 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARAH: Animatable Volume Rendering of Articulated Human SDFs
Oct 18, 2022
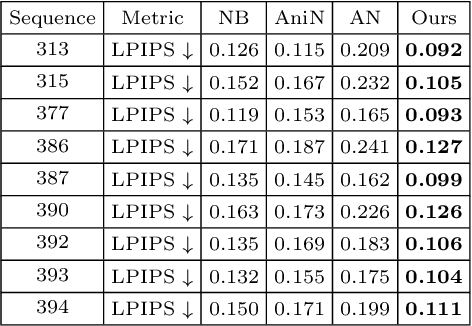
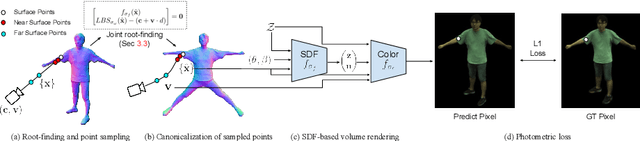
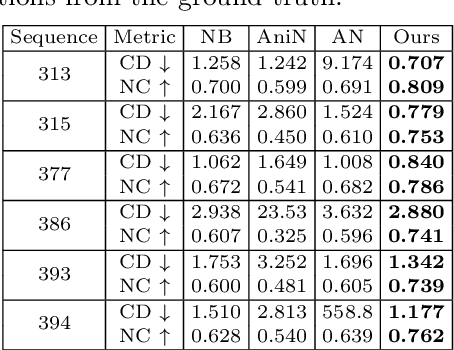
Combining human body models with differentiable rendering has recently enabled animatable avatars of clothed humans from sparse sets of multi-view RGB videos. While state-of-the-art approaches achieve realistic appearance with neural radiance fields (NeRF), the inferred geometry often lacks detail due to missing geometric constraints. Further, animating avatars in out-of-distribution poses is not yet possible because the mapping from observation space to canonical space does not generalize faithfully to unseen poses. In this work, we address these shortcomings and propose a model to create animatable clothed human avatars with detailed geometry that generalize well to out-of-distribution poses. To achieve detailed geometry, we combine an articulated implicit surface representation with volume rendering. For generalization, we propose a novel joint root-finding algorithm for simultaneous ray-surface intersection search and correspondence search. Our algorithm enables efficient point sampling and accurate point canonicalization while generalizing well to unseen poses. We demonstrate that our proposed pipeline can generate clothed avatars with high-quality pose-dependent geometry and appearance from a sparse set of multi-view RGB videos. Our method achieves state-of-the-art performance on geometry and appearance reconstruction while creating animatable avatars that generalize well to out-of-distribution poses beyond the small number of training poses.
Mask3D for 3D Semantic Instance Segmentation
Oct 06, 2022
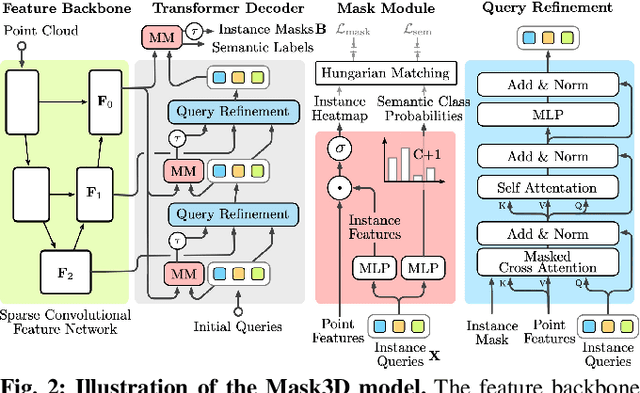
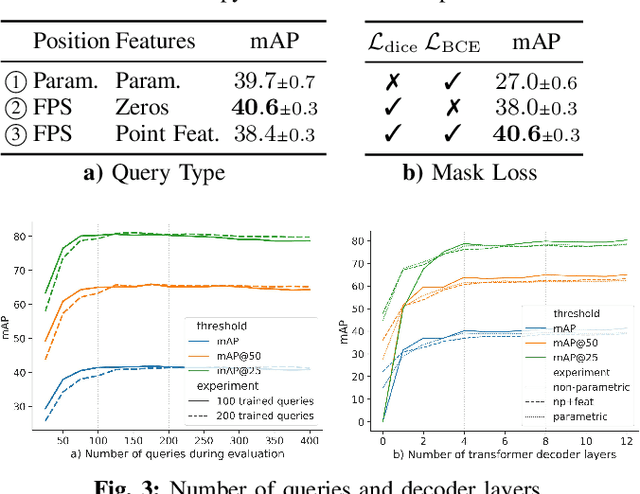
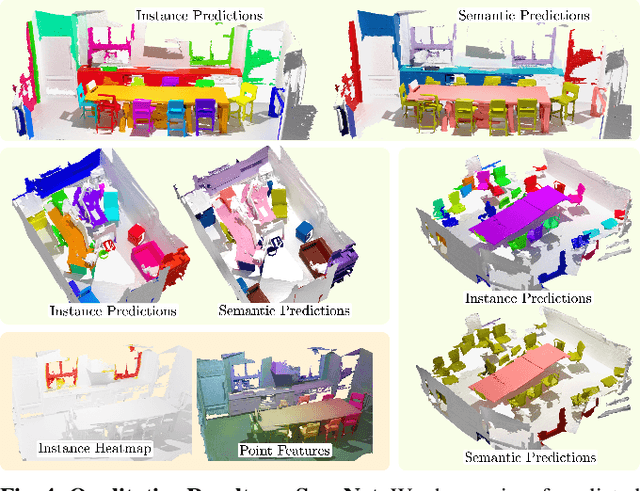
Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
Neural Point-based Shape Modeling of Humans in Challenging Clothing
Sep 14, 2022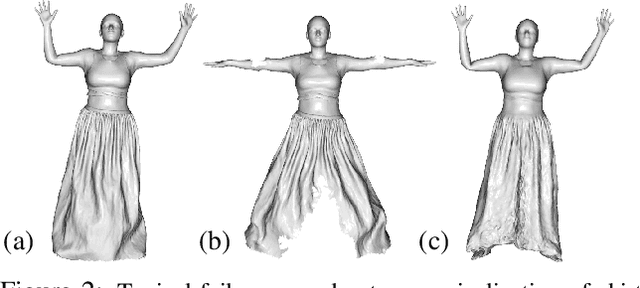
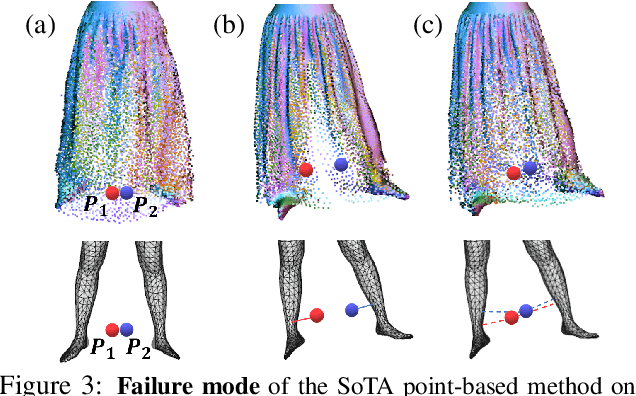
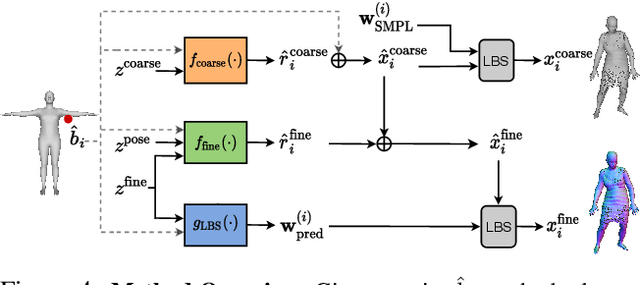
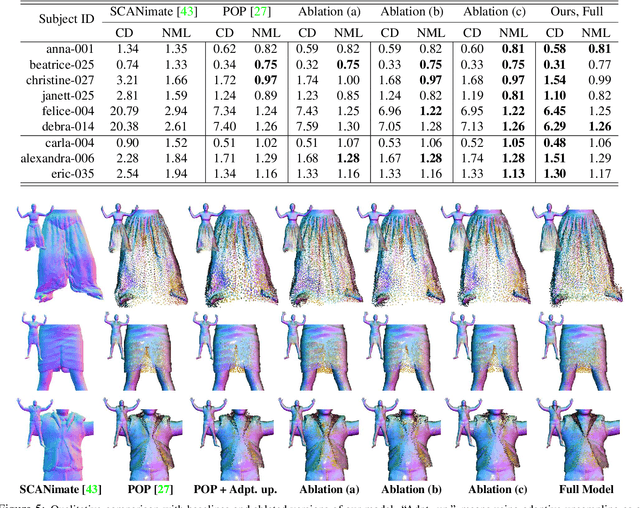
Parametric 3D body models like SMPL only represent minimally-clothed people and are hard to extend to clothing because they have a fixed mesh topology and resolution. To address these limitations, recent work uses implicit surfaces or point clouds to model clothed bodies. While not limited by topology, such methods still struggle to model clothing that deviates significantly from the body, such as skirts and dresses. This is because they rely on the body to canonicalize the clothed surface by reposing it to a reference shape. Unfortunately, this process is poorly defined when clothing is far from the body. Additionally, they use linear blend skinning to pose the body and the skinning weights are tied to the underlying body parts. In contrast, we model the clothing deformation in a local coordinate space without canonicalization. We also relax the skinning weights to let multiple body parts influence the surface. Specifically, we extend point-based methods with a coarse stage, that replaces canonicalization with a learned pose-independent "coarse shape" that can capture the rough surface geometry of clothing like skirts. We then refine this using a network that infers the linear blend skinning weights and pose dependent displacements from the coarse representation. The approach works well for garments that both conform to, and deviate from, the body. We demonstrate the usefulness of our approach by learning person-specific avatars from examples and then show how they can be animated in new poses and motions. We also show that the method can learn directly from raw scans with missing data, greatly simplifying the process of creating realistic avatars. Code is available for research purposes at {\small\url{https://qianlim.github.io/SkiRT}}.
Compositional Human-Scene Interaction Synthesis with Semantic Control
Jul 26, 2022


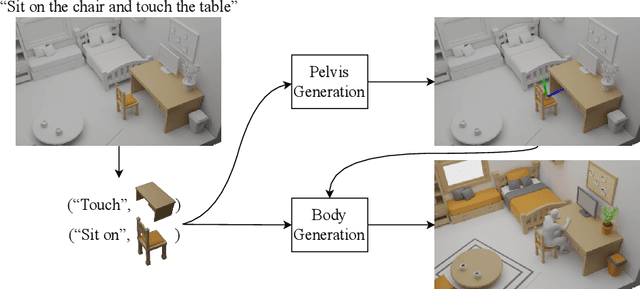
Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. Our goal is to synthesize humans interacting with a given 3D scene controlled by high-level semantic specifications as pairs of action categories and object instances, e.g., "sit on the chair". The key challenge of incorporating interaction semantics into the generation framework is to learn a joint representation that effectively captures heterogeneous information, including human body articulation, 3D object geometry, and the intent of the interaction. To address this challenge, we design a novel transformer-based generative model, in which the articulated 3D human body surface points and 3D objects are jointly encoded in a unified latent space, and the semantics of the interaction between the human and objects are embedded via positional encoding. Furthermore, inspired by the compositional nature of interactions that humans can simultaneously interact with multiple objects, we define interaction semantics as the composition of varying numbers of atomic action-object pairs. Our proposed generative model can naturally incorporate varying numbers of atomic interactions, which enables synthesizing compositional human-scene interactions without requiring composite interaction data. We extend the PROX dataset with interaction semantic labels and scene instance segmentation to evaluate our method and demonstrate that our method can generate realistic human-scene interactions with semantic control. Our perceptual study shows that our synthesized virtual humans can naturally interact with 3D scenes, considerably outperforming existing methods. We name our method COINS, for COmpositional INteraction Synthesis with Semantic Control. Code and data are available at https://github.com/zkf1997/COINS.
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Jun 14, 2022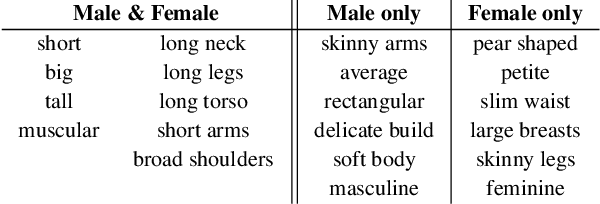

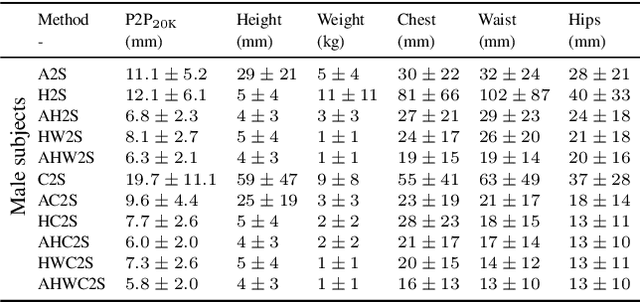
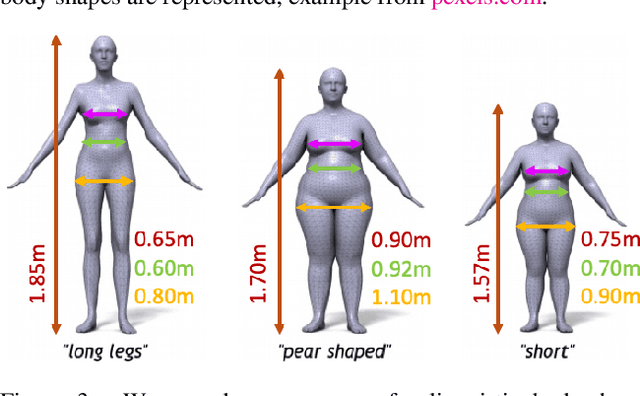
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
* First two authors contributed equally
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022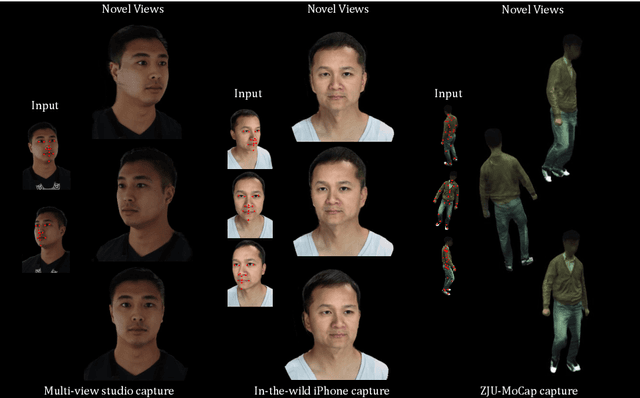

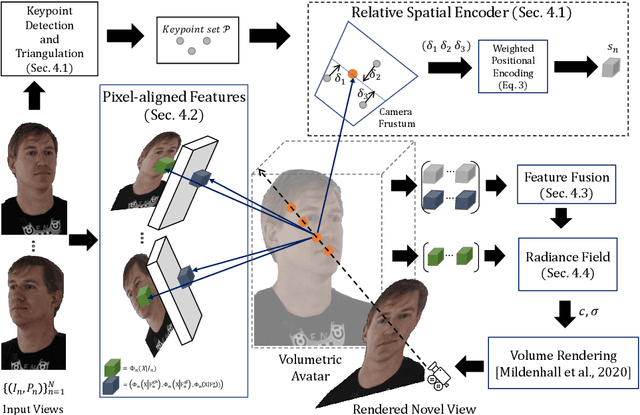
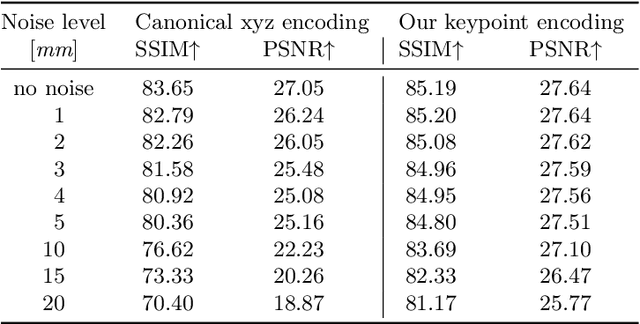
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
Context-Aware Sequence Alignment using 4D Skeletal Augmentation
Apr 26, 2022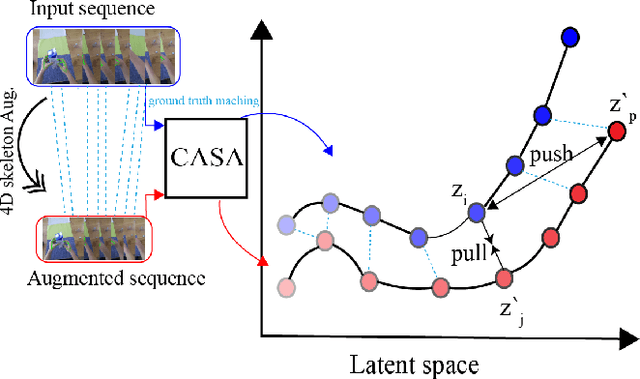
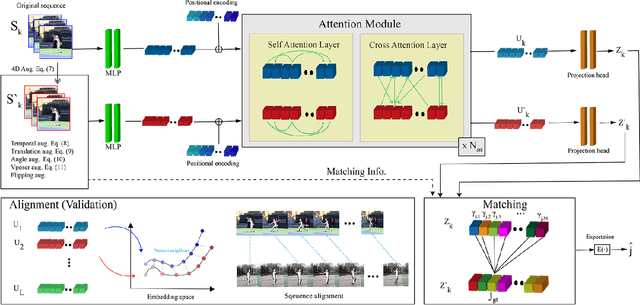
Temporal alignment of fine-grained human actions in videos is important for numerous applications in computer vision, robotics, and mixed reality. State-of-the-art methods directly learn image-based embedding space by leveraging powerful deep convolutional neural networks. While being straightforward, their results are far from satisfactory, the aligned videos exhibit severe temporal discontinuity without additional post-processing steps. The recent advancements in human body and hand pose estimation in the wild promise new ways of addressing the task of human action alignment in videos. In this work, based on off-the-shelf human pose estimators, we propose a novel context-aware self-supervised learning architecture to align sequences of actions. We name it CASA. Specifically, CASA employs self-attention and cross-attention mechanisms to incorporate the spatial and temporal context of human actions, which can solve the temporal discontinuity problem. Moreover, we introduce a self-supervised learning scheme that is empowered by novel 4D augmentation techniques for 3D skeleton representations. We systematically evaluate the key components of our method. Our experiments on three public datasets demonstrate CASA significantly improves phase progress and Kendall's Tau scores over the previous state-of-the-art methods.
Interactive Object Segmentation in 3D Point Clouds
Apr 14, 2022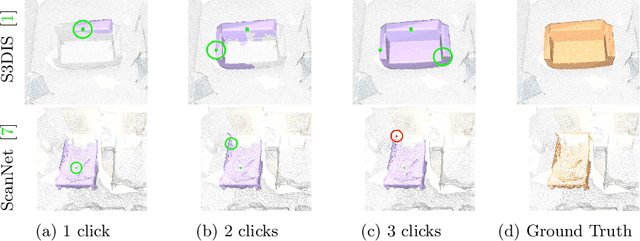
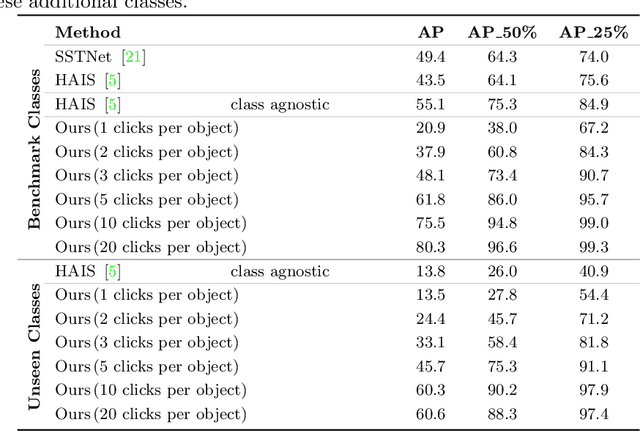
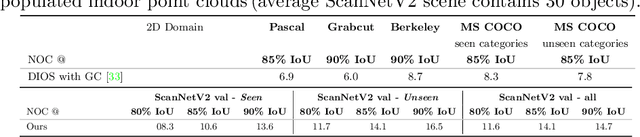
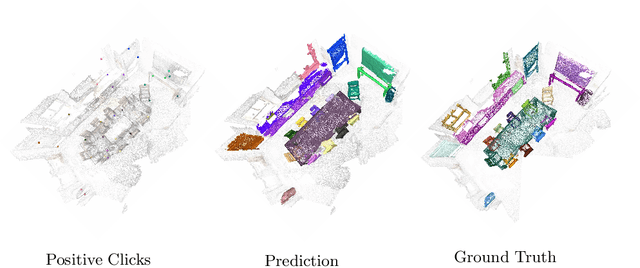
Deep learning depends on large amounts of labeled training data. Manual labeling is expensive and represents a bottleneck, especially for tasks such as segmentation, where labels must be assigned down to the level of individual points. That challenge is even more daunting for 3D data: 3D point clouds contain millions of points per scene, and their accurate annotation is markedly more time-consuming. The situation is further aggravated by the added complexity of user interfaces for 3D point clouds, which slows down annotation even more. For the case of 2D image segmentation, interactive techniques have become common, where user feedback in the form of a few clicks guides a segmentation algorithm -- nowadays usually a neural network -- to achieve an accurate labeling with minimal effort. Surprisingly, interactive segmentation of 3D scenes has not been explored much. Previous work has attempted to obtain accurate 3D segmentation masks using human feedback from the 2D domain, which is only possible if correctly aligned images are available together with the 3D point cloud, and it involves switching between the 2D and 3D domains. Here, we present an interactive 3D object segmentation method in which the user interacts directly with the 3D point cloud. Importantly, our model does not require training data from the target domain: when trained on ScanNet, it performs well on several other datasets with different data characteristics as well as different object classes. Moreover, our method is orthogonal to supervised (instance) segmentation methods and can be combined with them to refine automatic segmentations with minimal human effort.
COAP: Compositional Articulated Occupancy of People
Apr 13, 2022
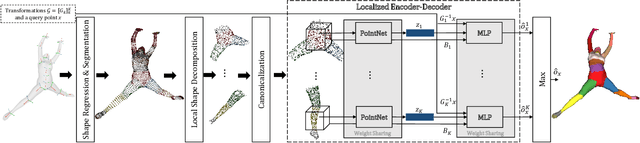
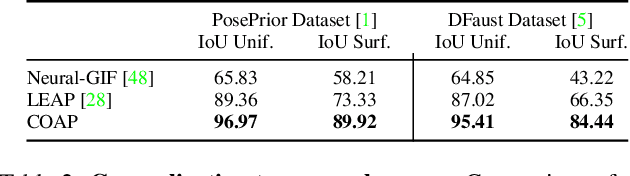
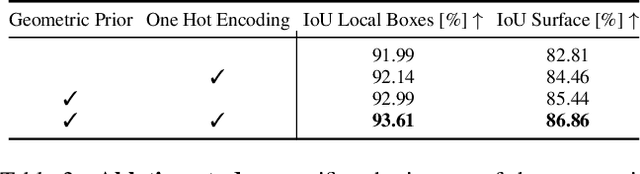
We present a novel neural implicit representation for articulated human bodies. Compared to explicit template meshes, neural implicit body representations provide an efficient mechanism for modeling interactions with the environment, which is essential for human motion reconstruction and synthesis in 3D scenes. However, existing neural implicit bodies suffer from either poor generalization on highly articulated poses or slow inference time. In this work, we observe that prior knowledge about the human body's shape and kinematic structure can be leveraged to improve generalization and efficiency. We decompose the full-body geometry into local body parts and employ a part-aware encoder-decoder architecture to learn neural articulated occupancy that models complex deformations locally. Our local shape encoder represents the body deformation of not only the corresponding body part but also the neighboring body parts. The decoder incorporates the geometric constraints of local body shape which significantly improves pose generalization. We demonstrate that our model is suitable for resolving self-intersections and collisions with 3D environments. Quantitative and qualitative experiments show that our method largely outperforms existing solutions in terms of both efficiency and accuracy. The code and models are available at https://neuralbodies.github.io/COAP/index.html
Human-Aware Object Placement for Visual Environment Reconstruction
Mar 28, 2022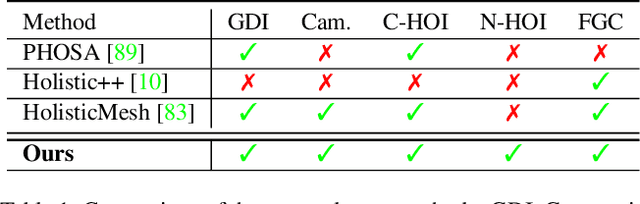

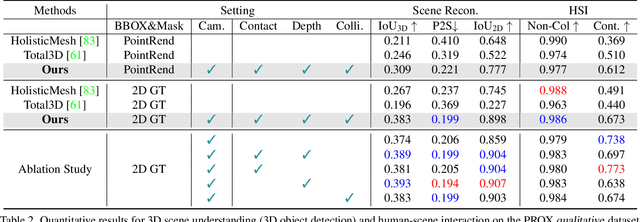
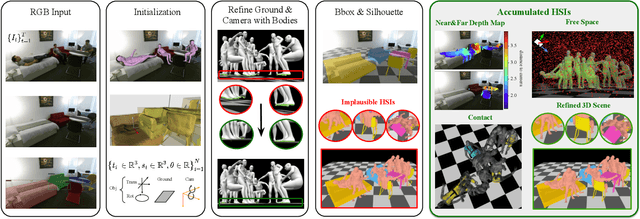
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them. In fact, we demonstrate that these human-scene interactions (HSIs) can be leveraged to improve the 3D reconstruction of a scene from a monocular RGB video. Our key idea is that, as a person moves through a scene and interacts with it, we accumulate HSIs across multiple input images, and optimize the 3D scene to reconstruct a consistent, physically plausible and functional 3D scene layout. Our optimization-based approach exploits three types of HSI constraints: (1) humans that move in a scene are occluded or occlude objects, thus, defining the depth ordering of the objects, (2) humans move through free space and do not interpenetrate objects, (3) when humans and objects are in contact, the contact surfaces occupy the same place in space. Using these constraints in an optimization formulation across all observations, we significantly improve the 3D scene layout reconstruction. Furthermore, we show that our scene reconstruction can be used to refine the initial 3D human pose and shape (HPS) estimation. We evaluate the 3D scene layout reconstruction and HPS estimation qualitatively and quantitatively using the PROX and PiGraphs datasets. The code and data are available for research purposes at https://mover.is.tue.mpg.de/.