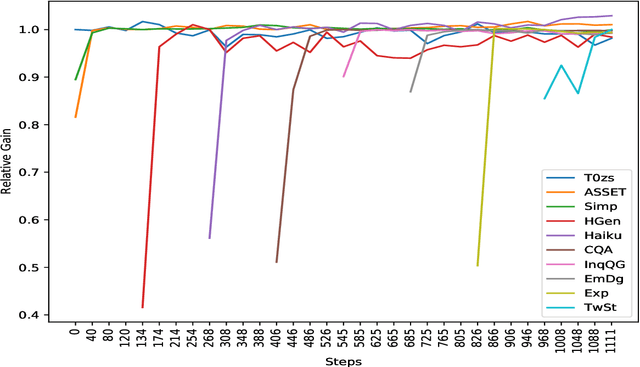
Recent work on large language models relies on the intuition that most natural language processing tasks can be described via natural language instructions. Language models trained on these instructions show strong zero-shot performance on several standard datasets. However, these models even though impressive still perform poorly on a wide range of tasks outside of their respective training and evaluation sets. To address this limitation, we argue that a model should be able to keep extending its knowledge and abilities, without forgetting previous skills. In spite of the limited success of Continual Learning we show that Language Models can be continual learners. We empirically investigate the reason for this success and conclude that Continual Learning emerges from self-supervision pre-training. Our resulting model Continual-T0 (CT0) is able to learn diverse new tasks, while still maintaining good performance on previous tasks, spanning remarkably through 70 datasets in total. Finally, we show that CT0 is able to combine instructions in ways it was never trained for, demonstrating some compositionality.
Implicit Premise Generation with Discourse-aware Commonsense Knowledge Models
Sep 11, 2021
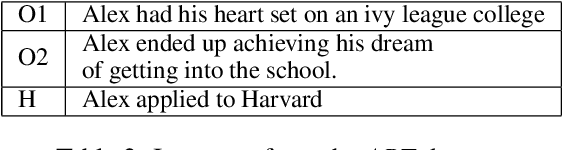
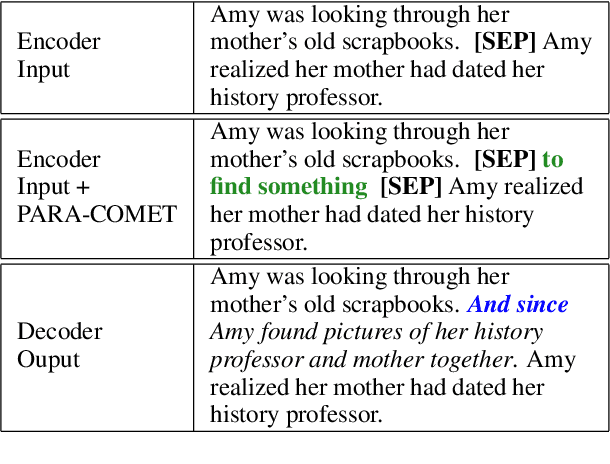
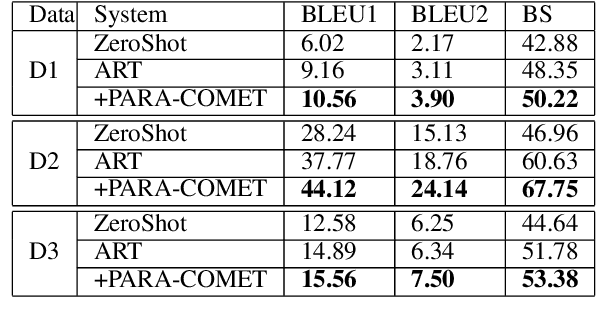
Enthymemes are defined as arguments where a premise or conclusion is left implicit. We tackle the task of generating the implicit premise in an enthymeme, which requires not only an understanding of the stated conclusion and premise but also additional inferences that could depend on commonsense knowledge. The largest available dataset for enthymemes (Habernal et al., 2018) consists of 1.7k samples, which is not large enough to train a neural text generation model. To address this issue, we take advantage of a similar task and dataset: Abductive reasoning in narrative text (Bhagavatula et al., 2020). However, we show that simply using a state-of-the-art seq2seq model fine-tuned on this data might not generate meaningful implicit premises associated with the given enthymemes. We demonstrate that encoding discourse-aware commonsense during fine-tuning improves the quality of the generated implicit premises and outperforms all other baselines both in automatic and human evaluations on three different datasets.
Don't Go Far Off: An Empirical Study on Neural Poetry Translation
Sep 10, 2021

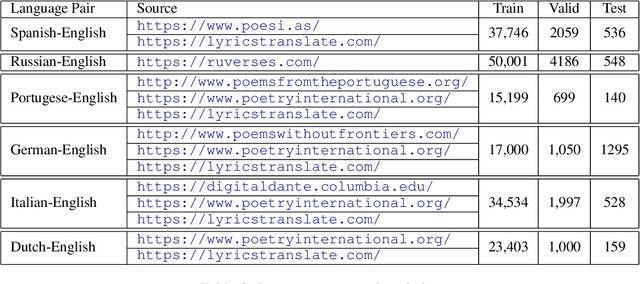

Despite constant improvements in machine translation quality, automatic poetry translation remains a challenging problem due to the lack of open-sourced parallel poetic corpora, and to the intrinsic complexities involved in preserving the semantics, style, and figurative nature of poetry. We present an empirical investigation for poetry translation along several dimensions: 1) size and style of training data (poetic vs. non-poetic), including a zero-shot setup; 2) bilingual vs. multilingual learning; and 3) language-family-specific models vs. mixed-multilingual models. To accomplish this, we contribute a parallel dataset of poetry translations for several language pairs. Our results show that multilingual fine-tuning on poetic text significantly outperforms multilingual fine-tuning on non-poetic text that is 35X larger in size, both in terms of automatic metrics (BLEU, BERTScore) and human evaluation metrics such as faithfulness (meaning and poetic style). Moreover, multilingual fine-tuning on poetic data outperforms \emph{bilingual} fine-tuning on poetic data.
Weakly-Supervised Methods for Suicide Risk Assessment: Role of Related Domains
Jun 21, 2021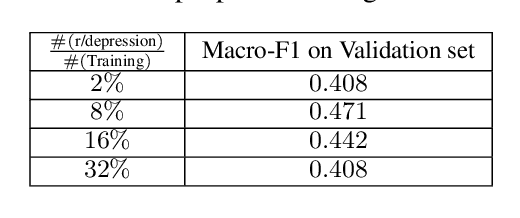
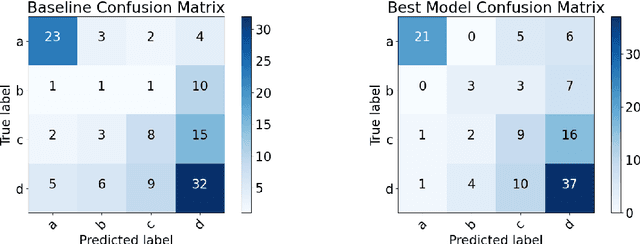
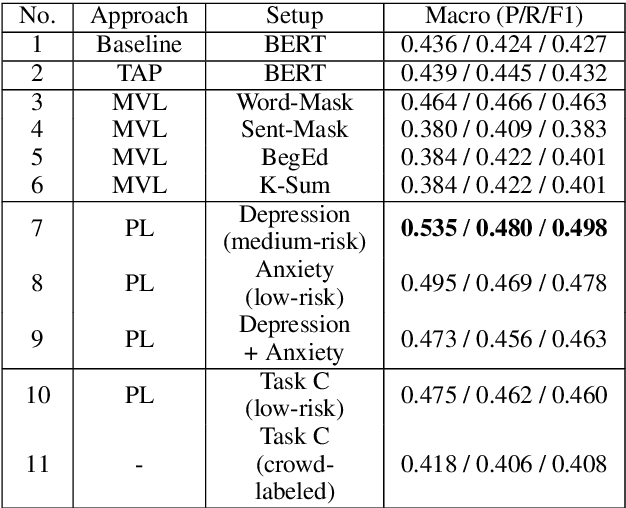
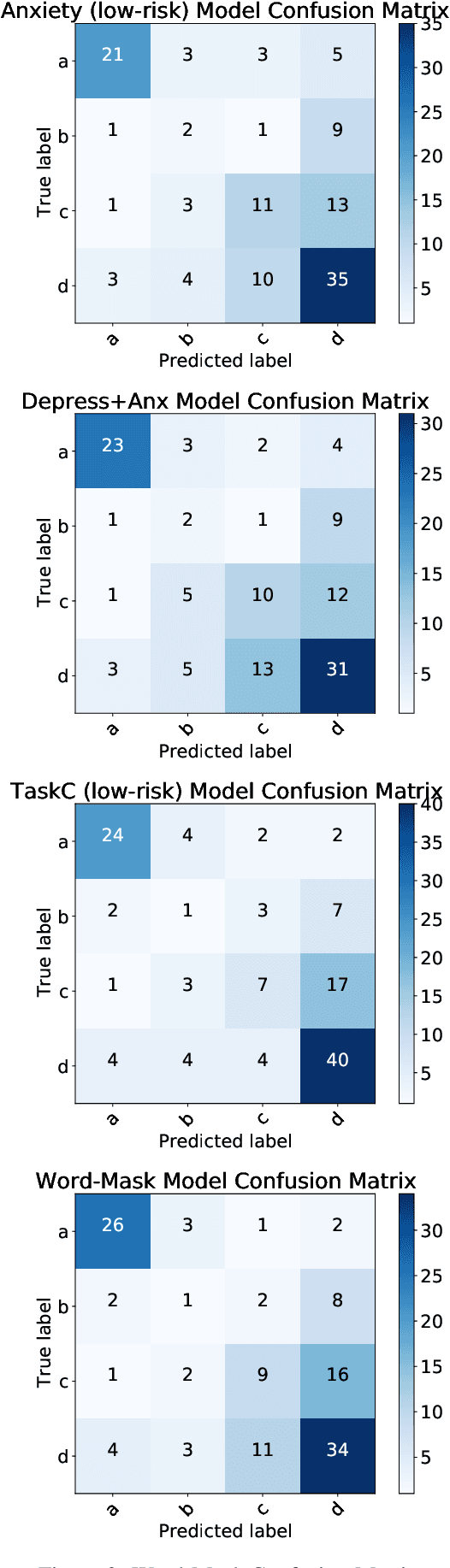
Social media has become a valuable resource for the study of suicidal ideation and the assessment of suicide risk. Among social media platforms, Reddit has emerged as the most promising one due to its anonymity and its focus on topic-based communities (subreddits) that can be indicative of someone's state of mind or interest regarding mental health disorders such as r/SuicideWatch, r/Anxiety, r/depression. A challenge for previous work on suicide risk assessment has been the small amount of labeled data. We propose an empirical investigation into several classes of weakly-supervised approaches, and show that using pseudo-labeling based on related issues around mental health (e.g., anxiety, depression) helps improve model performance for suicide risk assessment.
Multi-Task Learning and Adapted Knowledge Models for Emotion-Cause Extraction
Jun 17, 2021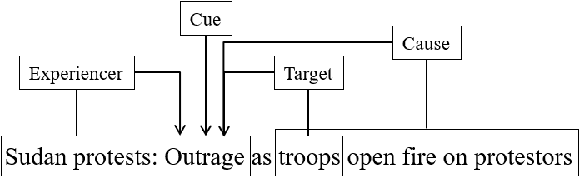
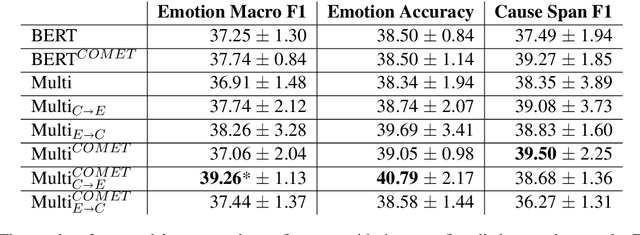
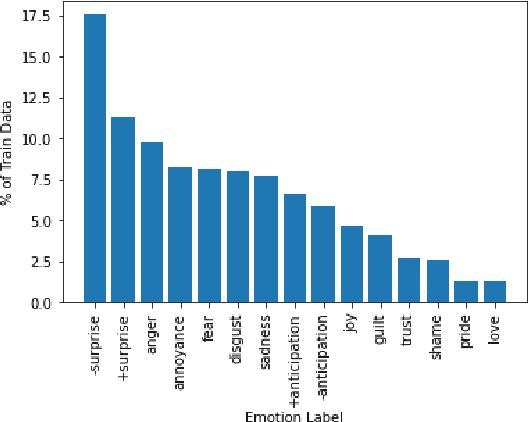

Detecting what emotions are expressed in text is a well-studied problem in natural language processing. However, research on finer grained emotion analysis such as what causes an emotion is still in its infancy. We present solutions that tackle both emotion recognition and emotion cause detection in a joint fashion. Considering that common-sense knowledge plays an important role in understanding implicitly expressed emotions and the reasons for those emotions, we propose novel methods that combine common-sense knowledge via adapted knowledge models with multi-task learning to perform joint emotion classification and emotion cause tagging. We show performance improvement on both tasks when including common-sense reasoning and a multitask framework. We provide a thorough analysis to gain insights into model performance.