 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
Crafting Query-Aware Selective Attention for Single Image Super-Resolution
Apr 09, 2025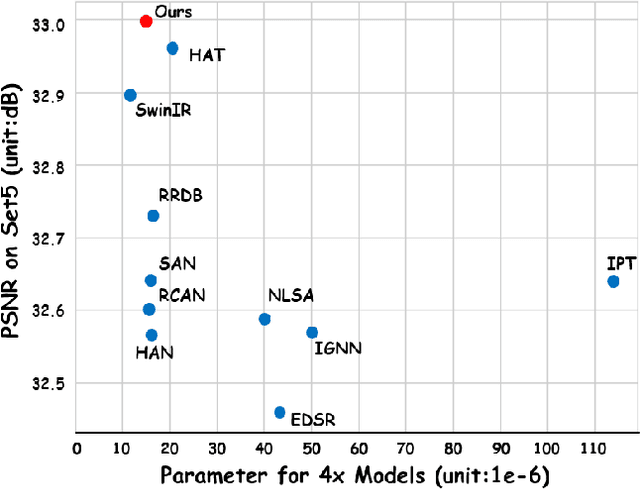
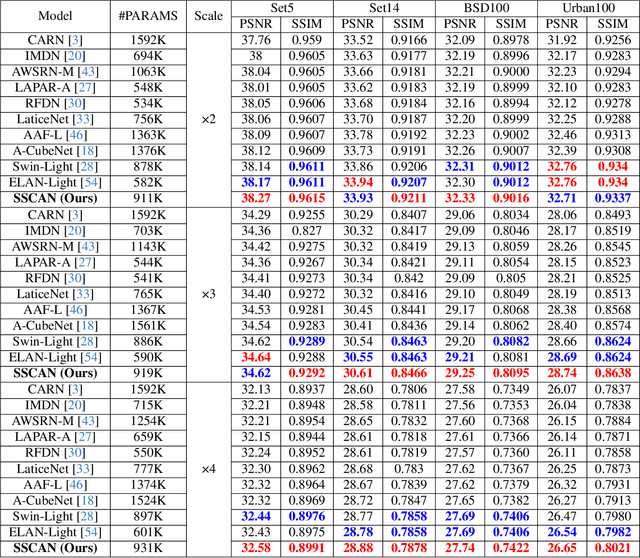

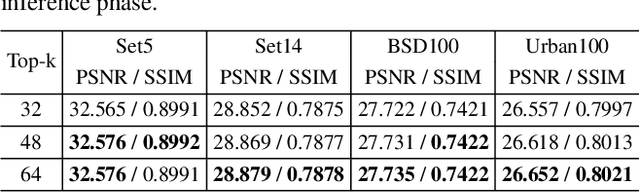
Single Image Super-Resolution (SISR) reconstructs high-resolution images from low-resolution inputs, enhancing image details. While Vision Transformer (ViT)-based models improve SISR by capturing long-range dependencies, they suffer from quadratic computational costs or employ selective attention mechanisms that do not explicitly focus on query-relevant regions. Despite these advancements, prior work has overlooked how selective attention mechanisms should be effectively designed for SISR. We propose SSCAN, which dynamically selects the most relevant key-value windows based on query similarity, ensuring focused feature extraction while maintaining efficiency. In contrast to prior approaches that apply attention globally or heuristically, our method introduces a query-aware window selection strategy that better aligns attention computation with important image regions. By incorporating fixed-sized windows, SSCAN reduces memory usage and enforces linear token-to-token complexity, making it scalable for large images. Our experiments demonstrate that SSCAN outperforms existing attention-based SISR methods, achieving up to 0.14 dB PSNR improvement on urban datasets, guaranteeing both computational efficiency and reconstruction quality in SISR.