 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopping Reasoning Bench: An Expert-Authored Benchmark for Multi-Turn Conversational Shopping Assistants
Jun 10, 2026Conversational shopping assistants now serve hundreds of millions of customers, yet no existing benchmark jointly evaluates the open-ended multi-turn reasoning, domain expertise, and criterion-level quality that real shopping conversations demand. Shopping reasoning is unique among language model applications. Unlike factual question answering or verifiable code generation, it requires balancing subjective preferences, budget constraints, and cross-product trade-offs across multi-turn dialogue, capabilities absent from previous e-commerce and general-purpose benchmarks. We introduce the Shopping Reasoning Bench, an expert-authored benchmark of 525 missions (232 single-turn, 293 multi-turn) with 10863 importance-weighted binary rubrics authored by retail domain experts. These criteria are organized under a taxonomy of five reasoning categories and fifteen subcategories covering diverse demands such as preference refinement, trade-off analysis, and compatibility assessment. An evaluation of nine models across three families (GPT, Claude, Gemini) shows that pass rates reach only 57--77% overall. On multi-turn missions, all models score 13--29 points lower on optional above-and-beyond criteria than on required ones, and performance degrades 4--18 points as conversations progress. These gaps show that current models handle basic shopping assistance but fall short of expert-level advice, making Shopping Reasoning Bench a challenging testbed for future shopping assistant development.
From Narratives to Numbers: Valid Inference Using Language Model Predictions from Verbal Autopsy Narratives
Apr 03, 2024



In settings where most deaths occur outside the healthcare system, verbal autopsies (VAs) are a common tool to monitor trends in causes of death (COD). VAs are interviews with a surviving caregiver or relative that are used to predict the decedent's COD. Turning VAs into actionable insights for researchers and policymakers requires two steps (i) predicting likely COD using the VA interview and (ii) performing inference with predicted CODs (e.g. modeling the breakdown of causes by demographic factors using a sample of deaths). In this paper, we develop a method for valid inference using outcomes (in our case COD) predicted from free-form text using state-of-the-art NLP techniques. This method, which we call multiPPI++, extends recent work in "prediction-powered inference" to multinomial classification. We leverage a suite of NLP techniques for COD prediction and, through empirical analysis of VA data, demonstrate the effectiveness of our approach in handling transportability issues. multiPPI++ recovers ground truth estimates, regardless of which NLP model produced predictions and regardless of whether they were produced by a more accurate predictor like GPT-4-32k or a less accurate predictor like KNN. Our findings demonstrate the practical importance of inference correction for public health decision-making and suggests that if inference tasks are the end goal, having a small amount of contextually relevant, high quality labeled data is essential regardless of the NLP algorithm.
Ellipse Detection and Localization with Applications to Knots in Sawn Lumber Images
Nov 10, 2020
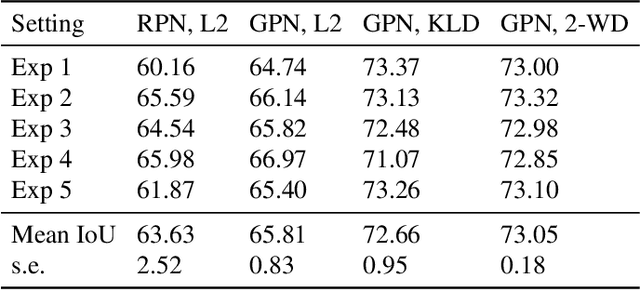
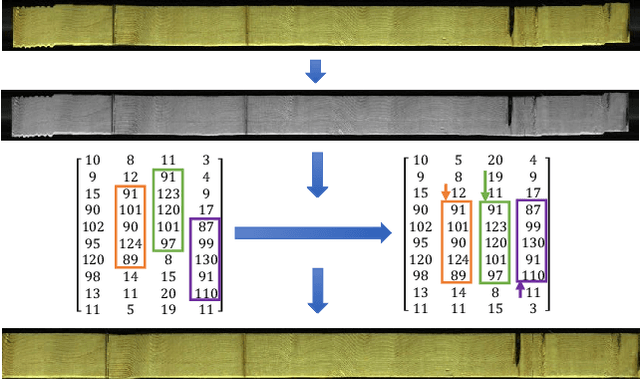

While general object detection has seen tremendous progress, localization of elliptical objects has received little attention in the literature. Our motivating application is the detection of knots in sawn timber images, which is an important problem since the number and types of knots are visual characteristics that adversely affect the quality of sawn timber. We demonstrate how models can be tailored to the elliptical shape and thereby improve on general purpose detectors; more generally, elliptical defects are common in industrial production, such as enclosed air bubbles when casting glass or plastic. In this paper, we adapt the Faster R-CNN with its Region Proposal Network (RPN) to model elliptical objects with a Gaussian function, and extend the existing Gaussian Proposal Network (GPN) architecture by adding the region-of-interest pooling and regression branches, as well as using the Wasserstein distance as the loss function to predict the precise locations of elliptical objects. Our proposed method has promising results on the lumber knot dataset: knots are detected with an average intersection over union of 73.05%, compared to 63.63% for general purpose detectors. Specific to the lumber application, we also propose an algorithm to correct any misalignment in the raw timber images during scanning, and contribute the first open-source lumber knot dataset by labeling the elliptical knots in the preprocessed images.