 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoology: Measuring and Improving Recall in Efficient Language Models
Dec 08, 2023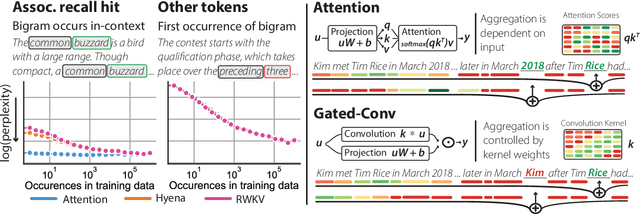



Attention-free language models that combine gating and convolutions are growing in popularity due to their efficiency and increasingly competitive performance. To better understand these architectures, we pretrain a suite of 17 attention and "gated-convolution" language models, finding that SoTA gated-convolution architectures still underperform attention by up to 2.1 perplexity points on the Pile. In fine-grained analysis, we find 82% of the gap is explained by each model's ability to recall information that is previously mentioned in-context, e.g. "Hakuna Matata means no worries Hakuna Matata it means no" $\rightarrow$ "??". On this task, termed "associative recall", we find that attention outperforms gated-convolutions by a large margin: a 70M parameter attention model outperforms a 1.4 billion parameter gated-convolution model on associative recall. This is surprising because prior work shows gated convolutions can perfectly solve synthetic tests for AR capability. To close the gap between synthetics and real language, we develop a new formalization of the task called multi-query associative recall (MQAR) that better reflects actual language. We perform an empirical and theoretical study of MQAR that elucidates differences in the parameter-efficiency of attention and gated-convolution recall. Informed by our analysis, we evaluate simple convolution-attention hybrids and show that hybrids with input-dependent sparse attention patterns can close 97.4% of the gap to attention, while maintaining sub-quadratic scaling. Our code is accessible at: https://github.com/HazyResearch/zoology.
RELIC: Investigating Large Language Model Responses using Self-Consistency
Nov 28, 2023



Large Language Models (LLMs) are notorious for blending fact with fiction and generating non-factual content, known as hallucinations. To tackle this challenge, we propose an interactive system that helps users obtain insights into the reliability of the generated text. Our approach is based on the idea that the self-consistency of multiple samples generated by the same LLM relates to its confidence in individual claims in the generated texts. Using this idea, we design RELIC, an interactive system that enables users to investigate and verify semantic-level variations in multiple long-form responses. This allows users to recognize potentially inaccurate information in the generated text and make necessary corrections. From a user study with ten participants, we demonstrate that our approach helps users better verify the reliability of the generated text. We further summarize the design implications and lessons learned from this research for inspiring future studies on reliable human-LLM interactions.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023



Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
Jun 20, 2023



Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance - where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives - including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
Apr 20, 2023



A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
Ask Me Anything: A simple strategy for prompting language models
Oct 06, 2022
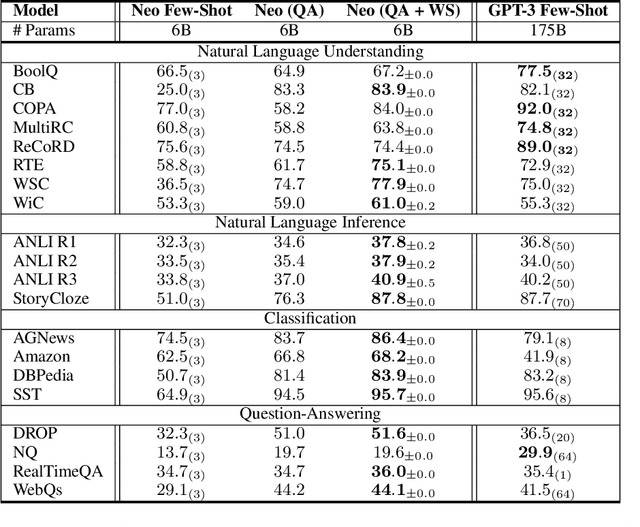

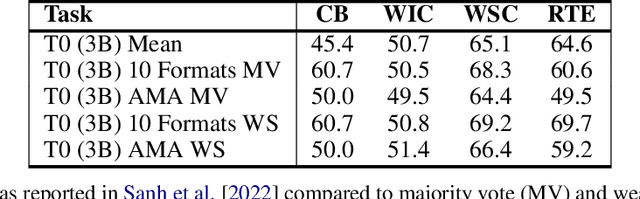
Large language models (LLMs) transfer well to new tasks out-of-the-box simply given a natural language prompt that demonstrates how to perform the task and no additional training. Prompting is a brittle process wherein small modifications to the prompt can cause large variations in the model predictions, and therefore significant effort is dedicated towards designing a painstakingly "perfect prompt" for a task. To mitigate the high degree of effort involved in prompt-design, we instead ask whether producing multiple effective, yet imperfect, prompts and aggregating them can lead to a high quality prompting strategy. Our observations motivate our proposed prompting method, ASK ME ANYTHING (AMA). We first develop an understanding of the effective prompt formats, finding that question-answering (QA) prompts, which encourage open-ended generation ("Who went to the park?") tend to outperform those that restrict the model outputs ("John went to the park. Output True or False."). Our approach recursively uses the LLM itself to transform task inputs to the effective QA format. We apply the collected prompts to obtain several noisy votes for the input's true label. We find that the prompts can have very different accuracies and complex dependencies and thus propose to use weak supervision, a procedure for combining the noisy predictions, to produce the final predictions for the inputs. We evaluate AMA across open-source model families (e.g., EleutherAI, BLOOM, OPT, and T0) and model sizes (125M-175B parameters), demonstrating an average performance lift of 10.2% over the few-shot baseline. This simple strategy enables the open-source GPT-J-6B model to match and exceed the performance of few-shot GPT3-175B on 15 of 20 popular benchmarks. Averaged across these tasks, the GPT-Neo-6B model outperforms few-shot GPT3-175B. We release our code here: https://github.com/HazyResearch/ama_prompting
Can Foundation Models Help Us Achieve Perfect Secrecy?
May 27, 2022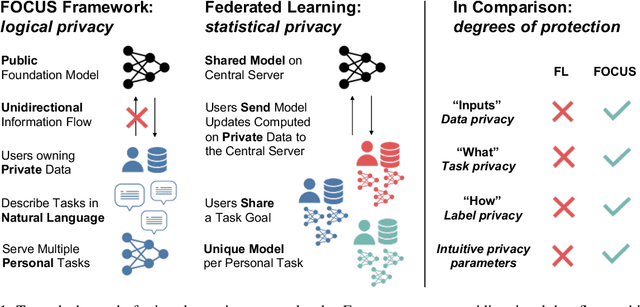
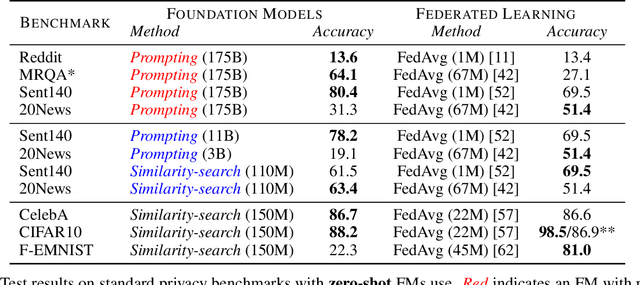
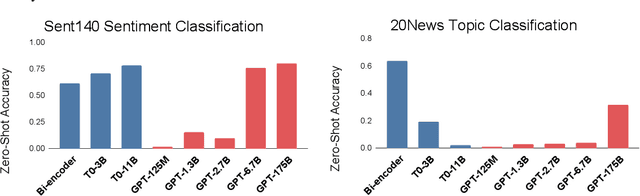

A key promise of machine learning is the ability to assist users with personal tasks. Because the personal context required to make accurate predictions is often sensitive, we require systems that protect privacy. A gold standard privacy-preserving system will satisfy perfect secrecy, meaning that interactions with the system provably reveal no additional private information to adversaries. This guarantee should hold even as we perform multiple personal tasks over the same underlying data. However, privacy and quality appear to be in tension in existing systems for personal tasks. Neural models typically require lots of training to perform well, while individual users typically hold a limited scale of data, so the systems propose to learn from the aggregate data of multiple users. This violates perfect secrecy and instead, in the last few years, academics have defended these solutions using statistical notions of privacy -- i.e., the probability of learning private information about a user should be reasonably low. Given the vulnerabilities of these solutions, we explore whether the strong perfect secrecy guarantee can be achieved using recent zero-to-few sample adaptation techniques enabled by foundation models. In response, we propose FOCUS, a framework for personal tasks. Evaluating on popular privacy benchmarks, we find the approach, satisfying perfect secrecy, competes with strong collaborative learning baselines on 6 of 7 tasks. We empirically analyze the proposal, highlighting the opportunities and limitations across task types, and model inductive biases and sizes.
Reasoning over Public and Private Data in Retrieval-Based Systems
Mar 14, 2022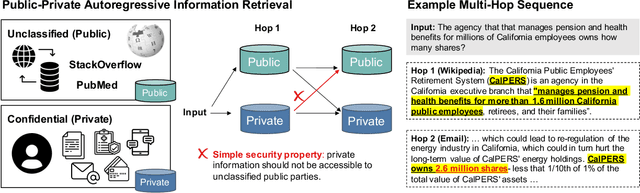


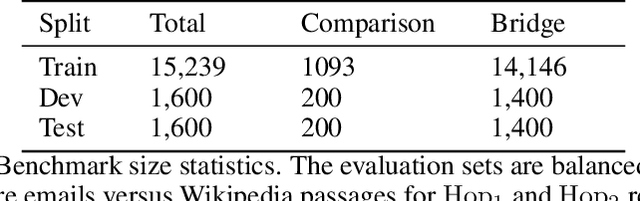
Users and organizations are generating ever-increasing amounts of private data from a wide range of sources. Incorporating private data is important to personalize open-domain applications such as question-answering, fact-checking, and personal assistants. State-of-the-art systems for these tasks explicitly retrieve relevant information to a user question from a background corpus before producing an answer. While today's retrieval systems assume the corpus is fully accessible, users are often unable or unwilling to expose their private data to entities hosting public data. We first define the PUBLIC-PRIVATE AUTOREGRESSIVE INFORMATION RETRIEVAL (PAIR) privacy framework for the novel retrieval setting over multiple privacy scopes. We then argue that an adequate benchmark is missing to study PAIR since existing textual benchmarks require retrieving from a single data distribution. However, public and private data intuitively reflect different distributions, motivating us to create ConcurrentQA, the first textual QA benchmark to require concurrent retrieval over multiple data-distributions. Finally, we show that existing systems face large privacy vs. performance tradeoffs when applied to our proposed retrieval setting and investigate how to mitigate these tradeoffs.
Metadata Shaping: Natural Language Annotations for the Tail
Oct 16, 2021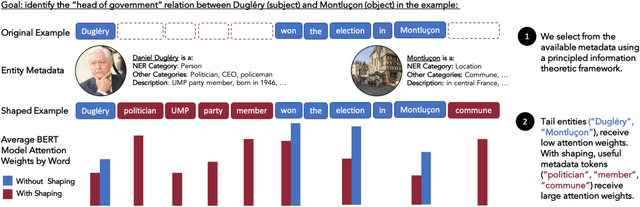
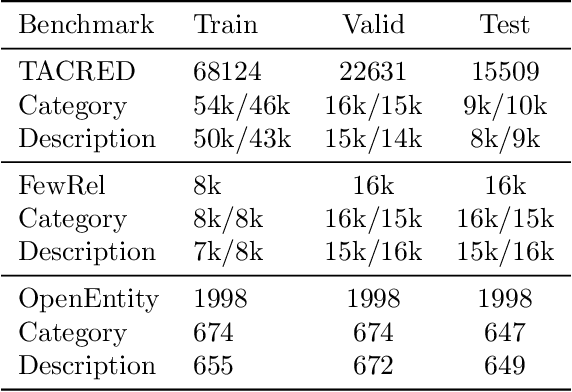
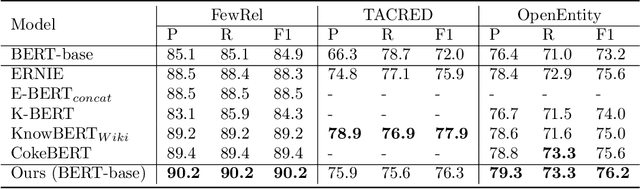
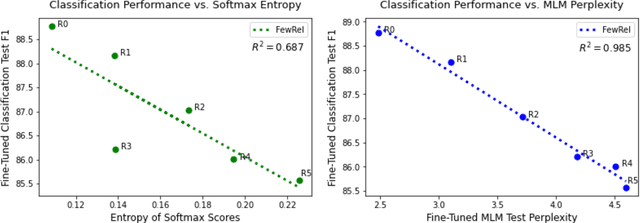
Language models (LMs) have made remarkable progress, but still struggle to generalize beyond the training data to rare linguistic patterns. Since rare entities and facts are prevalent in the queries users submit to popular applications such as search and personal assistant systems, improving the ability of LMs to reliably capture knowledge over rare entities is a pressing challenge studied in significant prior work. Noticing that existing approaches primarily modify the LM architecture or introduce auxiliary objectives to inject useful entity knowledge, we ask to what extent we could match the quality of these architectures using a base LM architecture, and only changing the data? We propose metadata shaping, a method in which readily available metadata, such as entity descriptions and categorical tags, are appended to examples based on information theoretic metrics. Intuitively, if metadata corresponding to popular entities overlap with metadata for rare entities, the LM may be able to better reason about the rare entities using patterns learned from similar popular entities. On standard entity-rich tasks (TACRED, FewRel, OpenEntity), with no changes to the LM whatsoever, metadata shaping exceeds the BERT-baseline by up to 5.3 F1 points, and achieves or competes with state-of-the-art results. We further show the improvements are up to 10x larger on examples containing tail versus popular entities.