 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme Hallucinator: One-shot Voice Conversion via Set Expansion
Aug 11, 2023



Voice conversion (VC) aims at altering a person's voice to make it sound similar to the voice of another person while preserving linguistic content. Existing methods suffer from a dilemma between content intelligibility and speaker similarity; i.e., methods with higher intelligibility usually have a lower speaker similarity, while methods with higher speaker similarity usually require plenty of target speaker voice data to achieve high intelligibility. In this work, we propose a novel method \textit{Phoneme Hallucinator} that achieves the best of both worlds. Phoneme Hallucinator is a one-shot VC model; it adopts a novel model to hallucinate diversified and high-fidelity target speaker phonemes based just on a short target speaker voice (e.g. 3 seconds). The hallucinated phonemes are then exploited to perform neighbor-based voice conversion. Our model is a text-free, any-to-any VC model that requires no text annotations and supports conversion to any unseen speaker. Objective and subjective evaluations show that \textit{Phoneme Hallucinator} outperforms existing VC methods for both intelligibility and speaker similarity.
Distribution-based Sketching of Single-Cell Samples
Jun 30, 2022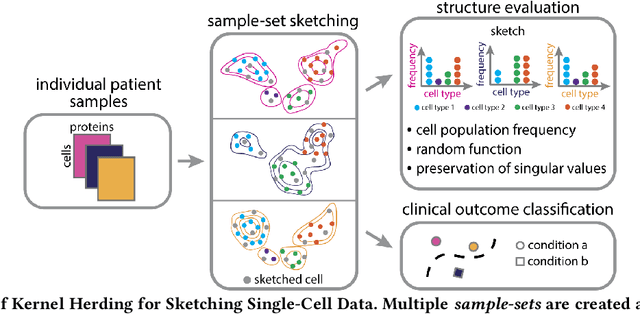
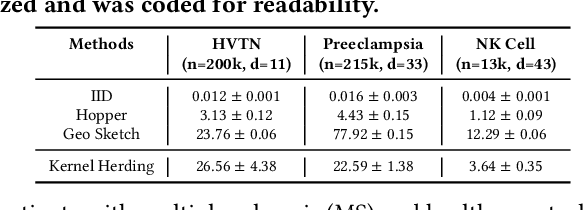
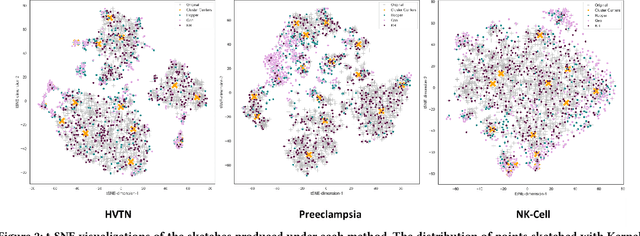
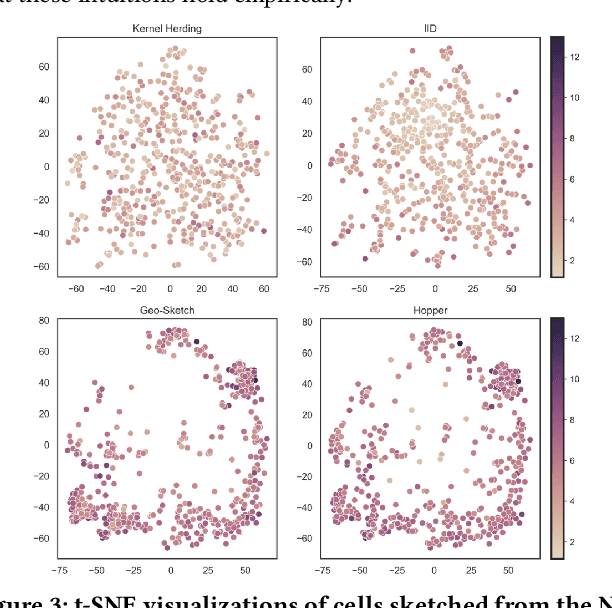
Modern high-throughput single-cell immune profiling technologies, such as flow and mass cytometry and single-cell RNA sequencing can readily measure the expression of a large number of protein or gene features across the millions of cells in a multi-patient cohort. While bioinformatics approaches can be used to link immune cell heterogeneity to external variables of interest, such as, clinical outcome or experimental label, they often struggle to accommodate such a large number of profiled cells. To ease this computational burden, a limited number of cells are typically \emph{sketched} or subsampled from each patient. However, existing sketching approaches fail to adequately subsample rare cells from rare cell-populations, or fail to preserve the true frequencies of particular immune cell-types. Here, we propose a novel sketching approach based on Kernel Herding that selects a limited subsample of all cells while preserving the underlying frequencies of immune cell-types. We tested our approach on three flow and mass cytometry datasets and on one single-cell RNA sequencing dataset and demonstrate that the sketched cells (1) more accurately represent the overall cellular landscape and (2) facilitate increased performance in downstream analysis tasks, such as classifying patients according to their clinical outcome. An implementation of sketching with Kernel Herding is publicly available at \url{https://github.com/vishalathreya/Set-Summarization}.
Interpretable Single-Cell Set Classification with Kernel Mean Embeddings
Feb 10, 2022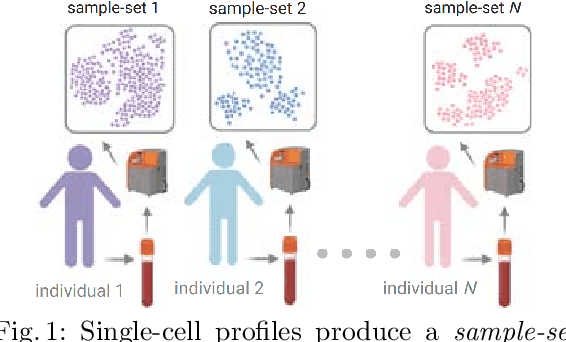
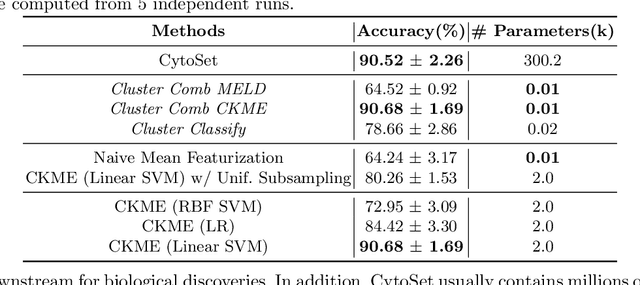
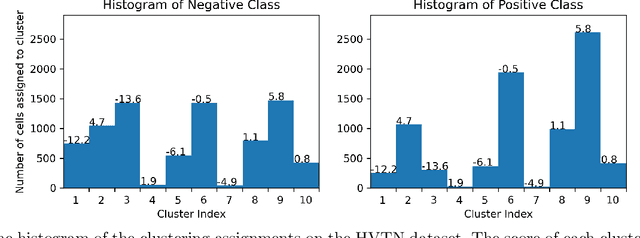
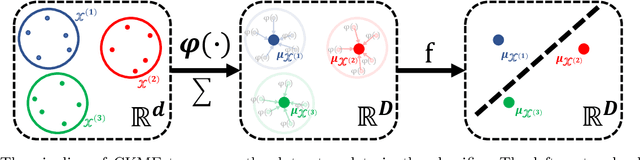
Modern single-cell flow and mass cytometry technologies measure the expression of several proteins of the individual cells within a blood or tissue sample. Each profiled biological sample is thus represented by a set of hundreds of thousands of multidimensional cell feature vectors, which incurs a high computational cost to predict each biological sample's associated phenotype with machine learning models. Such a large set cardinality also limits the interpretability of machine learning models due to the difficulty in tracking how each individual cell influences the ultimate prediction. Using Kernel Mean Embedding to encode the cellular landscape of each profiled biological sample, we can train a simple linear classifier and achieve state-of-the-art classification accuracy on 3 flow and mass cytometry datasets. Our model contains few parameters but still performs similarly to deep learning models with millions of parameters. In contrast with deep learning approaches, the linearity and sub-selection step of our model make it easy to interpret classification results. Clustering analysis further shows that our method admits rich biological interpretability for linking cellular heterogeneity to clinical phenotype.
Differentiable Wavetable Synthesis
Nov 23, 2021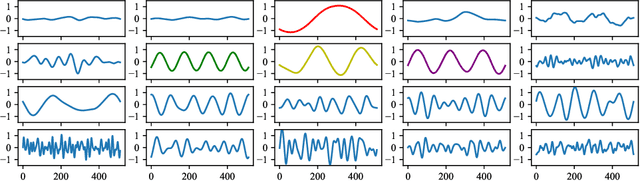

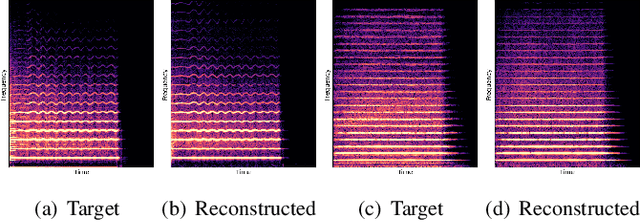
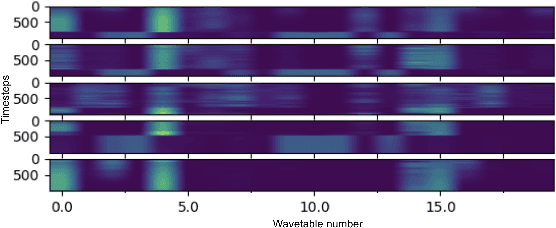
Differentiable Wavetable Synthesis (DWTS) is a technique for neural audio synthesis which learns a dictionary of one-period waveforms i.e. wavetables, through end-to-end training. We achieve high-fidelity audio synthesis with as little as 10 to 20 wavetables and demonstrate how a data-driven dictionary of waveforms opens up unprecedented one-shot learning paradigms on short audio clips. Notably, we show audio manipulations, such as high quality pitch-shifting, using only a few seconds of input audio. Lastly, we investigate performance gains from using learned wavetables for realtime and interactive audio synthesis.
Towards Robust Active Feature Acquisition
Jul 09, 2021

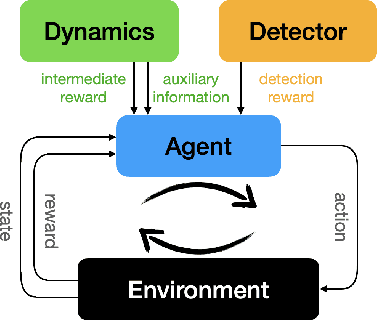
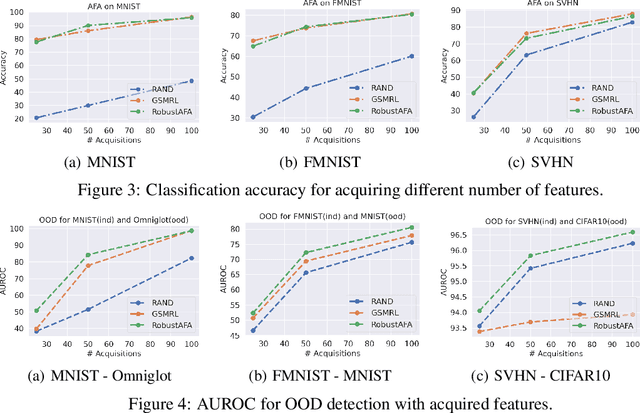
Truly intelligent systems are expected to make critical decisions with incomplete and uncertain data. Active feature acquisition (AFA), where features are sequentially acquired to improve the prediction, is a step towards this goal. However, current AFA models all deal with a small set of candidate features and have difficulty scaling to a large feature space. Moreover, they are ignorant about the valid domains where they can predict confidently, thus they can be vulnerable to out-of-distribution (OOD) inputs. In order to remedy these deficiencies and bring AFA models closer to practical use, we propose several techniques to advance the current AFA approaches. Our framework can easily handle a large number of features using a hierarchical acquisition policy and is more robust to OOD inputs with the help of an OOD detector for partially observed data. Extensive experiments demonstrate the efficacy of our framework over strong baselines.
NRTSI: Non-Recurrent Time Series Imputation for Irregularly-sampled Data
Feb 17, 2021
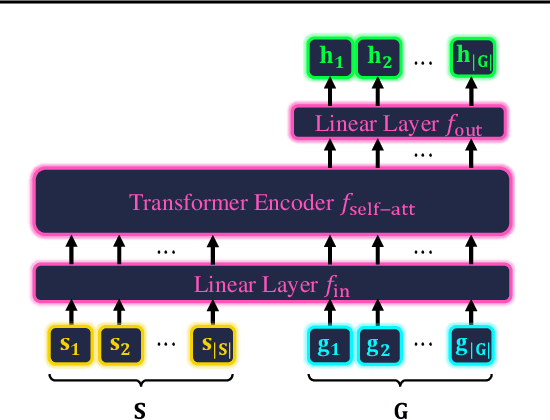

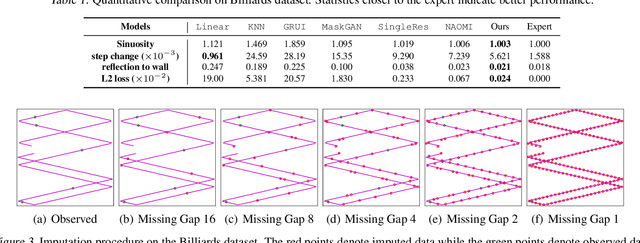
Time series imputation is a fundamental task for understanding time series with missing data. Existing imputation methods often rely on recurrent models such as RNNs and ordinary differential equations, both of which suffer from the error compounding problems of recurrent models. In this work, we view the imputation task from the perspective of permutation equivariant modeling of sets and propose a novel imputation model called NRTSI without any recurrent modules. Taking advantage of the permutation equivariant nature of NRTSI, we design a principled and efficient hierarchical imputation procedure. NRTSI can easily handle irregularly-sampled data, perform multiple-mode stochastic imputation, and handle the scenario where dimensions are partially observed. We show that NRTSI achieves state-of-the-art performance across a wide range of commonly used time series imputation benchmarks.
Exchangeable Neural ODE for Set Modeling
Aug 06, 2020

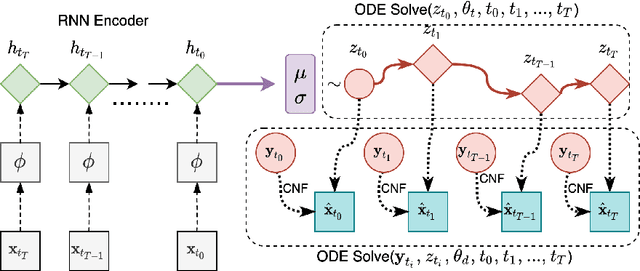
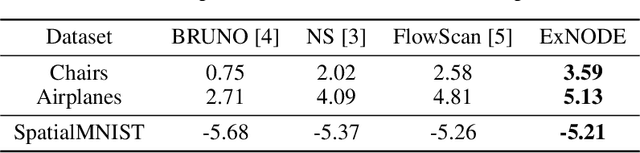
Reasoning over an instance composed of a set of vectors, like a point cloud, requires that one accounts for intra-set dependent features among elements. However, since such instances are unordered, the elements' features should remain unchanged when the input's order is permuted. This property, permutation equivariance, is a challenging constraint for most neural architectures. While recent work has proposed global pooling and attention-based solutions, these may be limited in the way that intradependencies are captured in practice. In this work we propose a more general formulation to achieve permutation equivariance through ordinary differential equations (ODE). Our proposed module, Exchangeable Neural ODE (ExNODE), can be seamlessly applied for both discriminative and generative tasks. We also extend set modeling in the temporal dimension and propose a VAE based model for temporal set modeling. Extensive experiments demonstrate the efficacy of our method over strong baselines.
Meta-Neighborhoods
Sep 18, 2019
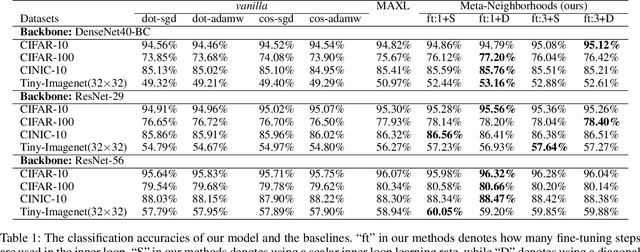
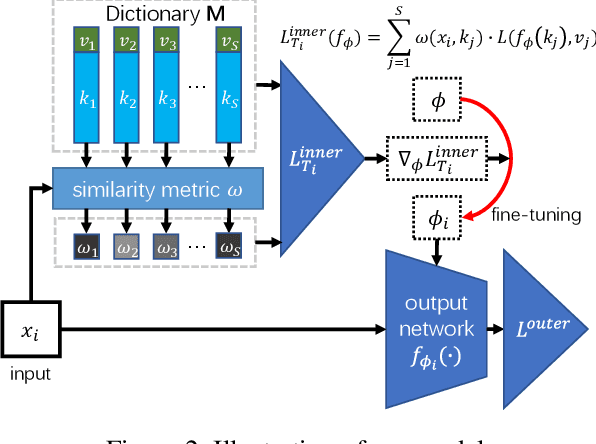

Traditional methods for training neural networks use training data just once, as it is discarded after training. Instead, in this work we also leverage the training data during testing to adjust the network and gain more expressivity. Our approach, named Meta-Neighborhoods, is developed under a multi-task learning framework and is a generalization of k-nearest neighbors methods. It can flexibly adapt network parameters w.r.t. different query data using their respective local neighborhood information. Local information is learned and stored in a dictionary of learnable neighbors rather than directly retrieved from the training set for greater flexibility and performance. The network parameters and the dictionary are optimized end-to-end via meta-learning. Extensive experiments demonstrate that Meta-Neighborhoods consistently improved classification and regression performance across various network architectures and datasets. We also observed superior improvements than other state-of-the-art meta-learning methods designed to improve supervised learning.
Unsupervised End-to-end Learning for Deformable Medical Image Registration
Jan 20, 2018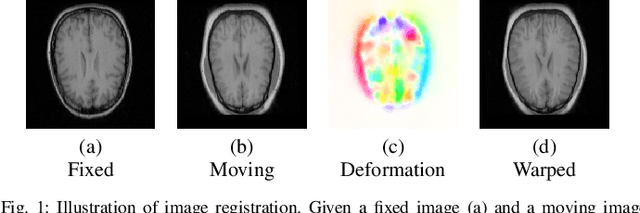
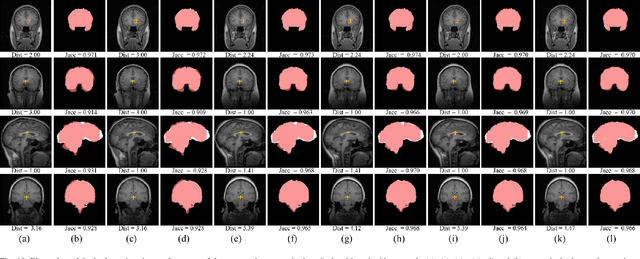
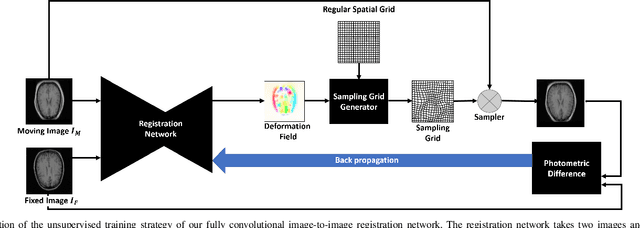
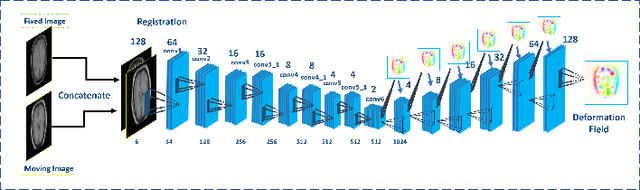
We propose a registration algorithm for 2D CT/MRI medical images with a new unsupervised end-to-end strategy using convolutional neural networks. The contributions of our algorithm are threefold: (1) We transplant traditional image registration algorithms to an end-to-end convolutional neural network framework, while maintaining the unsupervised nature of image registration problems. The image-to-image integrated framework can simultaneously learn both image features and transformation matrix for registration. (2) Training with additional data without any label can further improve the registration performance by approximately 10 %. (3) The registration speed is 100x faster than traditional methods. The proposed network is easy to implement and can be trained efficiently. Experiments demonstrate that our system achieves state-of-the-art results on 2D brain registration and achieves comparable results on 2D liver registration. It can be extended to register other organs beyond liver and brain such as kidney, lung, and heart.
End-to-End Subtitle Detection and Recognition for Videos in East Asian Languages via CNN Ensemble with Near-Human-Level Performance
Nov 18, 2016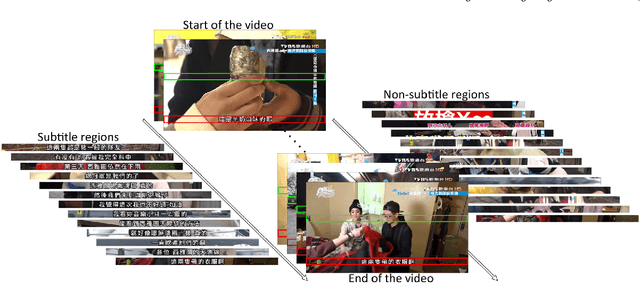
In this paper, we propose an innovative end-to-end subtitle detection and recognition system for videos in East Asian languages. Our end-to-end system consists of multiple stages. Subtitles are firstly detected by a novel image operator based on the sequence information of consecutive video frames. Then, an ensemble of Convolutional Neural Networks (CNNs) trained on synthetic data is adopted for detecting and recognizing East Asian characters. Finally, a dynamic programming approach leveraging language models is applied to constitute results of the entire body of text lines. The proposed system achieves average end-to-end accuracies of 98.2% and 98.3% on 40 videos in Simplified Chinese and 40 videos in Traditional Chinese respectively, which is a significant outperformance of other existing methods. The near-perfect accuracy of our system dramatically narrows the gap between human cognitive ability and state-of-the-art algorithms used for such a task.