 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Multimodal LLM-Based Multimedia Understanding in Large-Scale Recommendation Systems
May 10, 2026Conventional recommendation systems frequently fail to fully exploit the high-dimensional semantic signals inherent in multimedia content, thereby limiting the fidelity of user preference modeling. While Multimodal Large Language Models (MM-LLMs) offer robust mechanisms for interpreting such complex data, their integration into latency-constrained, industrial-scale architectures remains a significant challenge. To address this, we propose a generalized framework for MM-LLM-driven multimedia understanding. Our methodology employs a tripartite architecture encompassing content interpretation, representation extraction, and systematic pipeline integration, instantiated via a LLaMA2-based model that generates descriptive captions subsequently ingested as tokenized categorical features. Empirical evaluation demonstrates the efficacy of this approach, yielding a $0.35\%$ increase in offline AUC and a $0.02\%$ improvement in online metrics at scale, substantiating the practical viability of leveraging MM-LLMs to enhance large-scale recommendation performance.
Defending against Patch-Based and Texture-Based Adversarial Attacks with Spectral Decomposition
Apr 12, 2026Adversarial examples present significant challenges to the security of Deep Neural Network (DNN) applications. Specifically, there are patch-based and texture-based attacks that are usually used to craft physical-world adversarial examples, posing real threats to security-critical applications such as person detection in surveillance and autonomous systems, because those attacks are physically realizable. Existing defense mechanisms face challenges in the adaptive attack setting, i.e., the attacks are specifically designed against them. In this paper, we propose Adversarial Spectrum Defense (ASD), a defense mechanism that leverages spectral decomposition via Discrete Wavelet Transform (DWT) to analyze adversarial patterns across multiple frequency scales. The multi-resolution and localization capability of DWT enables ASD to capture both high-frequency (fine-grained) and low-frequency (spatially pervasive) perturbations. By integrating this spectral analysis with the off-the-shelf Adversarial Training (AT) model, ASD provides a comprehensive defense strategy against both patch-based and texture-based adversarial attacks. Extensive experiments demonstrate that ASD+AT achieved state-of-the-art (SOTA) performance against various attacks, outperforming the APs of previous defense methods by 21.73%, in the face of strong adaptive adversaries specifically designed against ASD. Code available at https://github.com/weiz0823/adv-spectral-defense .
Toward Multi-Satellite Cooperative Transmission: A Joint Framework for CSI Acquisition, Feedback, and Phase Synchronization
Mar 30, 2026The stringent link budget, caused by long propagation distances and payload constraints, poses a fundamental bottleneck for single-satellite transmission. Although LEO mega-constellations make multi-satellite cooperative transmission (MSCT), such as distributed precoding (DP), increasingly feasible, its cooperative gains critically rely on stringent time-frequency-phase synchronization (TFP-Sync), which is difficult to maintain under rapid channel variation and feedback latency. To address this issue, this paper proposes a joint CSI acquisition, feedback, and phase-level synchronization (JCAFPS) framework for MSCT. Specifically, to enable reliable, overhead-efficient CSI acquisition, we design a beam-domain adjustable phase-shift tracking reference signal (TRS) transmission scheme, along with criteria for the TRS and CSI-feedback periods. Then, exploiting deterministic orbital motion and dominant LoS propagation, we establish a polynomial model for the temporal evolution of delay and Doppler shift, and derive an OFDM-based multi-satellite signal model under non-ideal synchronization. The analysis reveals that, unlike the single-satellite case, the composite multi-satellite channel exhibits nonlinear time-frequency-varying phase behavior, necessitating symbol- and subcarrier-wise phase precompensation for coherent transmission. Based on these results, we develop a practical closed-loop realization integrating single-TRS-based channel parameter estimation, multi-TRS-based channel prediction, predictive CSI feedback, and user-specific TFP precompensation. Numerical results demonstrate that the proposed framework achieves accurate CSI acquisition and precise TFP-Sync, enabling DP-based dual-satellite cooperative transmission to approach the theoretical 6 dB power gain over single-satellite transmission, while remaining robust under extended prediction durations and enlarged TRS periods.
DSCSNet: A Dynamic Sparse Compression Sensing Network for Closely-Spaced Infrared Small Target Unmixing
Mar 22, 2026Due to the limitations of optical lens focal length and detector resolution, distant clustered infrared small targets often appear as mixed spots. The Close Small Object Unmixing (CSOU) task aims to recover the number, sub-pixel positions, and radiant intensities of individual targets from these spots, which is a highly ill-posed inverse problem. Existing methods struggle to balance the rigorous sparsity guarantees of model-driven approaches and the dynamic scene adaptability of data-driven methods. To address this dilemma, this paper proposes a Dynamic Sparse Compressed Sensing Network (DSCSNet), a deep-unfolded network that couples the Alternating Direction Method of Multipliers (ADMM) with learnable parameters. Specifically, we embed a strict $\ell_1$-norm sparsity constraint into the auxiliary variable update step of ADMM to replace the traditional $\ell_2$-norm smoothness-promoting terms, which effectively preserves the discrete energy peaks of small targets. We also integrate a self-attention-based dynamic thresholding mechanism into the reconstruction stage, which adaptively adjusts the sparsification intensity using the sparsity-enhanced information from the iterative process. These modules are jointly optimized end-to-end across the three iterative steps of ADMM. Retaining the physical logic of compressed sensing, DSCSNet achieves robust sparsity induction and scene adaptability, thus enhancing the unmixing accuracy and generalization in complex infrared scenarios. Extensive experiments on the synthetic infrared dataset CSIST-100K demonstrate that DSCSNet outperforms state-of-the-art methods in key metrics such as CSO-mAP and sub-pixel localization error.
Multi-Satellite Multi-Stream Beamspace Massive MIMO Transmission
Dec 26, 2025This paper studies multi-satellite multi-stream (MSMS) beamspace transmission, where multiple satellites cooperate to form a distributed multiple-input multiple-output (MIMO) system and jointly deliver multiple data streams to multi-antenna user terminals (UTs), and beamspace transmission combines earth-moving beamforming with beam-domain precoding. For the first time, we formulate the signal model for MSMS beamspace MIMO transmission. Under synchronization errors, multi-antenna UTs enable the distributed MIMO channel to exhibit higher rank, supporting multiple data streams. Beamspace MIMO retains conventional codebook based beamforming while providing the performance gains of precoding. Based on the signal model, we propose statistical channel state information (sCSI)-based optimization of satellite clustering, beam selection, and transmit precoding, using a sum-rate upper-bound approximation. With given satellite clustering and beam selection, we cast precoder design as an equivalent covariance decomposition-based weighted minimum mean square error (CDWMMSE) problem. To obtain tractable algorithms, we develop a closed-form covariance decomposition required by CDWMMSE and derive an iterative MSMS beam-domain precoder under sCSI. Following this, we further propose several heuristic closed-form precoders to avoid iterative cost. For satellite clustering, we enhance a competition-based algorithm by introducing a mechanism to regulate the number of satellites serving certain UT. Furthermore, we design a two-stage low-complexity beam selection algorithm focused on enhancing the effective channel power. Simulations under practical configurations validate the proposed methods across the number of data streams, receive antennas, serving satellites, and active beams, and show that beamspace transmission approaches conventional MIMO performance at lower complexity.
TAPOM: Task-Space Topology-Guided Motion Planning for Manipulating Elongated Object in Cluttered Environments
Nov 07, 2025Robotic manipulation in complex, constrained spaces is vital for widespread applications but challenging, particularly when navigating narrow passages with elongated objects. Existing planning methods often fail in these low-clearance scenarios due to the sampling difficulties or the local minima. This work proposes Topology-Aware Planning for Object Manipulation (TAPOM), which explicitly incorporates task-space topological analysis to enable efficient planning. TAPOM uses a high-level analysis to identify critical pathways and generate guiding keyframes, which are utilized in a low-level planner to find feasible configuration space trajectories. Experimental validation demonstrates significantly high success rates and improved efficiency over state-of-the-art methods on low-clearance manipulation tasks. This approach offers broad implications for enhancing manipulation capabilities of robots in complex real-world environments.
Dual-Domain Perspective on Degradation-Aware Fusion: A VLM-Guided Robust Infrared and Visible Image Fusion Framework
Sep 05, 2025



Most existing infrared-visible image fusion (IVIF) methods assume high-quality inputs, and therefore struggle to handle dual-source degraded scenarios, typically requiring manual selection and sequential application of multiple pre-enhancement steps. This decoupled pre-enhancement-to-fusion pipeline inevitably leads to error accumulation and performance degradation. To overcome these limitations, we propose Guided Dual-Domain Fusion (GD^2Fusion), a novel framework that synergistically integrates vision-language models (VLMs) for degradation perception with dual-domain (frequency/spatial) joint optimization. Concretely, the designed Guided Frequency Modality-Specific Extraction (GFMSE) module performs frequency-domain degradation perception and suppression and discriminatively extracts fusion-relevant sub-band features. Meanwhile, the Guided Spatial Modality-Aggregated Fusion (GSMAF) module carries out cross-modal degradation filtering and adaptive multi-source feature aggregation in the spatial domain to enhance modality complementarity and structural consistency. Extensive qualitative and quantitative experiments demonstrate that GD^2Fusion achieves superior fusion performance compared with existing algorithms and strategies in dual-source degraded scenarios. The code will be publicly released after acceptance of this paper.
FSATFusion: Frequency-Spatial Attention Transformer for Infrared and Visible Image Fusion
Jun 12, 2025



The infrared and visible images fusion (IVIF) is receiving increasing attention from both the research community and industry due to its excellent results in downstream applications. Existing deep learning approaches often utilize convolutional neural networks to extract image features. However, the inherently capacity of convolution operations to capture global context can lead to information loss, thereby restricting fusion performance. To address this limitation, we propose an end-to-end fusion network named the Frequency-Spatial Attention Transformer Fusion Network (FSATFusion). The FSATFusion contains a frequency-spatial attention Transformer (FSAT) module designed to effectively capture discriminate features from source images. This FSAT module includes a frequency-spatial attention mechanism (FSAM) capable of extracting significant features from feature maps. Additionally, we propose an improved Transformer module (ITM) to enhance the ability to extract global context information of vanilla Transformer. We conducted both qualitative and quantitative comparative experiments, demonstrating the superior fusion quality and efficiency of FSATFusion compared to other state-of-the-art methods. Furthermore, our network was tested on two additional tasks without any modifications, to verify the excellent generalization capability of FSATFusion. Finally, the object detection experiment demonstrated the superiority of FSATFusion in downstream visual tasks. Our code is available at https://github.com/Lmmh058/FSATFusion.
Make Both Ends Meet: A Synergistic Optimization Infrared Small Target Detection with Streamlined Computational Overhead
Apr 30, 2025
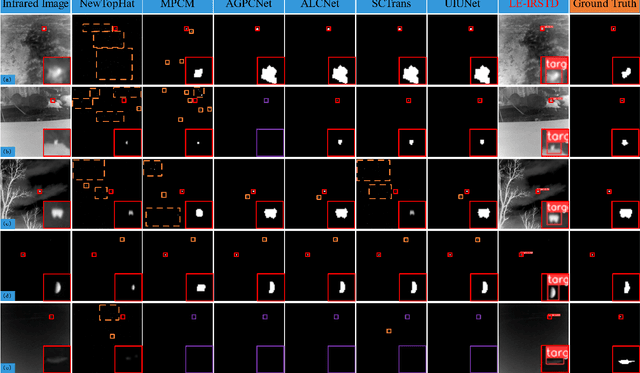
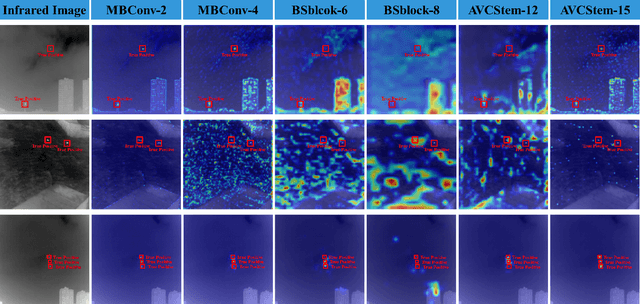
Infrared small target detection(IRSTD) is widely recognized as a challenging task due to the inherent limitations of infrared imaging, including low signal-to-noise ratios, lack of texture details, and complex background interference. While most existing methods model IRSTD as a semantic segmentation task, but they suffer from two critical drawbacks: (1)blurred target boundaries caused by long-distance imaging dispersion; and (2) excessive computational overhead due to indiscriminate feature stackin. To address these issues, we propose the Lightweight Efficiency Infrared Small Target Detection (LE-IRSTD), a lightweight and efficient framework based on YOLOv8n, with following key innovations. Firstly, we identify that the multiple bottleneck structures within the C2f component of the YOLOv8-n backbone contribute to an increased computational burden. Therefore, we implement the Mobile Inverted Bottleneck Convolution block (MBConvblock) and Bottleneck Structure block (BSblock) in the backbone, effectively balancing the trade-off between computational efficiency and the extraction of deep semantic information. Secondly, we introduce the Attention-based Variable Convolution Stem (AVCStem) structure, substituting the final convolution with Variable Kernel Convolution (VKConv), which allows for adaptive convolutional kernels that can transform into various shapes, facilitating the receptive field for the extraction of targets. Finally, we employ Global Shuffle Convolution (GSConv) to shuffle the channel dimension features obtained from different convolutional approaches, thereby enhancing the robustness and generalization capabilities of our method. Experimental results demonstrate that our LE-IRSTD method achieves compelling results in both accuracy and lightweight performance, outperforming several state-of-the-art deep learning methods.
Selective Variable Convolution Meets Dynamic Content Guided Attention for Infrared Small Target Detection
Apr 30, 2025
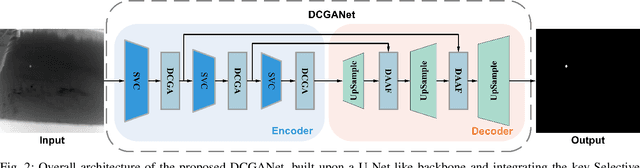
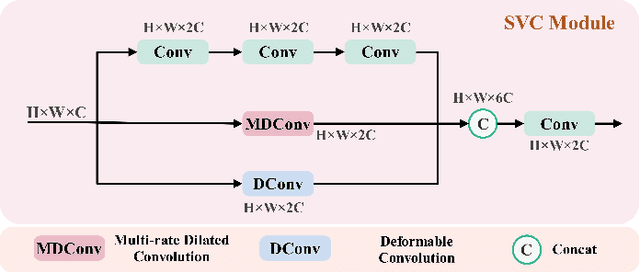
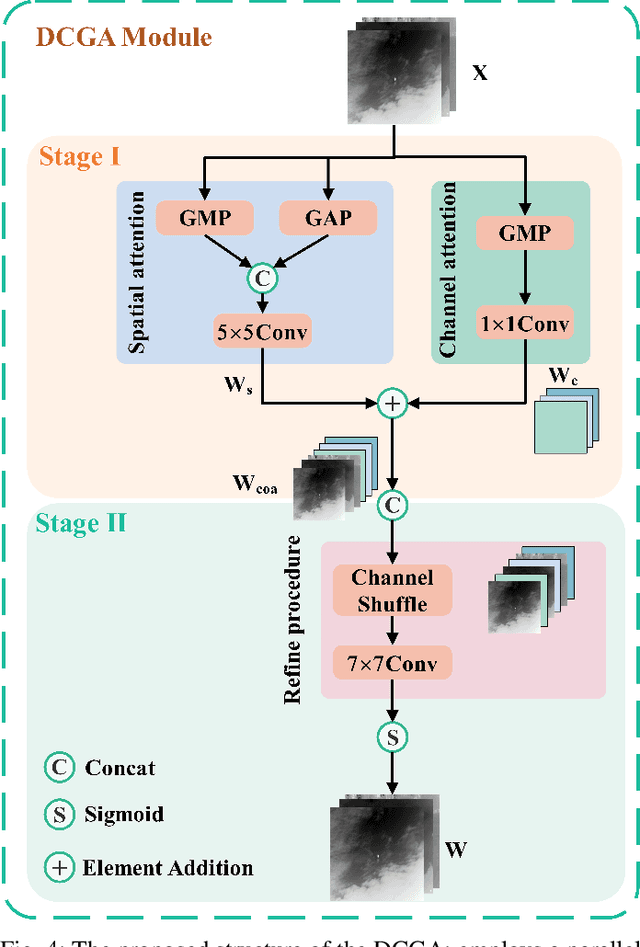
Infrared Small Target Detection (IRSTD) system aims to identify small targets in complex backgrounds. Due to the convolution operation in Convolutional Neural Networks (CNNs), applying traditional CNNs to IRSTD presents challenges, since the feature extraction of small targets is often insufficient, resulting in the loss of critical features. To address these issues, we propose a dynamic content guided attention multiscale feature aggregation network (DCGANet), which adheres to the attention principle of 'coarse-to-fine' and achieves high detection accuracy. First, we propose a selective variable convolution (SVC) module that integrates the benefits of standard convolution, irregular deformable convolution, and multi-rate dilated convolution. This module is designed to expand the receptive field and enhance non-local features, thereby effectively improving the discrimination of targets from backgrounds. Second, the core component of DCGANet is a two-stage content guided attention module. This module employs two-stage attention mechanism to initially direct the network's focus to salient regions within the feature maps and subsequently determine whether these regions correspond to targets or background interference. By retaining the most significant responses, this mechanism effectively suppresses false alarms. Additionally, we propose adaptive dynamic feature fusion (ADFF) module to substitute for static feature cascading. This dynamic feature fusion strategy enables DCGANet to adaptively integrate contextual features, thereby enhancing its ability to discriminate true targets from false alarms. DCGANet has achieved new benchmarks across multiple datasets.