 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Understanding Vision-Language Model for Embodied Agent
Apr 21, 2026Vision-language models (VLMs) have shown strong perception and reasoning abilities for instruction-following embodied agents. However, despite these abilities and their generalization performance, they still face limitations in environmental understanding, often failing on interactions or relying on environment metadata during execution. To address this challenge, we propose a novel framework named Environmental Understanding Embodied Agent (EUEA), which fine-tunes four core skills: 1) object perception for identifying relevant objects, 2) task planning for generating interaction subgoals, 3) action understanding for judging success likelihood, and 4) goal recognition for determining goal completion. By fine-tuning VLMs with EUEA skills, our framework enables more reliable task execution for instruction-following. We further introduce a recovery step that leverages these core skills and a group relative policy optimization (GRPO) stage that refines inconsistent skill predictions. The recovery step samples alternative actions to correct failure cases, and the GRPO stage refines inconsistent skill predictions. Across ALFRED tasks, our VLM significantly outperforms a behavior-cloning baseline, achieving an 8.86% improvement in average success rate. The recovery and GRPO stages provide an additional 3.03% gain, further enhancing overall performance. Finally, our skill-level analyses reveal key limitations in the environmental understanding of closed- and open-source VLMs and identify the capabilities necessary for effective agent-environment interaction.
Cross-Modal Emotion Transfer for Emotion Editing in Talking Face Video
Apr 09, 2026Talking face generation has gained significant attention as a core application of generative models. To enhance the expressiveness and realism of synthesized videos, emotion editing in talking face video plays a crucial role. However, existing approaches often limit expressive flexibility and struggle to generate extended emotions. Label-based methods represent emotions with discrete categories, which fail to capture a wide range of emotions. Audio-based methods can leverage emotionally rich speech signals - and even benefit from expressive text-to-speech (TTS) synthesis - but they fail to express the target emotions because emotions and linguistic contents are entangled in emotional speeches. Images-based methods, on the other hand, rely on target reference images to guide emotion transfer, yet they require high-quality frontal views and face challenges in acquiring reference data for extended emotions (e.g., sarcasm). To address these limitations, we propose Cross-Modal Emotion Transfer (C-MET), a novel approach that generates facial expressions based on speeches by modeling emotion semantic vectors between speech and visual feature spaces. C-MET leverages a large-scale pretrained audio encoder and a disentangled facial expression encoder to learn emotion semantic vectors that represent the difference between two different emotional embeddings across modalities. Extensive experiments on the MEAD and CREMA-D datasets demonstrate that our method improves emotion accuracy by 14% over state-of-the-art methods, while generating expressive talking face videos - even for unseen extended emotions. Code, checkpoint, and demo are available at https://chanhyeok-choi.github.io/C-MET/
DyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
Feb 26, 2026Generating realistic conversational gestures are essential for achieving natural, socially engaging interactions with digital humans. However, existing methods typically map a single audio stream to a single speaker's motion, without considering social context or modeling the mutual dynamics between two people engaging in conversation. We present DyaDiT, a multi-modal diffusion transformer that generates contextually appropriate human motion from dyadic audio signals. Trained on Seamless Interaction Dataset, DyaDiT takes dyadic audio with optional social-context tokens to produce context-appropriate motion. It fuses information from both speakers to capture interaction dynamics, uses a motion dictionary to encode motion priors, and can optionally utilize the conversational partner's gestures to produce more responsive motion. We evaluate DyaDiT on standard motion generation metrics and conduct quantitative user studies, demonstrating that it not only surpasses existing methods on objective metrics but is also strongly preferred by users, highlighting its robustness and socially favorable motion generation. Code and models will be released upon acceptance.
Crafting Query-Aware Selective Attention for Single Image Super-Resolution
Apr 09, 2025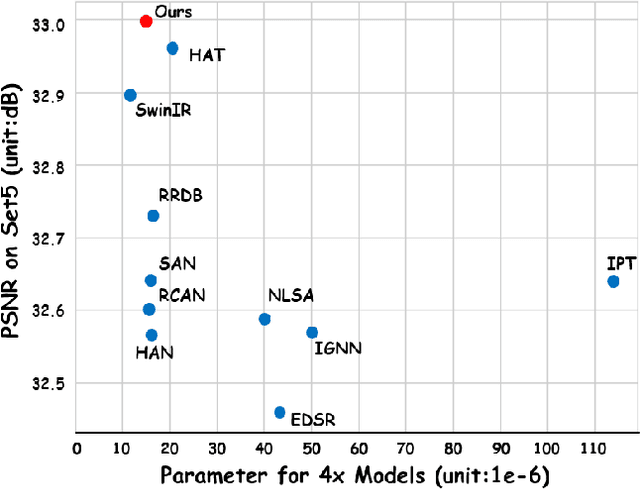
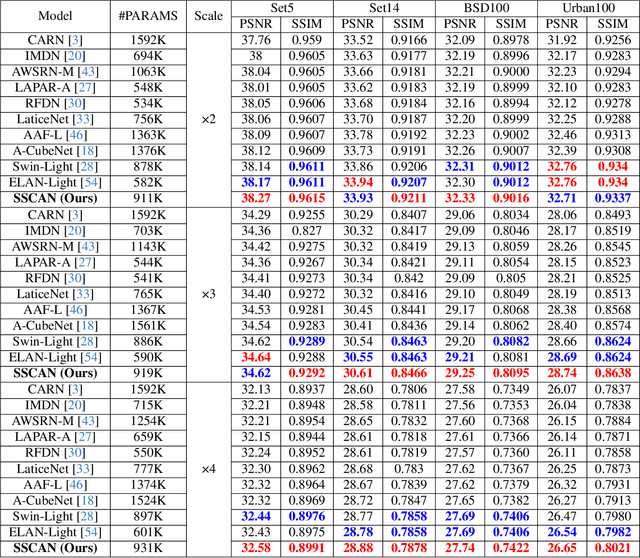

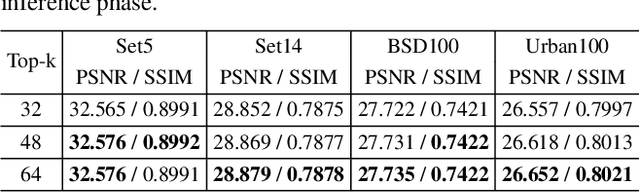
Single Image Super-Resolution (SISR) reconstructs high-resolution images from low-resolution inputs, enhancing image details. While Vision Transformer (ViT)-based models improve SISR by capturing long-range dependencies, they suffer from quadratic computational costs or employ selective attention mechanisms that do not explicitly focus on query-relevant regions. Despite these advancements, prior work has overlooked how selective attention mechanisms should be effectively designed for SISR. We propose SSCAN, which dynamically selects the most relevant key-value windows based on query similarity, ensuring focused feature extraction while maintaining efficiency. In contrast to prior approaches that apply attention globally or heuristically, our method introduces a query-aware window selection strategy that better aligns attention computation with important image regions. By incorporating fixed-sized windows, SSCAN reduces memory usage and enforces linear token-to-token complexity, making it scalable for large images. Our experiments demonstrate that SSCAN outperforms existing attention-based SISR methods, achieving up to 0.14 dB PSNR improvement on urban datasets, guaranteeing both computational efficiency and reconstruction quality in SISR.