 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Object Detection and Pose Estimation of Unseen Objects in Color Images with Local Surface Embeddings
Oct 08, 2020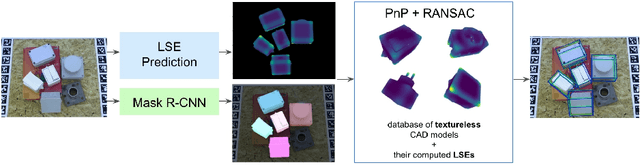


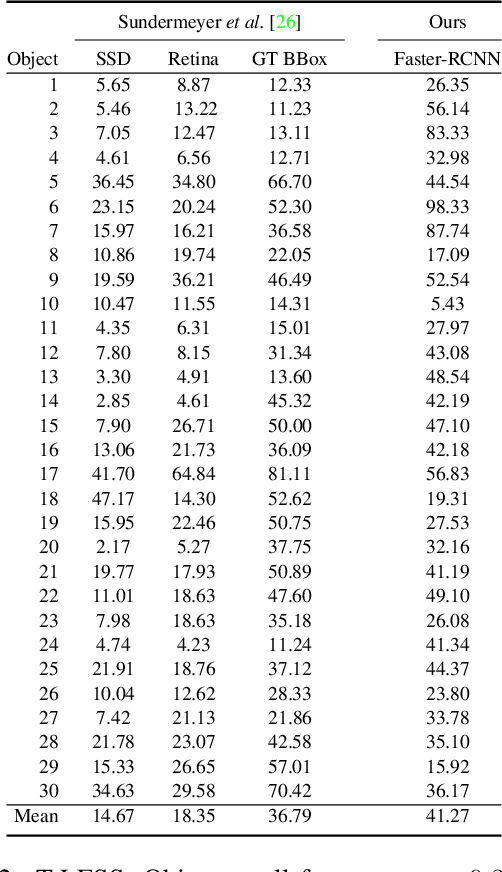
We present an approach for detecting and estimating the 3D poses of objects in images that requires only an untextured CAD model and no training phase for new objects. Our approach combines Deep Learning and 3D geometry: It relies on an embedding of local 3D geometry to match the CAD models to the input images. For points at the surface of objects, this embedding can be computed directly from the CAD model; for image locations, we learn to predict it from the image itself. This establishes correspondences between 3D points on the CAD model and 2D locations of the input images. However, many of these correspondences are ambiguous as many points may have similar local geometries. We show that we can use Mask-RCNN in a class-agnostic way to detect the new objects without retraining and thus drastically limit the number of possible correspondences. We can then robustly estimate a 3D pose from these discriminative correspondences using a RANSAC- like algorithm. We demonstrate the performance of this approach on the T-LESS dataset, by using a small number of objects to learn the embedding and testing it on the other objects. Our experiments show that our method is on par or better than previous methods.
6D Camera Relocalization in Ambiguous Scenes via Continuous Multimodal Inference
Apr 09, 2020
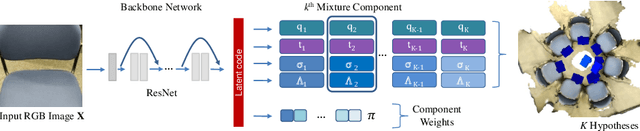
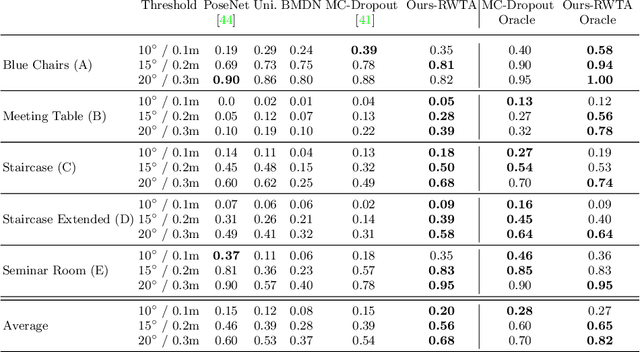
We present a multimodal camera relocalization framework that captures ambiguities and uncertainties with continuous mixture models defined on the manifold of camera poses. In highly ambiguous environments, which can easily arise due to symmetries and repetitive structures in the scene, computing one plausible solution (what most state-of-the-art methods currently regress) may not be sufficient. Instead we predict multiple camera pose hypotheses as well as the respective uncertainty for each prediction. Towards this aim, we use Bingham distributions, to model the orientation of the camera pose, and a multivariate Gaussian to model the position, with an end-to-end deep neural network. By incorporating a Winner-Takes-All training scheme, we finally obtain a mixture model that is well suited for explaining ambiguities in the scene, yet does not suffer from mode collapse, a common problem with mixture density networks. We introduce a new dataset specifically designed to foster camera localization research in ambiguous environments and exhaustively evaluate our method on synthetic as well as real data on both ambiguous scenes and on non-ambiguous benchmark datasets. We plan to release our code and dataset under $\href{https://multimodal3dvision.github.io}{multimodal3dvision.github.io}$.
Real-Time 3D Model Tracking in Color and Depth on a Single CPU Core
Nov 22, 2019

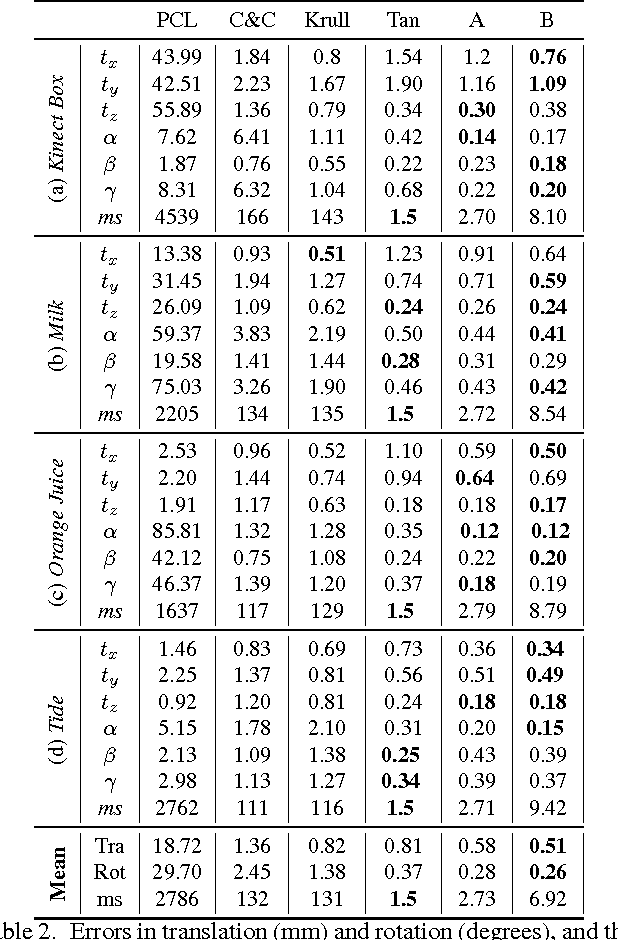
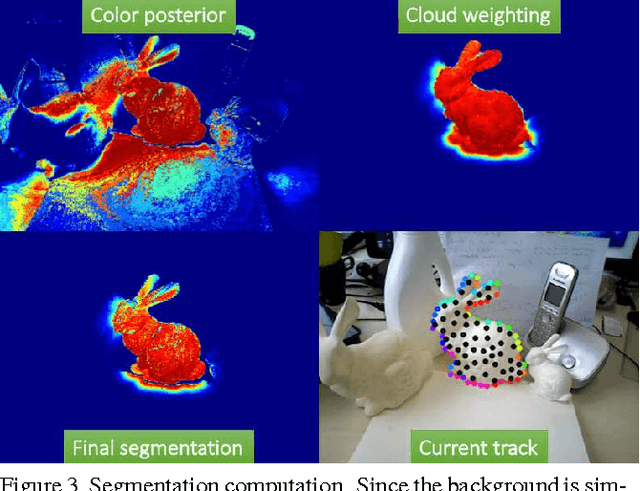
We present a novel method to track 3D models in color and depth data. To this end, we introduce approximations that accelerate the state-of-the-art in region-based tracking by an order of magnitude while retaining similar accuracy. Furthermore, we show how the method can be made more robust in the presence of depth data and consequently formulate a new joint contour and ICP tracking energy. We present better results than the state-of-the-art while being much faster then most other methods and achieving all of the above on a single CPU core.
CorNet: Generic 3D Corners for 6D Pose Estimation of New Objects without Retraining
Aug 29, 2019
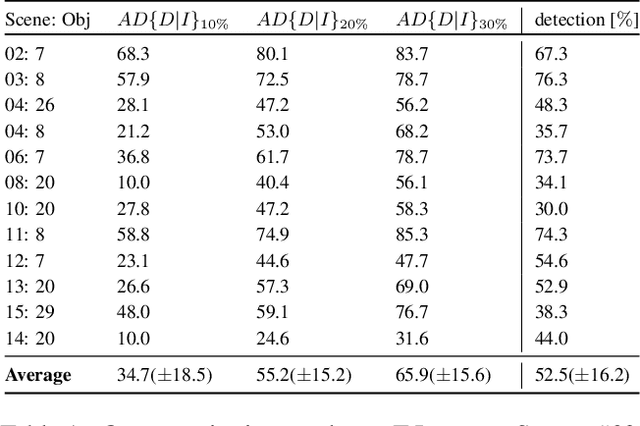
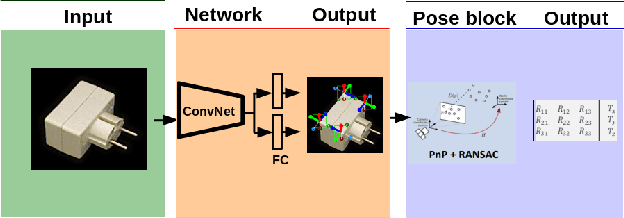
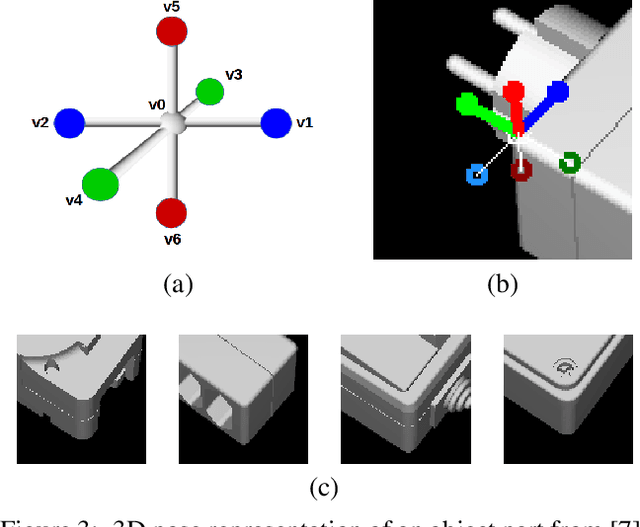
We present a novel approach to the detection and 3D pose estimation of objects in color images. Its main contribution is that it does not require any training phases nor data for new objects, while state-of-the-art methods typically require hours of training time and hundreds of training registered images. Instead, our method relies only on the objects' geometries. Our method focuses on objects with prominent corners, which covers a large number of industrial objects. We first learn to detect object corners of various shapes in images and also to predict their 3D poses, by using training images of a small set of objects. To detect a new object in a given image, we first identify its corners from its CAD model; we also detect the corners visible in the image and predict their 3D poses. We then introduce a RANSAC-like algorithm that robustly and efficiently detects and estimates the object's 3D pose by matching its corners on the CAD model with their detected counterparts in the image. Because we also estimate the 3D poses of the corners in the image, detecting only 1 or 2 corners is sufficient to estimate the pose of the object, which makes the approach robust to occlusions. We finally rely on a final check that exploits the full 3D geometry of the objects, in case multiple objects have the same corner spatial arrangement. The advantages of our approach make it particularly attractive for industrial contexts, and we demonstrate our approach on the challenging T-LESS dataset.
On Object Symmetries and 6D Pose Estimation from Images
Aug 20, 2019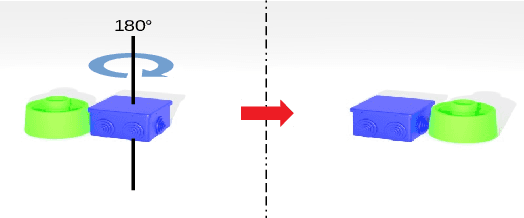
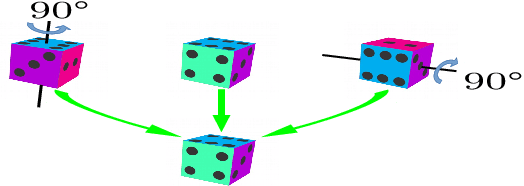
Objects with symmetries are common in our daily life and in industrial contexts, but are often ignored in the recent literature on 6D pose estimation from images. In this paper, we study in an analytical way the link between the symmetries of a 3D object and its appearance in images. We explain why symmetrical objects can be a challenge when training machine learning algorithms that aim at estimating their 6D pose from images. We propose an efficient and simple solution that relies on the normalization of the pose rotation. Our approach is general and can be used with any 6D pose estimation algorithm. Moreover, our method is also beneficial for objects that are 'almost symmetrical', i.e. objects for which only a detail breaks the symmetry. We validate our approach within a Faster-RCNN framework on a synthetic dataset made with objects from the T-Less dataset, which exhibit various types of symmetries, as well as real sequences from T-Less.
3D Object Instance Recognition and Pose Estimation Using Triplet Loss with Dynamic Margin
Apr 09, 2019
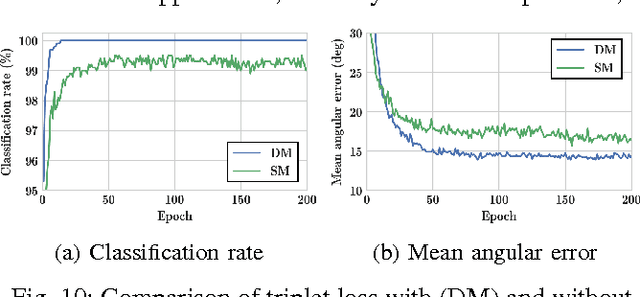
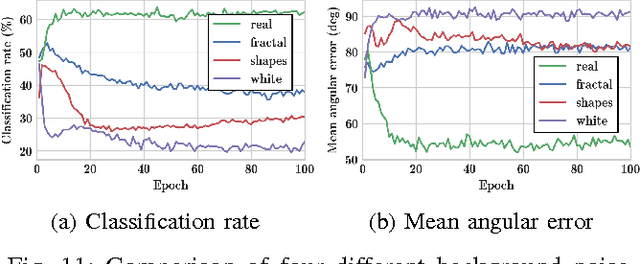

In this paper, we address the problem of 3D object instance recognition and pose estimation of localized objects in cluttered environments using convolutional neural networks. Inspired by the descriptor learning approach of Wohlhart et al., we propose a method that introduces the dynamic margin in the manifold learning triplet loss function. Such a loss function is designed to map images of different objects under different poses to a lower-dimensional, similarity-preserving descriptor space on which efficient nearest neighbor search algorithms can be applied. Introducing the dynamic margin allows for faster training times and better accuracy of the resulting low-dimensional manifolds. Furthermore, we contribute the following: adding in-plane rotations (ignored by the baseline method) to the training, proposing new background noise types that help to better mimic realistic scenarios and improve accuracy with respect to clutter, adding surface normals as another powerful image modality representing an object surface leading to better performance than merely depth, and finally implementing an efficient online batch generation that allows for better variability during the training phase. We perform an exhaustive evaluation to demonstrate the effects of our contributions. Additionally, we assess the performance of the algorithm on the large BigBIRD dataset to demonstrate good scalability properties of the pipeline with respect to the number of models.
3D Local Features for Direct Pairwise Registration
Apr 08, 2019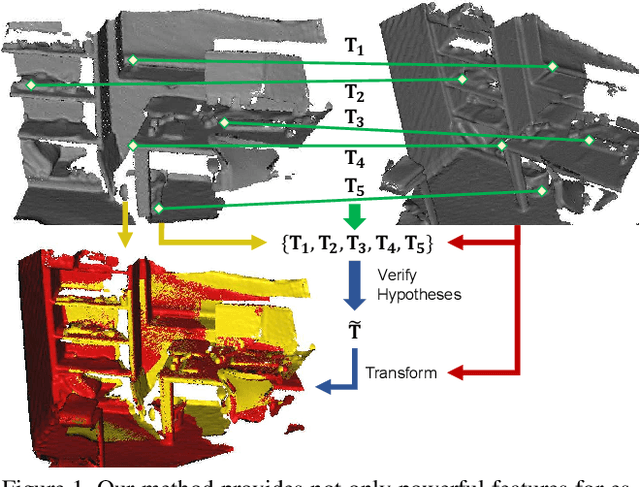
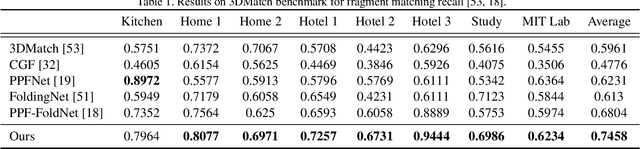
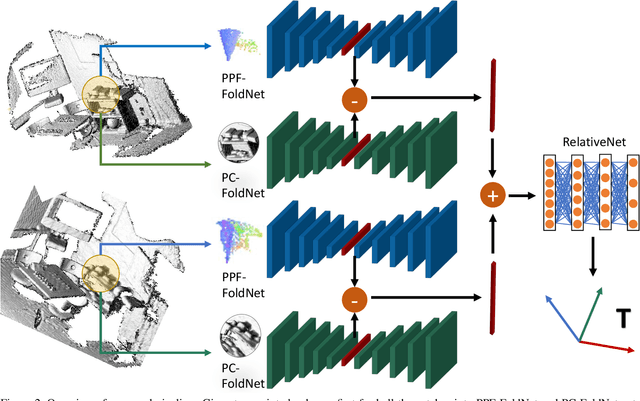
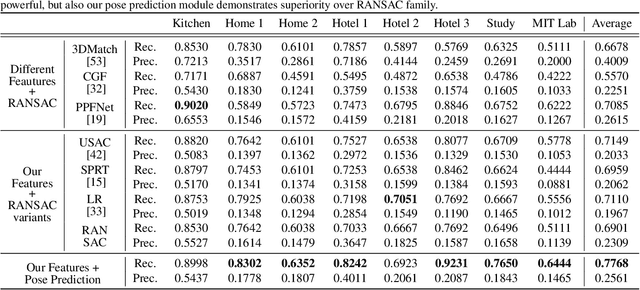
We present a novel, data driven approach for solving the problem of registration of two point cloud scans. Our approach is direct in the sense that a single pair of corresponding local patches already provides the necessary transformation cue for the global registration. To achieve that, we first endow the state of the art PPF-FoldNet auto-encoder (AE) with a pose-variant sibling, where the discrepancy between the two leads to pose-specific descriptors. Based upon this, we introduce RelativeNet, a relative pose estimation network to assign correspondence-specific orientations to the keypoints, eliminating any local reference frame computations. Finally, we devise a simple yet effective hypothesize-and-verify algorithm to quickly use the predictions and align two point sets. Our extensive quantitative and qualitative experiments suggests that our approach outperforms the state of the art in challenging real datasets of pairwise registration and that augmenting the keypoints with local pose information leads to better generalization and a dramatic speed-up.
DPOD: 6D Pose Object Detector and Refiner
Apr 08, 2019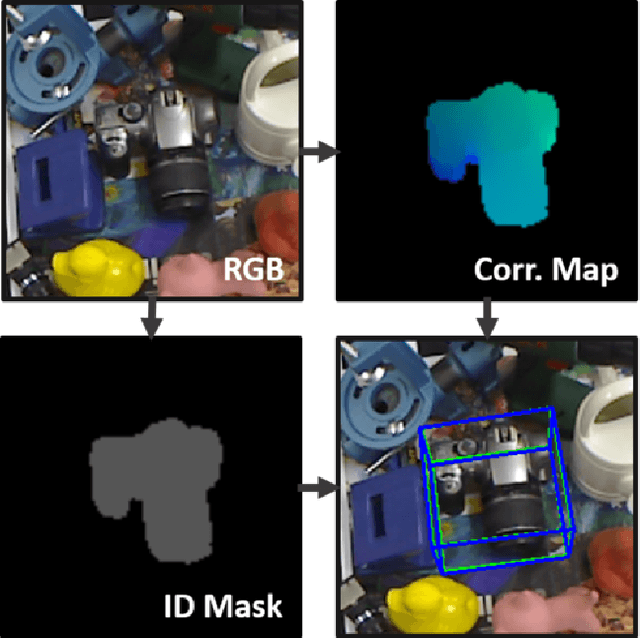
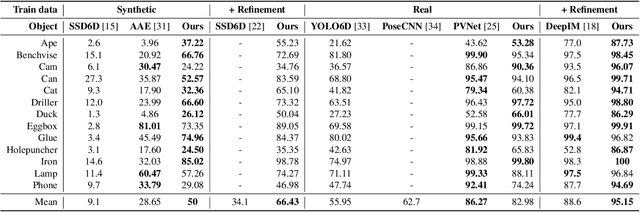
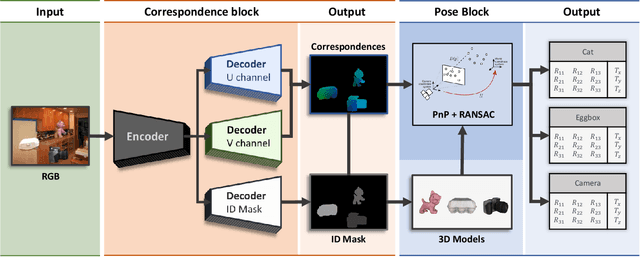

In this paper we present a novel deep learning method for 3D object detection and 6D pose estimation from RGB images. Our method, named DPOD (Dense Pose Object Detector), estimates dense multi-class 2D-3D correspondence maps between an input image and available 3D models. Given the correspondences, a 6DoF pose is computed via PnP and RANSAC. An additional RGB pose refinement of the initial pose estimates is performed using a custom deep learning based refinement scheme. Our results and comparison to a vast number of related works demonstrate that a large number of correspondences is beneficial for obtaining high quality 6D poses both before and after refinement. Unlike other methods that mainly use real data for training and do not train on synthetic renderings, we perform evaluation on both synthetic and real training data demonstrating superior results before and after refinement when compared to all recent detectors. While being precise, the presented approach is still real-time capable.
HomebrewedDB: RGB-D Dataset for 6D Pose Estimation of 3D Objects
Apr 05, 2019


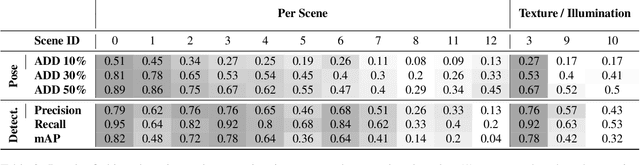
One of the most important prerequisites for creating and evaluating 6D object pose detectors are datasets with labeled 6D poses. In the advent of deep learning methods, demand for such datasets is consinuously arising. Despite the fact that some of those exist, they are scarce and typically have restricted setups, e.g. a single object per sequence, or focus on specific object types, such as textureless industrial parts. Besides, two significant components are often ignored: training only from available 3D models instead of real data and scalability, i.e. training one method to detect all objects rather than training one detector per object. Other challenges, such as occlusions, changing light conditions and object appearance changes, as well as precisely defined benchmarks are either not present or scattered among different datasets. In this paper we present dataset for 6D pose estimation that covers the above-mentioned challenges, mainly targeting training from 3D models (both textured and textureless), scalability, occlusions, light and object appearance changes. The dataset features 33 objects (17 toy, 8 household and 8 industry-relevant objects) over 13 scenes of various difficulty. Moreover, we present a set benchmarks with the purpose of testing various desired properties of the detectors, particularly focusing on scalability with respect to the number of objects, resistance to changing light conditions, occlusions and clutter. We also set a baseline for the presented benchmarks using a publicly available state of the art detector. Considering difficulties in making such datasets, we plan to release the code allowing other researchers to extend this dataset or make their own datasets in the future.
DeceptionNet: Network-Driven Domain Randomization
Apr 04, 2019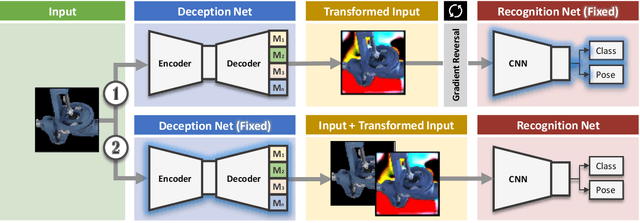
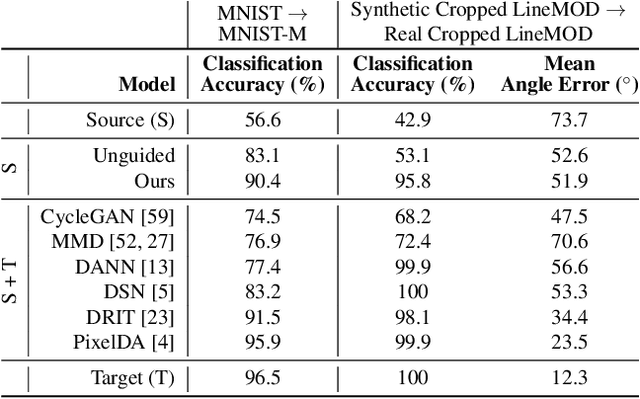
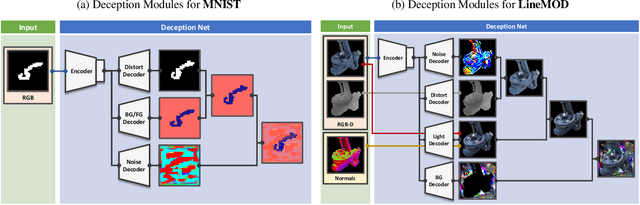
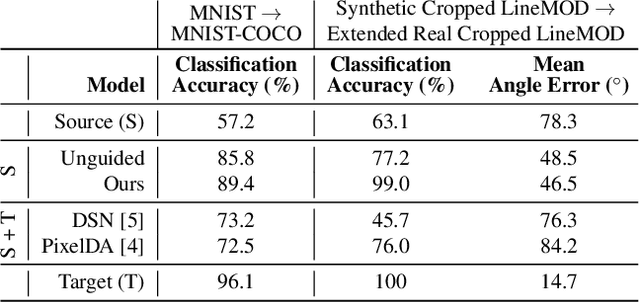
We present a novel approach to tackle domain adaptation between synthetic and real data. Instead of employing 'blind' domain randomization, i.e. augmenting synthetic renderings with random backgrounds or changing illumination and colorization, we leverage the task network as its own adversarial guide towards useful augmentations that maximize the uncertainty of the output. To this end, we design a min-max optimization scheme where a given task competes against a special deception network, with the goal of minimizing the task error subject to specific constraints enforced by the deceiver. The deception network samples from a family of differentiable pixel-level perturbations and exploits the task architecture to find the most destructive augmentations. Unlike GAN-based approaches that require unlabeled data from the target domain, our method achieves robust mappings that scale well to multiple target distributions from source data alone. We apply our framework to the tasks of digit recognition on enhanced MNIST variants as well as classification and object pose estimation on the Cropped LineMOD dataset and compare to a number of domain adaptation approaches, demonstrating similar results with superior generalization capabilities.