 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive-Tuning: Understanding and Designing Incentives for Empirical Human-AI Decision-Making Studies
Jan 21, 2026AI has revolutionised decision-making across various fields. Yet human judgement remains paramount for high-stakes decision-making. This has fueled explorations of collaborative decision-making between humans and AI systems, aiming to leverage the strengths of both. To explore this dynamic, researchers conduct empirical studies, investigating how humans use AI assistance for decision-making and how this collaboration impacts results. A critical aspect of conducting these studies is the role of participants, often recruited through crowdsourcing platforms. The validity of these studies hinges on the behaviours of the participants, hence effective incentives that can potentially affect these behaviours are a key part of designing and executing these studies. In this work, we aim to address the critical role of incentive design for conducting empirical human-AI decision-making studies, focusing on understanding, designing, and documenting incentive schemes. Through a thematic review of existing research, we explored the current practices, challenges, and opportunities associated with incentive design for human-AI decision-making empirical studies. We identified recurring patterns, or themes, such as what comprises the components of an incentive scheme, how incentive schemes are manipulated by researchers, and the impact they can have on research outcomes. Leveraging the acquired understanding, we curated a set of guidelines to aid researchers in designing effective incentive schemes for their studies, called the Incentive-Tuning Framework, outlining how researchers can undertake, reflect on, and document the incentive design process. By advocating for a standardised yet flexible approach to incentive design and contributing valuable insights along with practical tools, we hope to pave the way for more reliable and generalizable knowledge in the field of human-AI decision-making.
Can Models Learn Skill Composition from Examples?
Sep 29, 2024



As large language models (LLMs) become increasingly advanced, their ability to exhibit compositional generalization -- the capacity to combine learned skills in novel ways not encountered during training -- has garnered significant attention. This type of generalization, particularly in scenarios beyond training data, is also of great interest in the study of AI safety and alignment. A recent study introduced the SKILL-MIX evaluation, where models are tasked with composing a short paragraph demonstrating the use of a specified $k$-tuple of language skills. While small models struggled with composing even with $k=3$, larger models like GPT-4 performed reasonably well with $k=5$ and $6$. In this paper, we employ a setup akin to SKILL-MIX to evaluate the capacity of smaller models to learn compositional generalization from examples. Utilizing a diverse set of language skills -- including rhetorical, literary, reasoning, theory of mind, and common sense -- GPT-4 was used to generate text samples that exhibit random subsets of $k$ skills. Subsequent fine-tuning of 7B and 13B parameter models on these combined skill texts, for increasing values of $k$, revealed the following findings: (1) Training on combinations of $k=2$ and $3$ skills results in noticeable improvements in the ability to compose texts with $k=4$ and $5$ skills, despite models never having seen such examples during training. (2) When skill categories are split into training and held-out groups, models significantly improve at composing texts with held-out skills during testing despite having only seen training skills during fine-tuning, illustrating the efficacy of the training approach even with previously unseen skills. This study also suggests that incorporating skill-rich (potentially synthetic) text into training can substantially enhance the compositional capabilities of models.
Instruct-SkillMix: A Powerful Pipeline for LLM Instruction Tuning
Aug 27, 2024



We introduce Instruct-SkillMix, an automated approach for creating diverse, high quality SFT data. The Instruct-SkillMix pipeline involves two stages, each leveraging an existing powerful LLM: (1) Skill extraction: uses the LLM to extract core "skills" for instruction-following, either from existing datasets, or by directly prompting the model; (2) Data generation: uses the powerful LLM to generate (instruction, response) data that exhibit a randomly chosen pair of these skills. Here, the use of random skill combinations promotes diversity and difficulty. Vanilla SFT (i.e., no PPO, DPO, or RL methods) on data generated from Instruct-SkillMix leads to strong gains on instruction following benchmarks such as AlpacaEval 2.0, MT-Bench, and WildBench. With just $4$K examples, LLaMA-3-8B-Base achieves 42.76% length-controlled win rate on AlpacaEval 2.0. To our knowledge, this achieves state-of-the-art performance among all models that have only undergone SFT (no RL methods) and competes with proprietary models such as Claude 3 Opus and LLaMA-3.1-405B-Instruct. Ablation studies also suggest plausible reasons for why creating open instruction-tuning datasets via naive crowd-sourcing has proved difficult. Introducing low quality answers ("shirkers") in $20\%$ of Instruct-SkillMix examples causes performance to plummet, sometimes catastrophically. The Instruct-SkillMix pipeline is flexible and is adaptable to other settings.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
Oct 26, 2023



With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should LLM evaluations change? Arguably, a key ability of an AI agent is to flexibly combine, as needed, the basic skills it has learned. The capability to combine skills plays an important role in (human) pedagogy and also in a paper on emergence phenomena (Arora & Goyal, 2023). This work introduces Skill-Mix, a new evaluation to measure ability to combine skills. Using a list of $N$ skills the evaluator repeatedly picks random subsets of $k$ skills and asks the LLM to produce text combining that subset of skills. Since the number of subsets grows like $N^k$, for even modest $k$ this evaluation will, with high probability, require the LLM to produce text significantly different from any text in the training set. The paper develops a methodology for (a) designing and administering such an evaluation, and (b) automatic grading (plus spot-checking by humans) of the results using GPT-4 as well as the open LLaMA-2 70B model. Administering a version of to popular chatbots gave results that, while generally in line with prior expectations, contained surprises. Sizeable differences exist among model capabilities that are not captured by their ranking on popular LLM leaderboards ("cramming for the leaderboard"). Furthermore, simple probability calculations indicate that GPT-4's reasonable performance on $k=5$ is suggestive of going beyond "stochastic parrot" behavior (Bender et al., 2021), i.e., it combines skills in ways that it had not seen during training. We sketch how the methodology can lead to a Skill-Mix based eco-system of open evaluations for AI capabilities of future models.
Disentangling the Mechanisms Behind Implicit Regularization in SGD
Nov 29, 2022



A number of competing hypotheses have been proposed to explain why small-batch Stochastic Gradient Descent (SGD)leads to improved generalization over the full-batch regime, with recent work crediting the implicit regularization of various quantities throughout training. However, to date, empirical evidence assessing the explanatory power of these hypotheses is lacking. In this paper, we conduct an extensive empirical evaluation, focusing on the ability of various theorized mechanisms to close the small-to-large batch generalization gap. Additionally, we characterize how the quantities that SGD has been claimed to (implicitly) regularize change over the course of training. By using micro-batches, i.e. disjoint smaller subsets of each mini-batch, we empirically show that explicitly penalizing the gradient norm or the Fisher Information Matrix trace, averaged over micro-batches, in the large-batch regime recovers small-batch SGD generalization, whereas Jacobian-based regularizations fail to do so. This generalization performance is shown to often be correlated with how well the regularized model's gradient norms resemble those of small-batch SGD. We additionally show that this behavior breaks down as the micro-batch size approaches the batch size. Finally, we note that in this line of inquiry, positive experimental findings on CIFAR10 are often reversed on other datasets like CIFAR100, highlighting the need to test hypotheses on a wider collection of datasets.
On the Maximum Hessian Eigenvalue and Generalization
Jun 21, 2022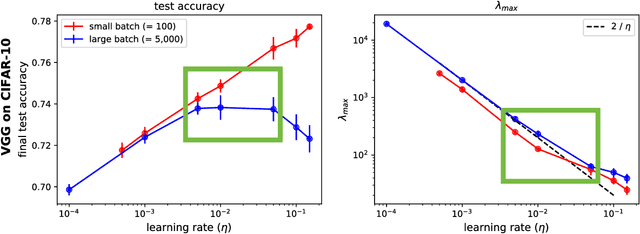
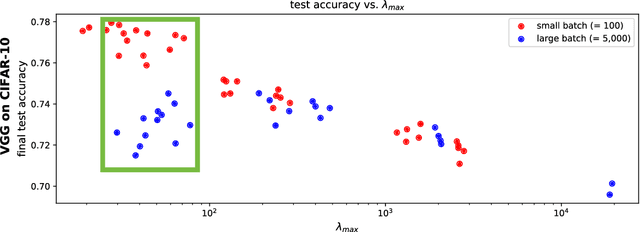
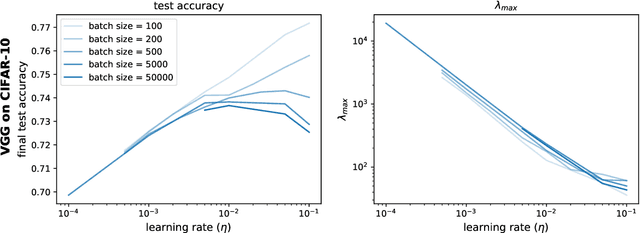
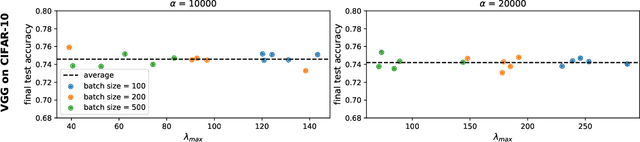
The mechanisms by which certain training interventions, such as increasing learning rates and applying batch normalization, improve the generalization of deep networks remains a mystery. Prior works have speculated that "flatter" solutions generalize better than "sharper" solutions to unseen data, motivating several metrics for measuring flatness (particularly $\lambda_{max}$, the largest eigenvalue of the Hessian of the loss); and algorithms, such as Sharpness-Aware Minimization (SAM) [1], that directly optimize for flatness. Other works question the link between $\lambda_{max}$ and generalization. In this paper, we present findings that call $\lambda_{max}$'s influence on generalization further into question. We show that: (1) while larger learning rates reduce $\lambda_{max}$ for all batch sizes, generalization benefits sometimes vanish at larger batch sizes; (2) by scaling batch size and learning rate simultaneously, we can change $\lambda_{max}$ without affecting generalization; (3) while SAM produces smaller $\lambda_{max}$ for all batch sizes, generalization benefits (also) vanish with larger batch sizes; (4) for dropout, excessively high dropout probabilities can degrade generalization, even as they promote smaller $\lambda_{max}$; and (5) while batch-normalization does not consistently produce smaller $\lambda_{max}$, it nevertheless confers generalization benefits. While our experiments affirm the generalization benefits of large learning rates and SAM for minibatch SGD, the GD-SGD discrepancy demonstrates limits to $\lambda_{max}$'s ability to explain generalization in neural networks.
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
Feb 26, 2021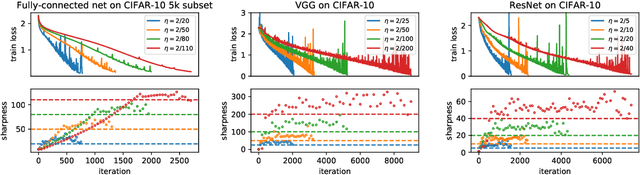
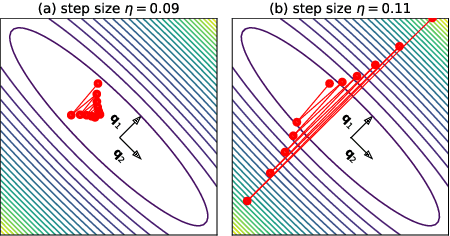

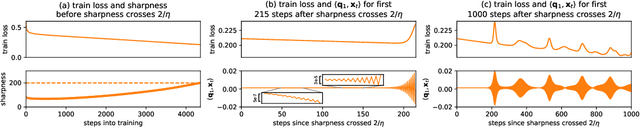
We empirically demonstrate that full-batch gradient descent on neural network training objectives typically operates in a regime we call the Edge of Stability. In this regime, the maximum eigenvalue of the training loss Hessian hovers just above the numerical value $2 / \text{(step size)}$, and the training loss behaves non-monotonically over short timescales, yet consistently decreases over long timescales. Since this behavior is inconsistent with several widespread presumptions in the field of optimization, our findings raise questions as to whether these presumptions are relevant to neural network training. We hope that our findings will inspire future efforts aimed at rigorously understanding optimization at the Edge of Stability. Code is available at https://github.com/locuslab/edge-of-stability.
Are Perceptually-Aligned Gradients a General Property of Robust Classifiers?
Oct 23, 2019



For a standard convolutional neural network, optimizing over the input pixels to maximize the score of some target class will generally produce a grainy-looking version of the original image. However, Santurkar et al. (2019) demonstrated that for adversarially-trained neural networks, this optimization produces images that uncannily resemble the target class. In this paper, we show that these "perceptually-aligned gradients" also occur under randomized smoothing, an alternative means of constructing adversarially-robust classifiers. Our finding supports the hypothesis that perceptually-aligned gradients may be a general property of robust classifiers. We hope that our results will inspire research aimed at explaining this link between perceptually-aligned gradients and adversarial robustness.