 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Pose Graph Optimization via Bingham Distributions and Tempered Geodesic MCMC
Mar 30, 2019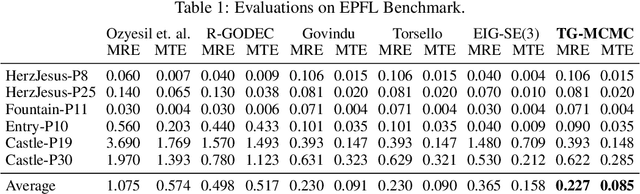


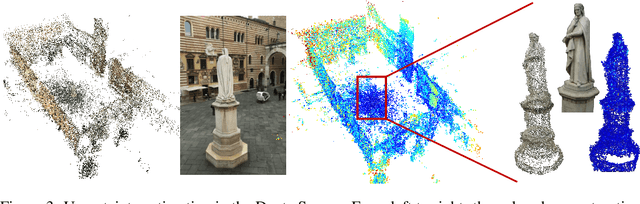
We introduce Tempered Geodesic Markov Chain Monte Carlo (TG-MCMC) algorithm for initializing pose graph optimization problems, arising in various scenarios such as SFM (structure from motion) or SLAM (simultaneous localization and mapping). TG-MCMC is first of its kind as it unites asymptotically global non-convex optimization on the spherical manifold of quaternions with posterior sampling, in order to provide both reliable initial poses and uncertainty estimates that are informative about the quality of individual solutions. We devise rigorous theoretical convergence guarantees for our method and extensively evaluate it on synthetic and real benchmark datasets. Besides its elegance in formulation and theory, we show that our method is robust to missing data, noise and the estimated uncertainties capture intuitive properties of the data.
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

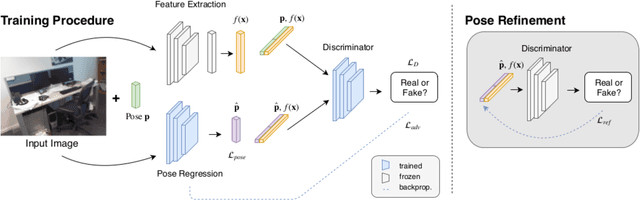
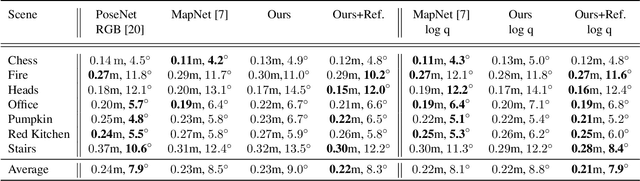
Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
Generic Primitive Detection in Point Clouds Using Novel Minimal Quadric Fits
Jan 04, 2019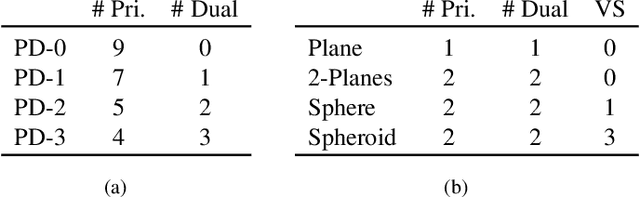
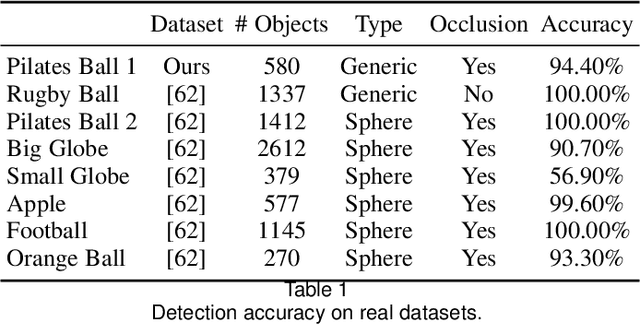
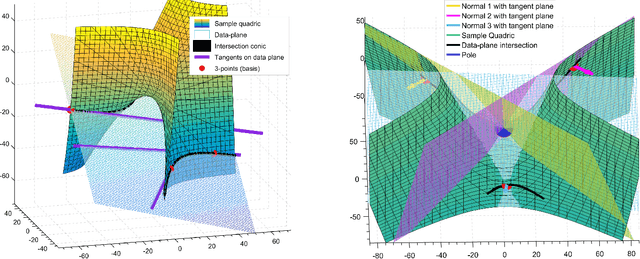
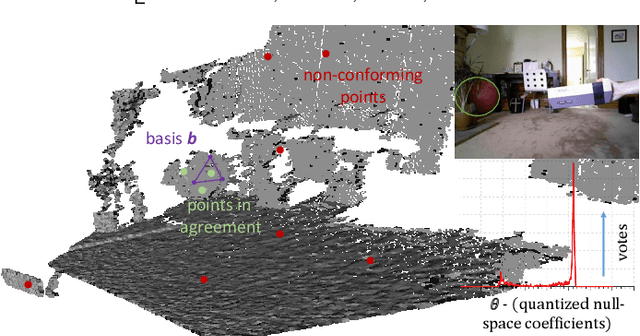
We present a novel and effective method for detecting 3D primitives in cluttered, unorganized point clouds, without axillary segmentation or type specification. We consider the quadric surfaces for encapsulating the basic building blocks of our environments - planes, spheres, ellipsoids, cones or cylinders, in a unified fashion. Moreover, quadrics allow us to model higher degree of freedom shapes, such as hyperboloids or paraboloids that could be used in non-rigid settings. We begin by contributing two novel quadric fits targeting 3D point sets that are endowed with tangent space information. Based upon the idea of aligning the quadric gradients with the surface normals, our first formulation is exact and requires as low as four oriented points. The second fit approximates the first, and reduces the computational effort. We theoretically analyze these fits with rigor, and give algebraic and geometric arguments. Next, by re-parameterizing the solution, we devise a new local Hough voting scheme on the null-space coefficients that is combined with RANSAC, reducing the complexity from $O(N^4)$ to $O(N^3)$ (three points). To the best of our knowledge, this is the first method capable of performing a generic cross-type multi-object primitive detection in difficult scenes without segmentation. Our extensive qualitative and quantitative results show that our method is efficient and flexible, as well as being accurate.
Seeing Beyond Appearance - Mapping Real Images into Geometrical Domains for Unsupervised CAD-based Recognition
Oct 09, 2018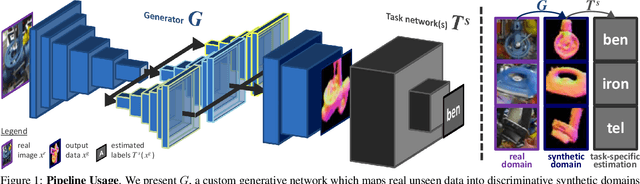

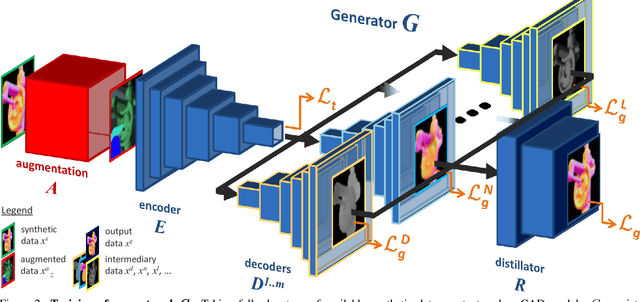

While convolutional neural networks are dominating the field of computer vision, one usually does not have access to the large amount of domain-relevant data needed for their training. It thus became common to use available synthetic samples along domain adaptation schemes to prepare algorithms for the target domain. Tackling this problem from a different angle, we introduce a pipeline to map unseen target samples into the synthetic domain used to train task-specific methods. Denoising the data and retaining only the features these recognition algorithms are familiar with, our solution greatly improves their performance. As this mapping is easier to learn than the opposite one (ie to learn to generate realistic features to augment the source samples), we demonstrate how our whole solution can be trained purely on augmented synthetic data, and still perform better than methods trained with domain-relevant information (eg real images or realistic textures for the 3D models). Applying our approach to object recognition from texture-less CAD data, we present a custom generative network which fully utilizes the purely geometrical information to learn robust features and achieve a more refined mapping for unseen color images.
PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors
Aug 30, 2018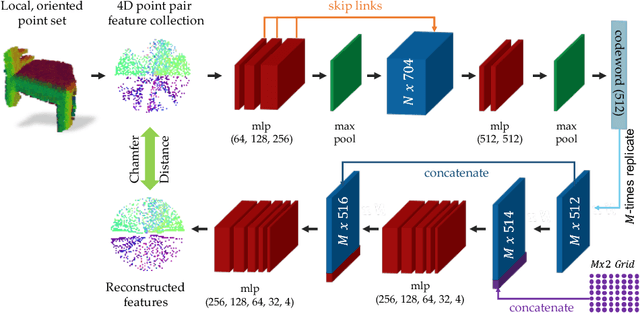
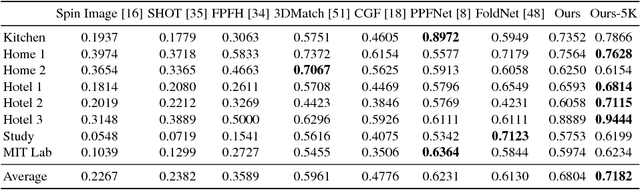
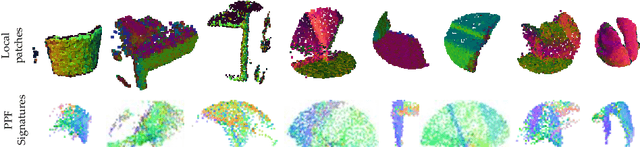
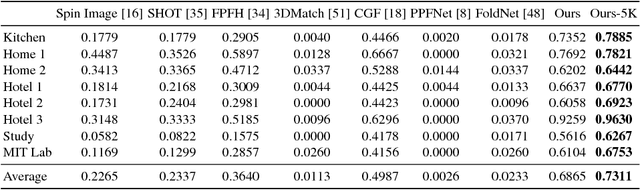
We present PPF-FoldNet for unsupervised learning of 3D local descriptors on pure point cloud geometry. Based on the folding-based auto-encoding of well known point pair features, PPF-FoldNet offers many desirable properties: it necessitates neither supervision, nor a sensitive local reference frame, benefits from point-set sparsity, is end-to-end, fast, and can extract powerful rotation invariant descriptors. Thanks to a novel feature visualization, its evolution can be monitored to provide interpretable insights. Our extensive experiments demonstrate that despite having six degree-of-freedom invariance and lack of training labels, our network achieves state of the art results in standard benchmark datasets and outperforms its competitors when rotations and varying point densities are present. PPF-FoldNet achieves $9\%$ higher recall on standard benchmarks, $23\%$ higher recall when rotations are introduced into the same datasets and finally, a margin of $>35\%$ is attained when point density is significantly decreased.
Scene Coordinate and Correspondence Learning for Image-Based Localization
Jul 26, 2018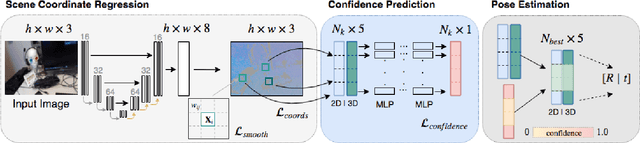
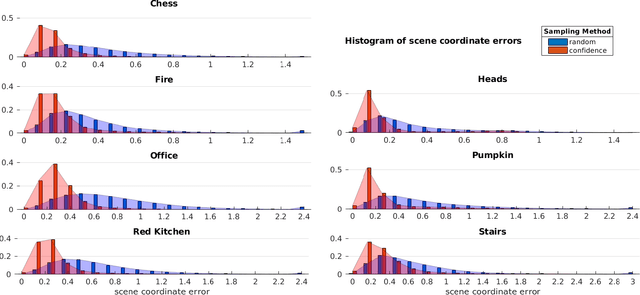

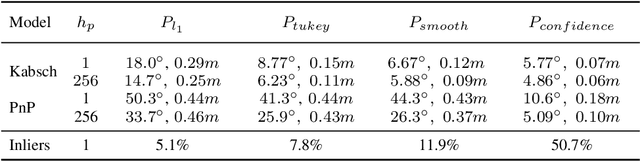
Scene coordinate regression has become an essential part of current camera re-localization methods. Different versions, such as regression forests and deep learning methods, have been successfully applied to estimate the corresponding camera pose given a single input image. In this work, we propose to regress the scene coordinates pixel-wise for a given RGB image by using deep learning. Compared to the recent methods, which usually employ RANSAC to obtain a robust pose estimate from the established point correspondences, we propose to regress confidences of these correspondences, which allows us to immediately discard erroneous predictions and improve the initial pose estimates. Finally, the resulting confidences can be used to score initial pose hypothesis and aid in pose refinement, offering a generalized solution to solve this task.
Keep it Unreal: Bridging the Realism Gap for 2.5D Recognition with Geometry Priors Only
May 24, 2018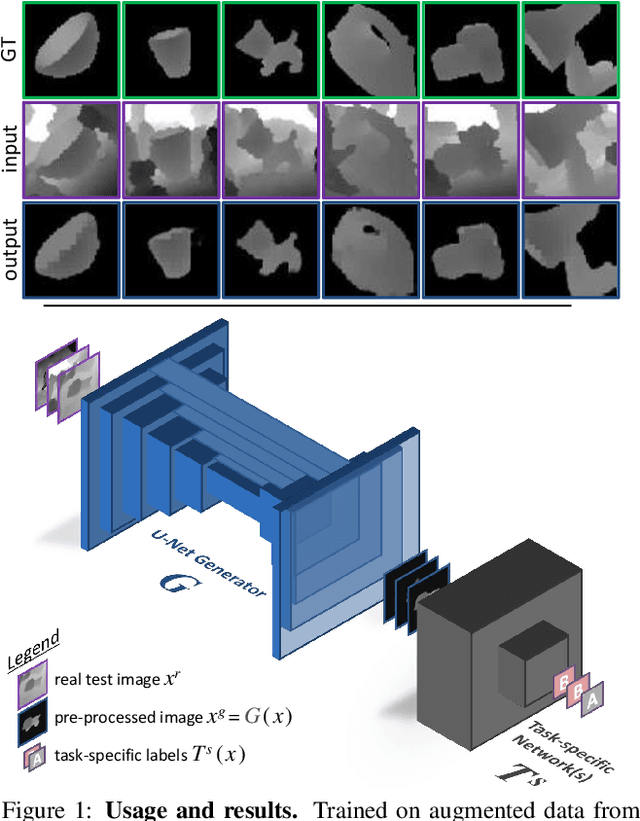
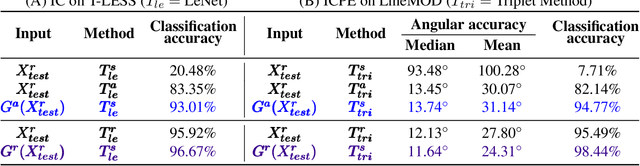
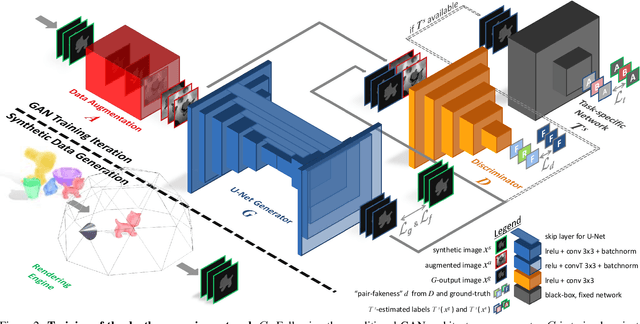
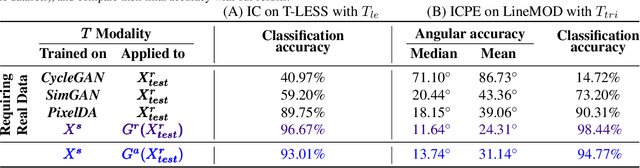
With the increasing availability of large databases of 3D CAD models, depth-based recognition methods can be trained on an uncountable number of synthetically rendered images. However, discrepancies with the real data acquired from various depth sensors still noticeably impede progress. Previous works adopted unsupervised approaches to generate more realistic depth data, but they all require real scans for training, even if unlabeled. This still represents a strong requirement, especially when considering real-life/industrial settings where real training images are hard or impossible to acquire, but texture-less 3D models are available. We thus propose a novel approach leveraging only CAD models to bridge the realism gap. Purely trained on synthetic data, playing against an extensive augmentation pipeline in an unsupervised manner, our generative adversarial network learns to effectively segment depth images and recover the clean synthetic-looking depth information even from partial occlusions. As our solution is not only fully decoupled from the real domains but also from the task-specific analytics, the pre-processed scans can be handed to any kind and number of recognition methods also trained on synthetic data. Through various experiments, we demonstrate how this simplifies their training and consistently enhances their performance, with results on par with the same methods trained on real data, and better than usual approaches doing the reverse mapping.
When Regression Meets Manifold Learning for Object Recognition and Pose Estimation
May 16, 2018
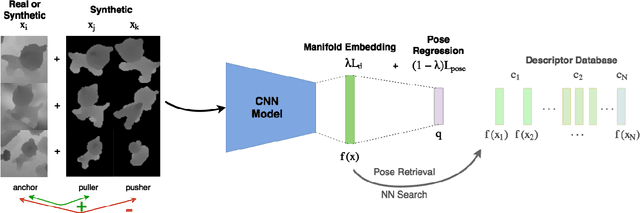
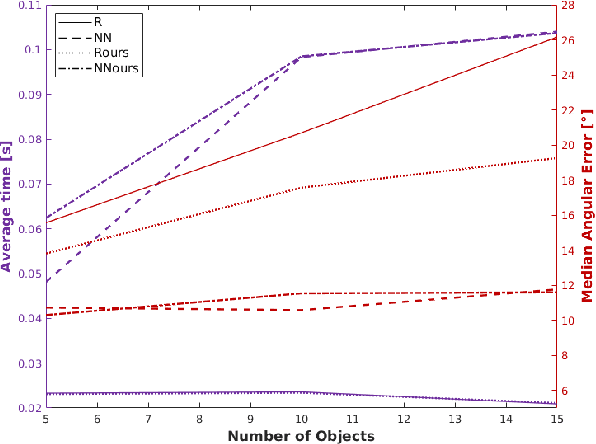
In this work, we propose a method for object recognition and pose estimation from depth images using convolutional neural networks. Previous methods addressing this problem rely on manifold learning to learn low dimensional viewpoint descriptors and employ them in a nearest neighbor search on an estimated descriptor space. In comparison we create an efficient multi-task learning framework combining manifold descriptor learning and pose regression. By combining the strengths of manifold learning using triplet loss and pose regression, we could either estimate the pose directly reducing the complexity compared to NN search, or use learned descriptor for the NN descriptor matching. By in depth experimental evaluation of the novel loss function we observed that the view descriptors learned by the network are much more discriminative resulting in almost 30% increase regarding relative pose accuracy compared to related works. On the other hand, regarding directly regressed poses we obtained important improvement compared to simple pose regression. By leveraging the advantages of both manifold learning and regression tasks, we are able to improve the current state-of-the-art for object recognition and pose retrieval that we demonstrate through in depth experimental evaluation.
A Minimalist Approach to Type-Agnostic Detection of Quadrics in Point Clouds
Mar 19, 2018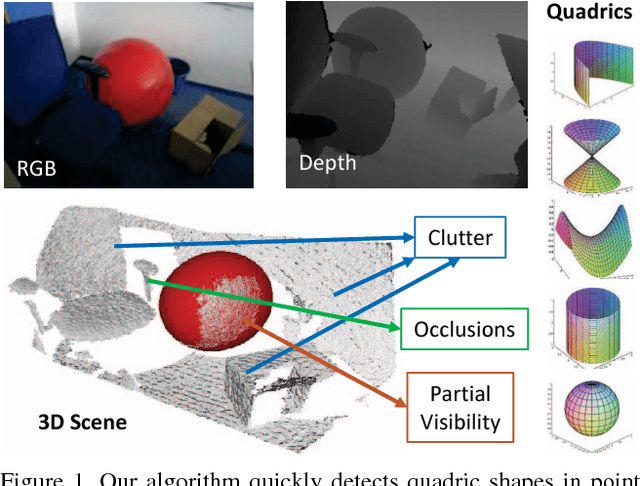
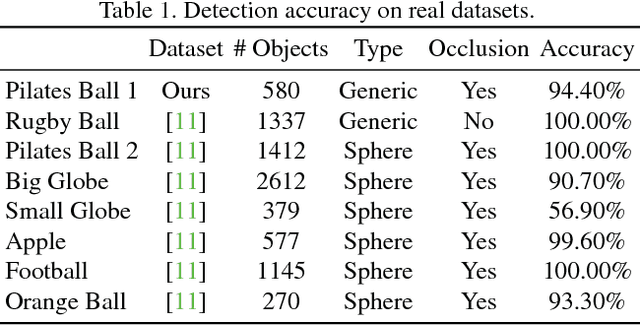
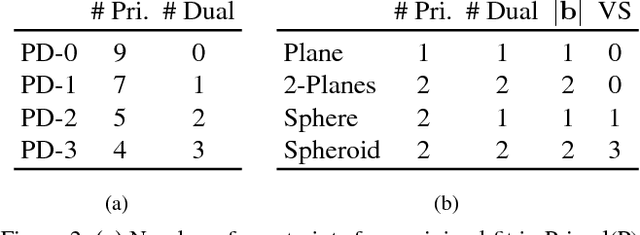
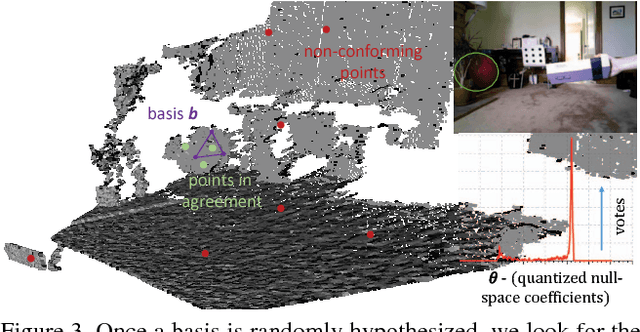
This paper proposes a segmentation-free, automatic and efficient procedure to detect general geometric quadric forms in point clouds, where clutter and occlusions are inevitable. Our everyday world is dominated by man-made objects which are designed using 3D primitives (such as planes, cones, spheres, cylinders, etc.). These objects are also omnipresent in industrial environments. This gives rise to the possibility of abstracting 3D scenes through primitives, thereby positions these geometric forms as an integral part of perception and high level 3D scene understanding. As opposed to state-of-the-art, where a tailored algorithm treats each primitive type separately, we propose to encapsulate all types in a single robust detection procedure. At the center of our approach lies a closed form 3D quadric fit, operating in both primal & dual spaces and requiring as low as 4 oriented-points. Around this fit, we design a novel, local null-space voting strategy to reduce the 4-point case to 3. Voting is coupled with the famous RANSAC and makes our algorithm orders of magnitude faster than its conventional counterparts. This is the first method capable of performing a generic cross-type multi-object primitive detection in difficult scenes. Results on synthetic and real datasets support the validity of our method.
PPFNet: Global Context Aware Local Features for Robust 3D Point Matching
Mar 01, 2018
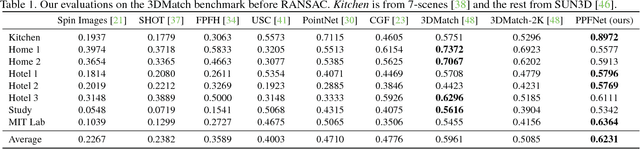


We present PPFNet - Point Pair Feature NETwork for deeply learning a globally informed 3D local feature descriptor to find correspondences in unorganized point clouds. PPFNet learns local descriptors on pure geometry and is highly aware of the global context, an important cue in deep learning. Our 3D representation is computed as a collection of point-pair-features combined with the points and normals within a local vicinity. Our permutation invariant network design is inspired by PointNet and sets PPFNet to be ordering-free. As opposed to voxelization, our method is able to consume raw point clouds to exploit the full sparsity. PPFNet uses a novel $\textit{N-tuple}$ loss and architecture injecting the global information naturally into the local descriptor. It shows that context awareness also boosts the local feature representation. Qualitative and quantitative evaluations of our network suggest increased recall, improved robustness and invariance as well as a vital step in the 3D descriptor extraction performance.