 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Role of Data Quality in Training Bilingual Language Models
Jun 15, 2025



Bilingual and multilingual language models offer a promising path toward scaling NLP systems across diverse languages and users. However, their performance often varies wildly between languages as prior works show that adding more languages can degrade performance for some languages (such as English), while improving others (typically more data constrained languages). In this work, we investigate causes of these inconsistencies by comparing bilingual and monolingual language models. Our analysis reveals that unequal data quality, not just data quantity, is a major driver of performance degradation in bilingual settings. We propose a simple yet effective data filtering strategy to select higher-quality bilingual training data with only high quality English data. Applied to French, German, and Chinese, our approach improves monolingual performance by 2-4% and reduces bilingual model performance gaps to 1%. These results highlight the overlooked importance of data quality in multilingual pretraining and offer a practical recipe for balancing performance.
Proxy-FDA: Proxy-based Feature Distribution Alignment for Fine-tuning Vision Foundation Models without Forgetting
May 30, 2025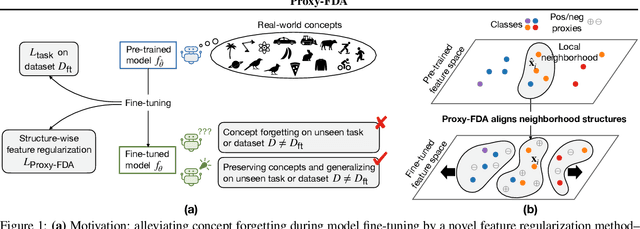
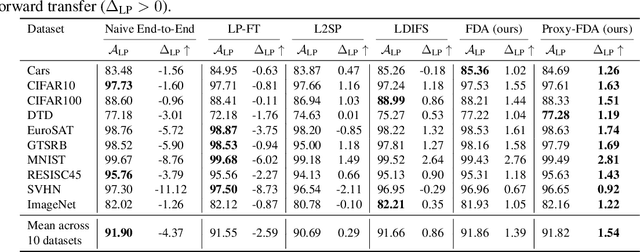
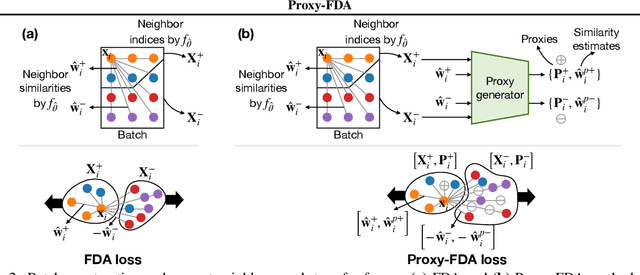
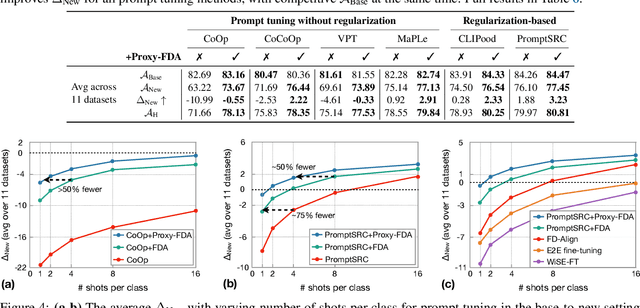
Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the feature neighborhood structures that encode rich knowledge as well. We propose a novel regularization method Proxy-FDA that explicitly preserves the structural knowledge in feature space. Proxy-FDA performs Feature Distribution Alignment (using nearest neighbor graphs) between the pre-trained and fine-tuned feature spaces, and the alignment is further improved by informative proxies that are generated dynamically to increase data diversity. Experiments show that Proxy-FDA significantly reduces concept forgetting during fine-tuning, and we find a strong correlation between forgetting and a distributional distance metric (in comparison to L2 distance). We further demonstrate Proxy-FDA's benefits in various fine-tuning settings (end-to-end, few-shot and continual tuning) and across different tasks like image classification, captioning and VQA.
Discriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks
May 23, 2025We introduce a set of training-free ABX-style discrimination tasks to evaluate how multilingual language models represent language identity (form) and semantic content (meaning). Inspired from speech processing, these zero-shot tasks measure whether minimal differences in representation can be reliably detected. This offers a flexible and interpretable alternative to probing. Applied to XLM-R (Conneau et al, 2020) across pretraining checkpoints and layers, we find that language discrimination declines over training and becomes concentrated in lower layers, while meaning discrimination strengthens over time and stabilizes in deeper layers. We then explore probing tasks, showing some alignment between our metrics and linguistic learning performance. Our results position ABX tasks as a lightweight framework for analyzing the structure of multilingual representations.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
Feb 03, 2025Machine learning models are routinely trained on a mixture of different data domains. Different domain weights yield very different downstream performances. We propose the Soup-of-Experts, a novel architecture that can instantiate a model at test time for any domain weights with minimal computational cost and without re-training the model. Our architecture consists of a bank of expert parameters, which are linearly combined to instantiate one model. We learn the linear combination coefficients as a function of the input domain weights. To train this architecture, we sample random domain weights, instantiate the corresponding model, and backprop through one batch of data sampled with these domain weights. We demonstrate how our approach obtains small specialized models on several language modeling tasks quickly. Soup-of-Experts are particularly appealing when one needs to ship many different specialist models quickly under a model size constraint.
Training Bilingual LMs with Data Constraints in the Targeted Language
Nov 20, 2024



Large language models are trained on massive scrapes of the web, as required by current scaling laws. Most progress is made for English, given its abundance of high-quality pretraining data. For most other languages, however, such high quality pretraining data is unavailable. In this work, we study how to boost pretrained model performance in a data constrained target language by enlisting data from an auxiliary language for which high quality data is available. We study this by quantifying the performance gap between training with data in a data-rich auxiliary language compared with training in the target language, exploring the benefits of translation systems, studying the limitations of model scaling for data constrained languages, and proposing new methods for upsampling data from the auxiliary language. Our results show that stronger auxiliary datasets result in performance gains without modification to the model or training objective for close languages, and, in particular, that performance gains due to the development of more information-rich English pretraining datasets can extend to targeted language settings with limited data.
Aggregate-and-Adapt Natural Language Prompts for Downstream Generalization of CLIP
Oct 31, 2024



Large pretrained vision-language models like CLIP have shown promising generalization capability, but may struggle in specialized domains (e.g., satellite imagery) or fine-grained classification (e.g., car models) where the visual concepts are unseen or under-represented during pretraining. Prompt learning offers a parameter-efficient finetuning framework that can adapt CLIP to downstream tasks even when limited annotation data are available. In this paper, we improve prompt learning by distilling the textual knowledge from natural language prompts (either human- or LLM-generated) to provide rich priors for those under-represented concepts. We first obtain a prompt ``summary'' aligned to each input image via a learned prompt aggregator. Then we jointly train a prompt generator, optimized to produce a prompt embedding that stays close to the aggregated summary while minimizing task loss at the same time. We dub such prompt embedding as Aggregate-and-Adapted Prompt Embedding (AAPE). AAPE is shown to be able to generalize to different downstream data distributions and tasks, including vision-language understanding tasks (e.g., few-shot classification, VQA) and generation tasks (image captioning) where AAPE achieves competitive performance. We also show AAPE is particularly helpful to handle non-canonical and OOD examples. Furthermore, AAPE learning eliminates LLM-based inference cost as required by baselines, and scales better with data and LLM model size.
Learning Spatially-Aware Language and Audio Embedding
Sep 17, 2024



Humans can picture a sound scene given an imprecise natural language description. For example, it is easy to imagine an acoustic environment given a phrase like "the lion roar came from right behind me!". For a machine to have the same degree of comprehension, the machine must know what a lion is (semantic attribute), what the concept of "behind" is (spatial attribute) and how these pieces of linguistic information align with the semantic and spatial attributes of the sound (what a roar sounds like when its coming from behind). State-of-the-art audio foundation models which learn to map between audio scenes and natural textual descriptions, are trained on non-spatial audio and text pairs, and hence lack spatial awareness. In contrast, sound event localization and detection models are limited to recognizing sounds from a fixed number of classes, and they localize the source to absolute position (e.g., 0.2m) rather than a position described using natural language (e.g., "next to me"). To address these gaps, we present ELSA a spatially aware-audio and text embedding model trained using multimodal contrastive learning. ELSA supports non-spatial audio, spatial audio, and open vocabulary text captions describing both the spatial and semantic components of sound. To train ELSA: (a) we spatially augment the audio and captions of three open-source audio datasets totaling 4,738 hours of audio, and (b) we design an encoder to capture the semantics of non-spatial audio, and the semantics and spatial attributes of spatial audio using contrastive learning. ELSA is competitive with state-of-the-art for both semantic retrieval and 3D source localization. In particular, ELSA achieves +2.8% mean audio-to-text and text-to-audio R@1 above the baseline, and outperforms by -11.6{\deg} mean-absolute-error in 3D source localization over the baseline.
On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
Sep 05, 2024



Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an EXplicit Reward Model (EXRM) as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown that the implicit reward model of DPO (denoted as DPORM) can approximate an EXRM in the limit. DPORM's effectiveness directly implies the optimality of the learned policy, and also has practical implication for LLM alignment methods including iterative DPO. However, it is unclear how well DPORM empirically matches the performance of EXRM. This work studies the accuracy at distinguishing preferred and rejected answers for both DPORM and EXRM. Our findings indicate that even though DPORM fits the training dataset comparably, it generalizes less effectively than EXRM, especially when the validation datasets contain distribution shifts. Across five out-of-distribution settings, DPORM has a mean drop in accuracy of 3% and a maximum drop of 7%. These findings highlight that DPORM has limited generalization ability and substantiates the integration of an explicit reward model in iterative DPO approaches.