 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoLCATs: On Low-Rank Linearizing of Large Language Models
Oct 14, 2024



Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. We base these steps on two findings. First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer"). Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
Just read twice: closing the recall gap for recurrent language models
Jul 07, 2024



Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives $11.0 \pm 1.3$ points of improvement, averaged across $16$ recurrent LMs and the $6$ ICL tasks, with $11.9\times$ higher throughput than FlashAttention-2 for generation prefill (length $32$k, batch size $16$, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides $99\%$ of Transformer quality at $360$M params., $30$B tokens and $96\%$ at $1.3$B params., $50$B tokens on average across the tasks, with $19.2\times$ higher throughput for prefill than FA2.
Explaining vague language
Apr 28, 2024



Why is language vague? Vagueness may be explained and rationalized if it can be shown that vague language is more useful to speaker and hearer than precise language. In a well-known paper, Lipman proposes a game-theoretic account of vagueness in terms of mixed strategy that leads to a puzzle: vagueness cannot be strictly better than precision at equilibrium. More recently, \'Egr\'e, Spector, Mortier and Verheyen have put forward a Bayesian account of vagueness establishing that using vague words can be strictly more informative than using precise words. This paper proposes to compare both results and to explain why they are not in contradiction. Lipman's definition of vagueness relies exclusively on a property of signaling strategies, without making any assumptions about the lexicon, whereas \'Egr\'e et al.'s involves a layer of semantic content. We argue that the semantic account of vagueness is needed, and more adequate and explanatory of vagueness.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023



Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
Accelerating LLM Inference with Staged Speculative Decoding
Aug 08, 2023



Recent advances with large language models (LLM) illustrate their diverse capabilities. We propose a novel algorithm, staged speculative decoding, to accelerate LLM inference in small-batch, on-device scenarios. We address the low arithmetic intensity of small-batch inference by improving upon previous work in speculative decoding. First, we restructure the speculative batch as a tree, which reduces generation costs and increases the expected tokens per batch. Second, we add a second stage of speculative decoding. Taken together, we reduce single-batch decoding latency by 3.16x with a 762M parameter GPT-2-L model while perfectly preserving output quality.
Exhaustivity and anti-exhaustivity in the RSA framework: Testing the effect of prior beliefs
Feb 14, 2022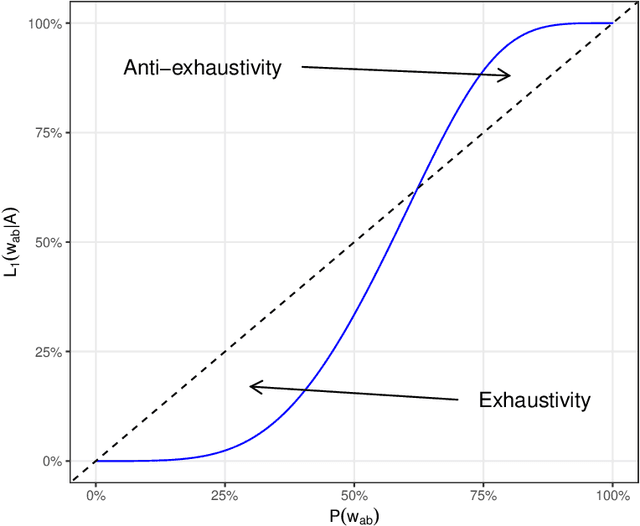
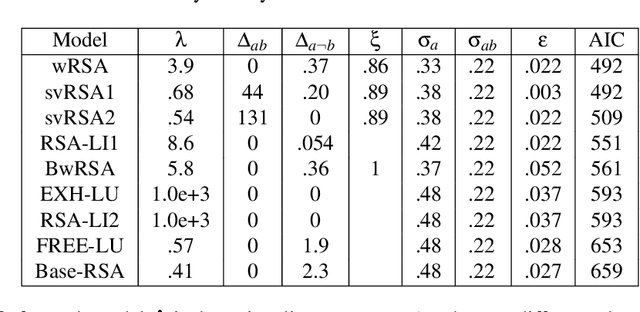

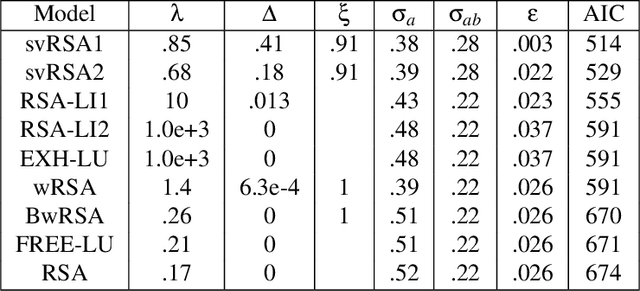
During communication, the interpretation of utterances is sensitive to a listener's probabilistic prior beliefs, something which is captured by one currently influential model of pragmatics, the Rational Speech Act (RSA) framework. In this paper we focus on cases when this sensitivity to priors leads to counterintuitive predictions of the framework. Our domain of interest is exhaustivity effects, whereby a sentence such as "Mary came" is understood to mean that only Mary came. We show that in the baseline RSA model, under certain conditions, anti-exhaustive readings are predicted (e.g., "Mary came" would be used to convey that both Mary and Peter came). The specific question we ask is the following: should exhaustive interpretations be derived as purely pragmatic inferences (as in the classical Gricean view, endorsed in the baseline RSA model), or should they rather be generated by an encapsulated semantic mechanism (as argued in some of the recent formal literature)? To answer this question, we provide a detailed theoretical analysis of different RSA models and evaluate them against data obtained in a new study which tested the effects of prior beliefs on both production and comprehension, improving on previous empirical work. We found no anti-exhaustivity effects, but observed that message choice is sensitive to priors, as predicted by the RSA framework overall. The best models turn out to be those which include an encapsulated exhaustivity mechanism (as other studies concluded on the basis of very different data). We conclude that, on the one hand, in the division of labor between semantics and pragmatics, semantics plays a larger role than is often thought, but, on the other hand, the tradeoff between informativity and cost which characterizes all RSA models does play a central role for genuine pragmatic effects.
Bounding the Last Mile: Efficient Learned String Indexing
Nov 29, 2021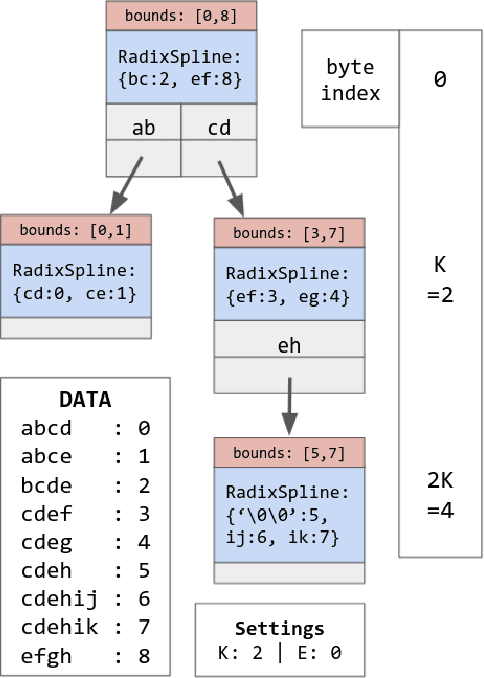
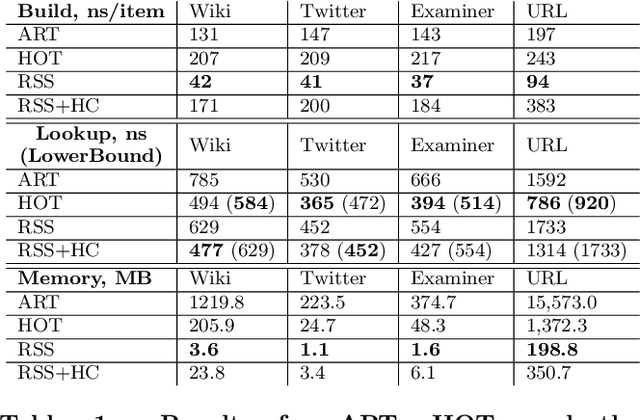
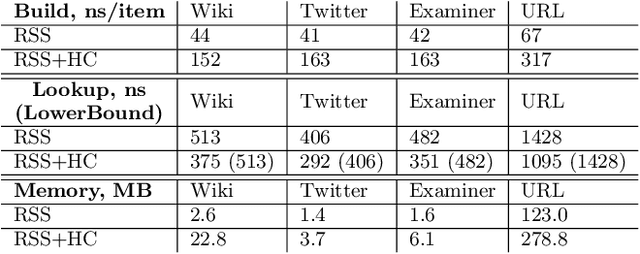
We introduce the RadixStringSpline (RSS) learned index structure for efficiently indexing strings. RSS is a tree of radix splines each indexing a fixed number of bytes. RSS approaches or exceeds the performance of traditional string indexes while using 7-70$\times$ less memory. RSS achieves this by using the minimal string prefix to sufficiently distinguish the data unlike most learned approaches which index the entire string. Additionally, the bounded-error nature of RSS accelerates the last mile search and also enables a memory-efficient hash-table lookup accelerator. We benchmark RSS on several real-world string datasets against ART and HOT. Our experiments suggest this line of research may be promising for future memory-intensive database applications.
On the Optimality of Vagueness: "Around", "Between", and the Gricean Maxims
Sep 08, 2020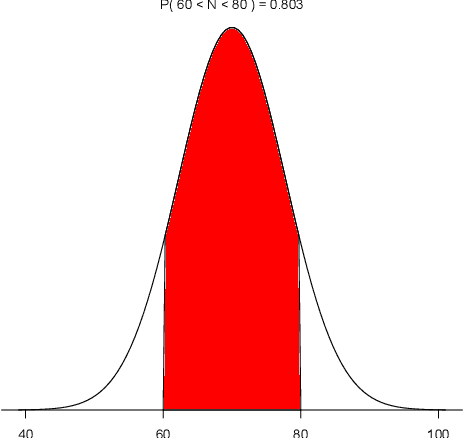

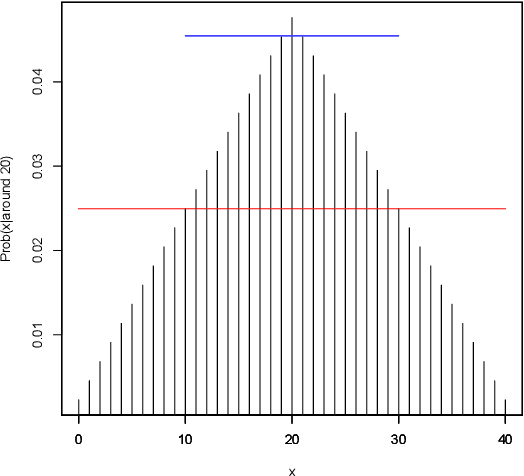

Why is our language vague? We argue that in contexts in which a cooperative speaker is not perfectly informed about the world, the use of vague expressions can offer an optimal tradeoff between truthfulness (Gricean Quality) and informativeness (Gricean Quantity). Focusing on expressions of approximation such as "around", which are semantically vague, we show that they allow the speaker to convey indirect probabilistic information, in a way that gives the listener a more accurate representation of the information available to the speaker than any more precise expression would (intervals of the form "between"). We give a probabilistic treatment of the interpretation of "around", and offer a model for the interpretation and use of "around"-statements within the Rational Speech Act (RSA) framework. Our model differs in substantive ways from the Lexical Uncertainty model often used within the RSA framework for vague predicates.
Preventing Adversarial Use of Datasets through Fair Core-Set Construction
Oct 24, 2019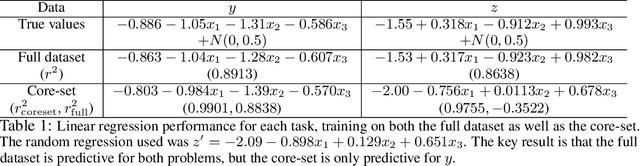
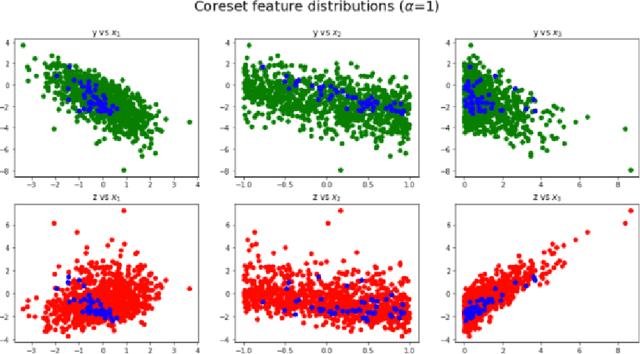
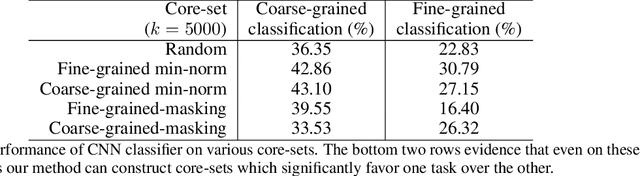
We propose improving the privacy properties of a dataset by publishing only a strategically chosen "core-set" of the data containing a subset of the instances. The core-set allows strong performance on primary tasks, but forces poor performance on unwanted tasks. We give methods for both linear models and neural networks and demonstrate their efficacy on data.
Sample-Efficient Reinforcement Learning through Transfer and Architectural Priors
Jan 07, 2018

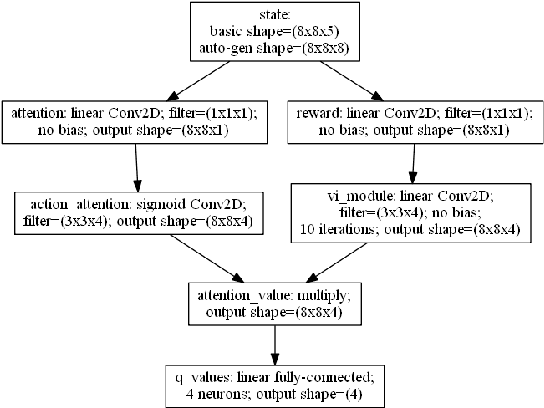
Recent work in deep reinforcement learning has allowed algorithms to learn complex tasks such as Atari 2600 games just from the reward provided by the game, but these algorithms presently require millions of training steps in order to learn, making them approximately five orders of magnitude slower than humans. One reason for this is that humans build robust shared representations that are applicable to collections of problems, making it much easier to assimilate new variants. This paper first introduces the idea of automatically-generated game sets to aid in transfer learning research, and then demonstrates the utility of shared representations by showing that models can substantially benefit from the incorporation of relevant architectural priors. This technique affords a remarkable 50x positive transfer on a toy problem-set.