 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Debiased Models with Dynamic Gradient Alignment and Bias-conflicting Sample Mining
Nov 25, 2021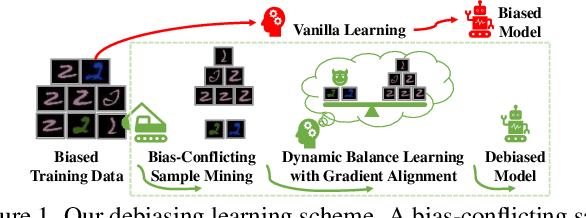
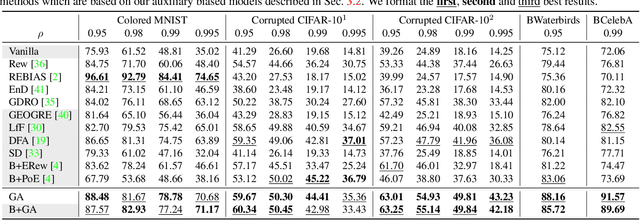

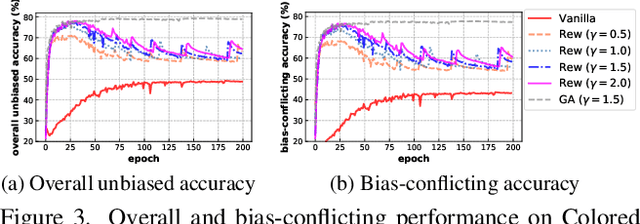
Deep neural networks notoriously suffer from dataset biases which are detrimental to model robustness, generalization and fairness. In this work, we propose a two-stage debiasing scheme to combat against the intractable unknown biases. Starting by analyzing the factors of the presence of biased models, we design a novel learning objective which cannot be reached by relying on biases alone. Specifically, debiased models are achieved with the proposed Gradient Alignment (GA) which dynamically balances the contributions of bias-aligned and bias-conflicting samples (refer to samples with/without bias cues respectively) throughout the whole training process, enforcing models to exploit intrinsic cues to make fair decisions. While in real-world scenarios, the potential biases are extremely hard to discover and prohibitively expensive to label manually. We further propose an automatic bias-conflicting sample mining method by peer-picking and training ensemble without prior knowledge of bias information. Experiments conducted on multiple datasets in various settings demonstrate the effectiveness and robustness of our proposed scheme, which successfully alleviates the negative impact of unknown biases and achieves state-of-the-art performance.
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Aug 04, 2021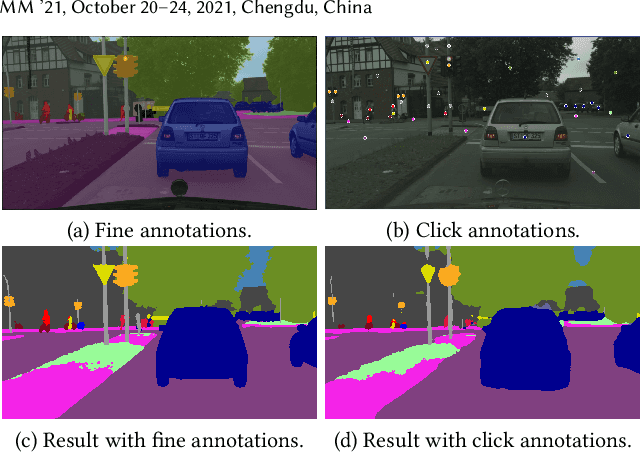
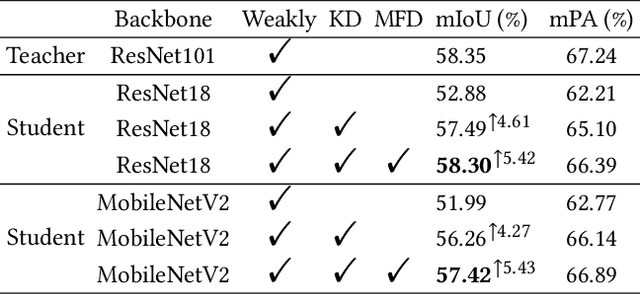
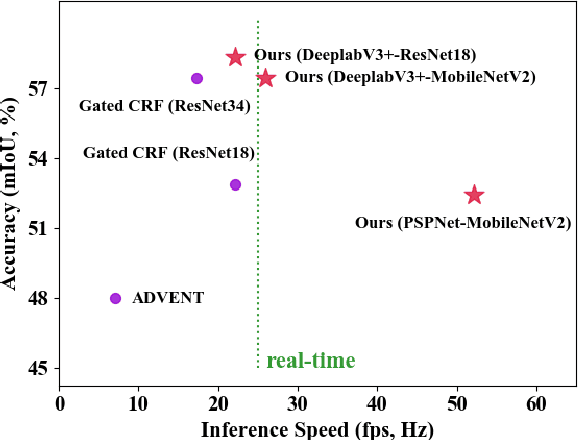
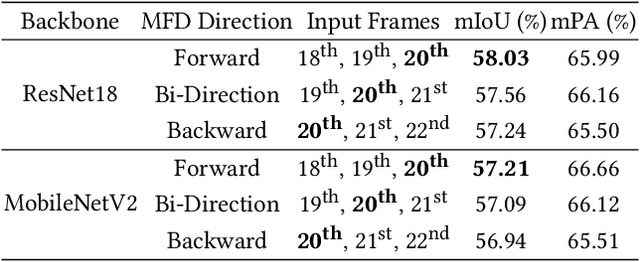
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Towards A Category-extended Object Detector without Relabeling or Conflicts
Dec 28, 2020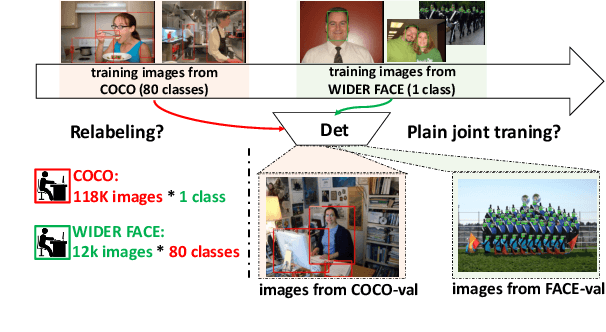

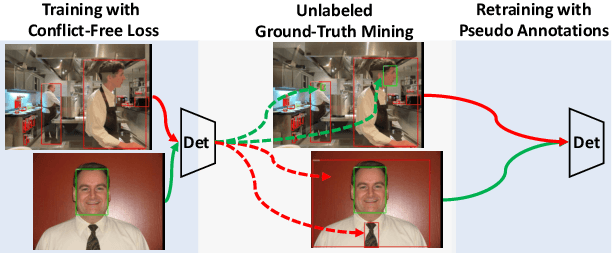
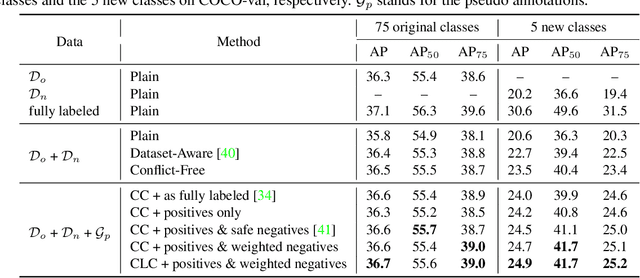
Object detectors are typically learned based on fully-annotated training data with fixed pre-defined categories. However, not all possible categories of interest can be known beforehand, as classes are often required to be increased progressively in many realistic applications. In such scenario, only the original training set annotated with the old classes and some new training data labeled with the new classes are available. In this paper, we aim at leaning a strong unified detector that can handle all categories based on the limited datasets without extra manual labor. Vanilla joint training without considering label ambiguity leads to heavy biases and poor performance due to the incomplete annotations. To avoid such situation, we propose a practical framework which focuses on three aspects: better base model, better unlabeled ground-truth mining strategy and better retraining method with pseudo annotations. First, a conflict-free loss is proposed to obtain a usable base detector. Second, we employ Monte Carlo Dropout to calculate the localization confidence, combined with the classification confidence, to mine more accurate bounding boxes. Third, we explore several strategies for making better use of pseudo annotations during retraining to achieve more powerful detectors. Extensive experiments conducted on multiple datasets demonstrate the effectiveness of our framework for category-extended object detectors.
Neural Network-based Automatic Factor Construction
Aug 14, 2020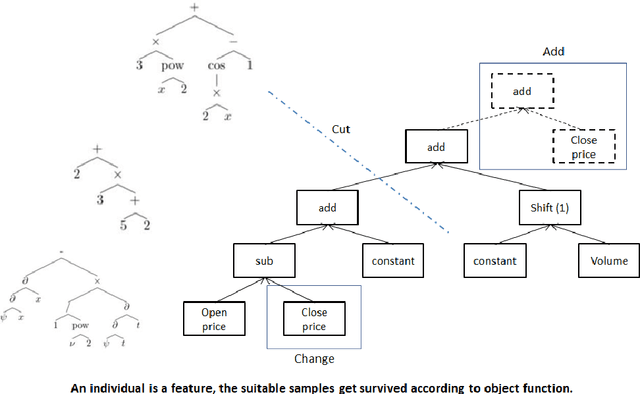
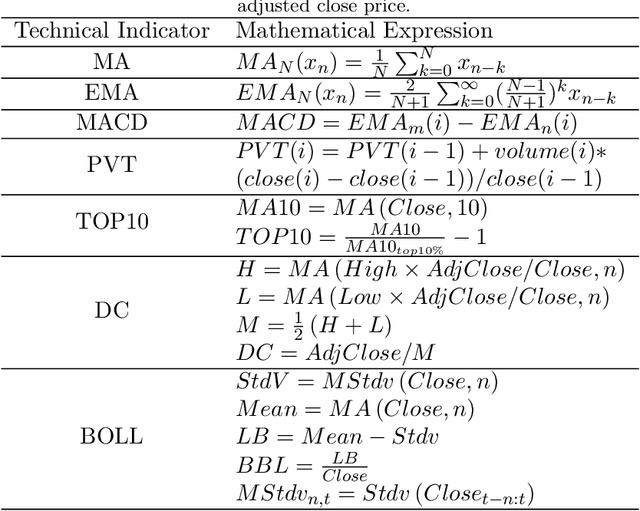
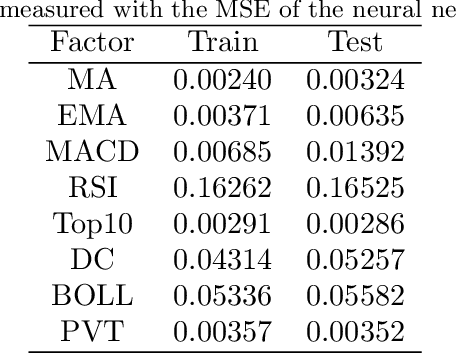
Instead of conducting manual factor construction based on traditional and behavioural finance analysis, academic researchers and quantitative investment managers have leveraged Genetic Programming (GP) as an automatic feature construction tool in recent years, which builds reverse polish mathematical expressions from trading data into new factors. However, with the development of deep learning, more powerful feature extraction tools are available. This paper proposes Neural Network-based Automatic Factor Construction (NNAFC), a tailored neural network framework that can automatically construct diversified financial factors based on financial domain knowledge and a variety of neural network structures. The experiment results show that NNAFC can construct more informative and diversified factors than GP, to effectively enrich the current factor pool. For the current market, both fully connected and recurrent neural network structures are better at extracting information from financial time series than convolution neural network structures. Moreover, new factors constructed by NNAFC can always improve the return, Sharpe ratio, and the max draw-down of a multi-factor quantitative investment strategy due to their introducing more information and diversification to the existing factor pool.
Efficient Black-Box Adversarial Attack Guided by the Distribution of Adversarial Perturbations
Jun 15, 2020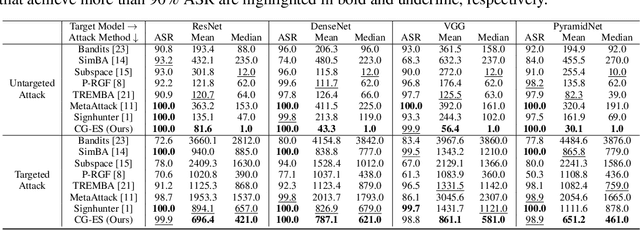
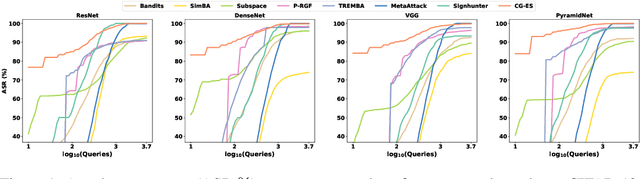
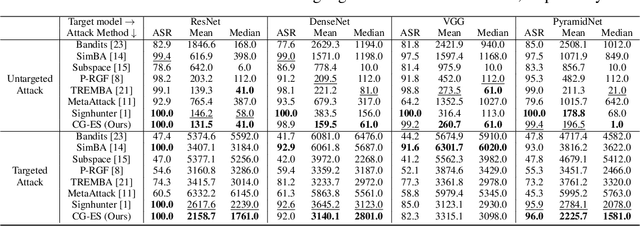
This work studied the score-based black-box adversarial attack problem, where only a continuous score is returned for each query, while the structure and parameters of the attacked model are unknown. A promising approach to solve this problem is evolution strategies (ES), which introduces a search distribution to sample perturbations that are likely to be adversarial. Gaussian distribution is widely adopted as the search distribution in the standard ES algorithm. However, it may not be flexible enough to capture the diverse distributions of adversarial perturbations around different benign examples. In this work, we propose to transform the Gaussian-distributed variable to another space through a conditional flow-based model, to enhance the capability and flexibility of capturing the intrinsic distribution of adversarial perturbations conditioned on the benign example. Besides, to further enhance the query efficiency, we propose to pre-train the conditional flow model based on some white-box surrogate models, utilizing the transferability of adversarial perturbations across different models, which has been widely observed in the literature of adversarial examples. Consequently, the proposed method could take advantage of both query-based and transfer-based attack methods, to achieve satisfying attack performance on both effectiveness and efficiency. Extensive experiments of attacking four target models on CIFAR-10 and Tiny-ImageNet verify the superior performance of the proposed method to state-of-the-art methods.
Rethinking the Trigger of Backdoor Attack
Apr 09, 2020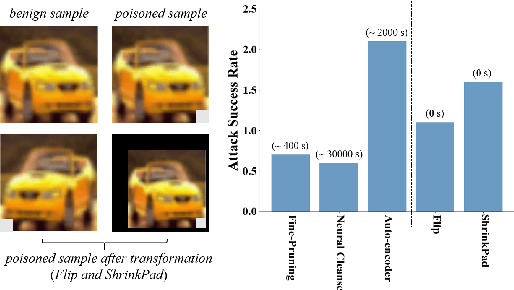
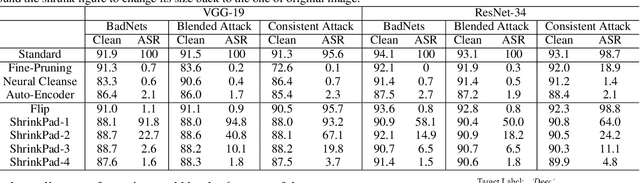
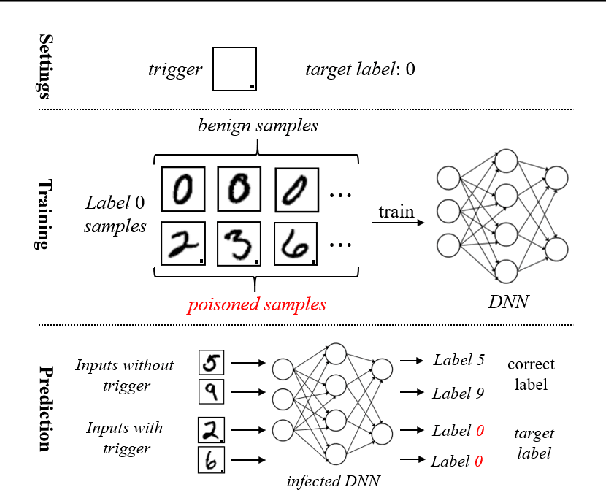
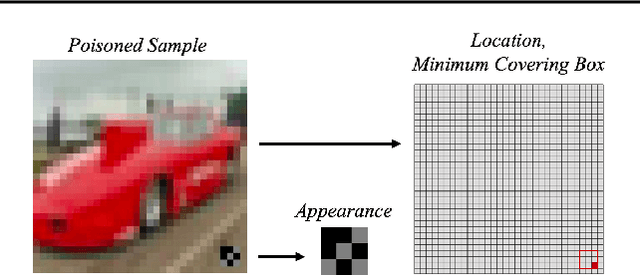
In this work, we study the problem of backdoor attacks, which add a specific trigger ($i.e.$, a local patch) onto some training images to enforce that the testing images with the same trigger are incorrectly predicted while the natural testing examples are correctly predicted by the trained model. Many existing works adopted the setting that the triggers across the training and testing images follow the same appearance and are located at the same area. However, we observe that if the appearance or location of the trigger is slightly changed, then the attack performance may degrade sharply. According to this observation, we propose to spatially transform ($e.g.$, flipping and scaling) the testing image, such that the appearance and location of the trigger (if exists) will be changed. This simple strategy is experimentally verified to be effective to defend many state-of-the-art backdoor attack methods. Furthermore, to enhance the robustness of the backdoor attacks, we propose to conduct the random spatial transformation on the training images with the trigger before feeding into the training process. Extensive experiments verify that the proposed backdoor attack is robust to spatial transformations.
Toward Adversarial Robustness via Semi-supervised Robust Training
Mar 16, 2020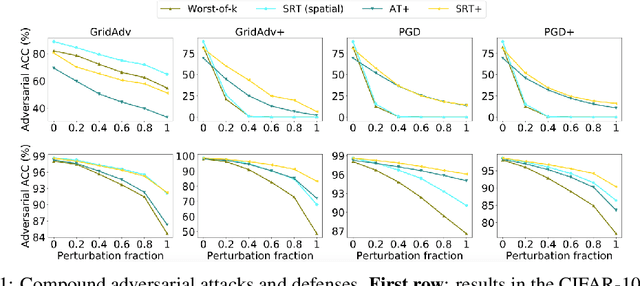
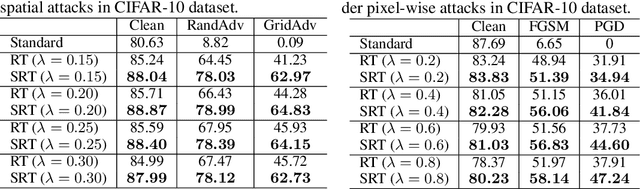
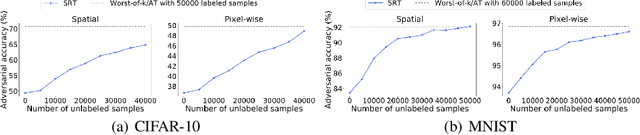
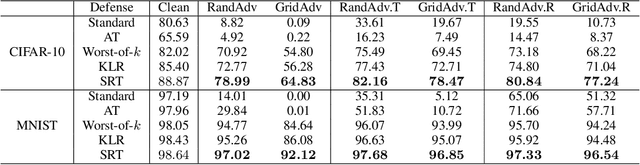
Adversarial examples have been shown to be the severe threat to deep neural networks (DNNs). One of the most effective adversarial defense methods is adversarial training (AT) through minimizing the adversarial risk $R_{adv}$, which encourages both the benign example $x$ and its adversarially perturbed neighborhoods within the $\ell_{p}$-ball to be predicted as the ground-truth label. In this work, we propose a novel defense method, the robust training (RT), by jointly minimizing two separated risks ($R_{stand}$ and $R_{rob}$), which is with respect to the benign example and its neighborhoods respectively. The motivation is to explicitly and jointly enhance the accuracy and the adversarial robustness. We prove that $R_{adv}$ is upper-bounded by $R_{stand} + R_{rob}$, which implies that RT has similar effect as AT. Intuitively, minimizing the standard risk enforces the benign example to be correctly predicted, and the robust risk minimization encourages the predictions of the neighbor examples to be consistent with the prediction of the benign example. Besides, since $R_{rob}$ is independent of the ground-truth label, RT is naturally extended to the semi-supervised mode ($i.e.$, SRT), to further enhance the adversarial robustness. Moreover, we extend the $\ell_{p}$-bounded neighborhood to a general case, which covers different types of perturbations, such as the pixel-wise ($i.e.$, $x + \delta$) or the spatial perturbation ($i.e.$, $ AX + b$). Extensive experiments on benchmark datasets not only verify the superiority of the proposed SRT method to state-of-the-art methods for defensing pixel-wise or spatial perturbations separately, but also demonstrate its robustness to both perturbations simultaneously. The code for reproducing main results is available at \url{https://github.com/THUYimingLi/Semi-supervised_Robust_Training}.
Adversarial Attack on Deep Product Quantization Network for Image Retrieval
Feb 26, 2020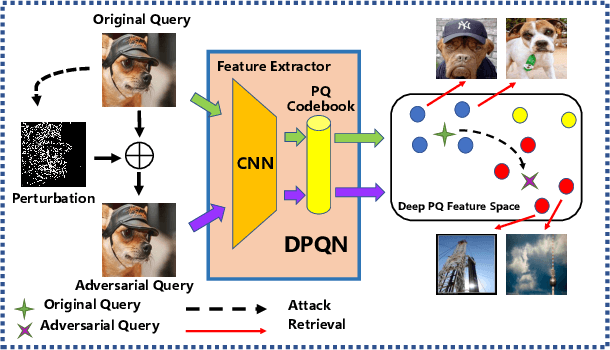
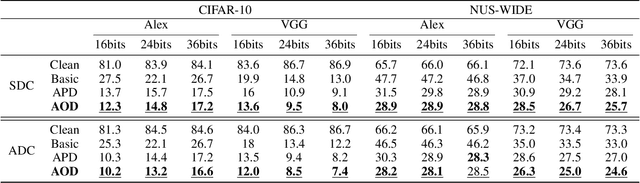
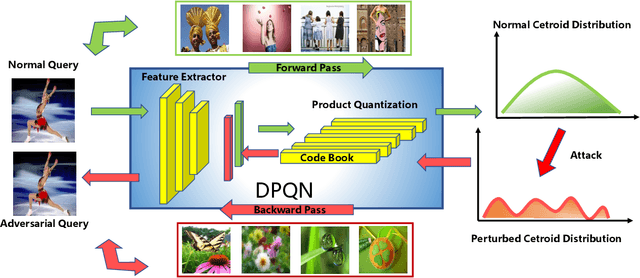
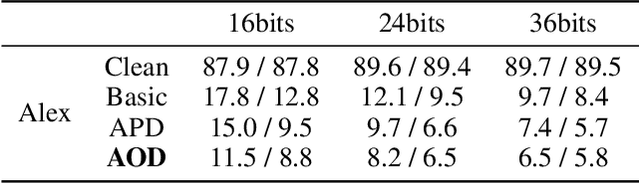
Deep product quantization network (DPQN) has recently received much attention in fast image retrieval tasks due to its efficiency of encoding high-dimensional visual features especially when dealing with large-scale datasets. Recent studies show that deep neural networks (DNNs) are vulnerable to input with small and maliciously designed perturbations (a.k.a., adversarial examples). This phenomenon raises the concern of security issues for DPQN in the testing/deploying stage as well. However, little effort has been devoted to investigating how adversarial examples affect DPQN. To this end, we propose product quantization adversarial generation (PQ-AG), a simple yet effective method to generate adversarial examples for product quantization based retrieval systems. PQ-AG aims to generate imperceptible adversarial perturbations for query images to form adversarial queries, whose nearest neighbors from a targeted product quantizaiton model are not semantically related to those from the original queries. Extensive experiments show that our PQ-AQ successfully creates adversarial examples to mislead targeted product quantization retrieval models. Besides, we found that our PQ-AG significantly degrades retrieval performance in both white-box and black-box settings.
Automatic financial feature construction based on neural network
Jan 30, 2020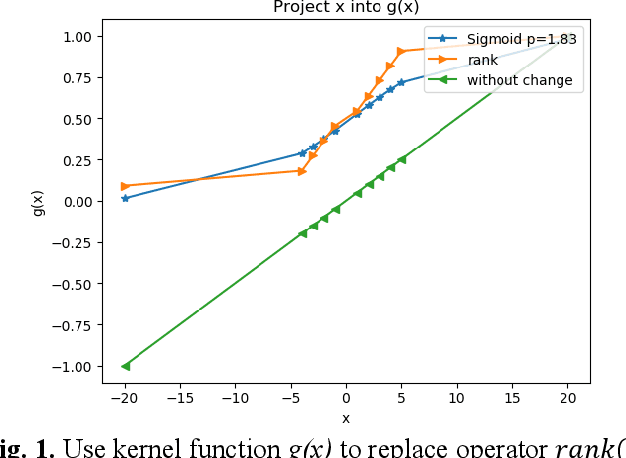
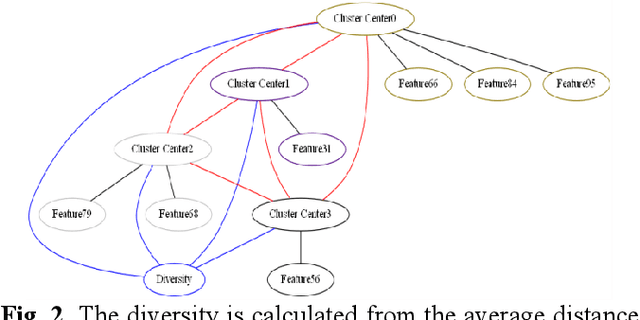
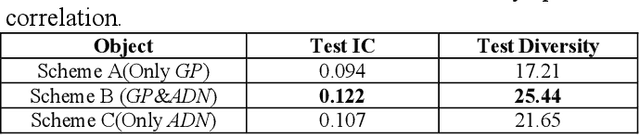
In automatic financial feature construction task, the state of the art technic leverages reverse polish expression to represent the features, then use genetic programming (GP) to conduct its evolution process. In this paper, we propose a new framework based on neural network, alpha discovery neural network (ADNN). In this work, we made several contributions. Firstly, in this task, we make full use of neural network's overwhelming advantage in feature extraction to construct highly informative features. Secondly, we use domain knowledge to design the object function, batch size, and sampling rules. Thirdly, we use pre-training to replace the GP's evolution process. According to neural network's universal approximation theorem, pre-training can conduct a more effective and explainable evolution process. Experiment shows that ADNN can remarkably produce more diversified and higher informative features than GP. Besides, ADNN can serve as a data augmentation algorithm. It further improves the the performance of financial features constructed by GP.
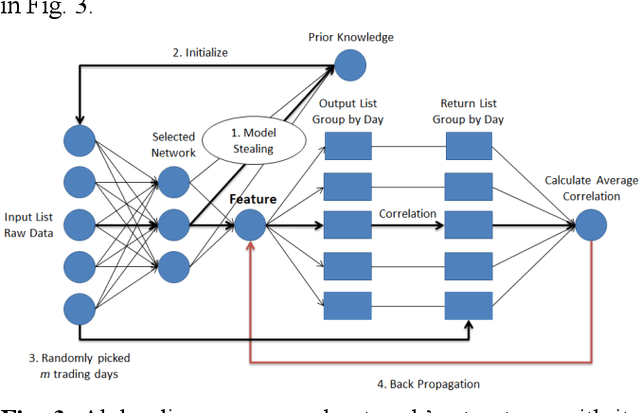
Alpha Discovery Neural Network based on Prior Knowledge
Jan 03, 2020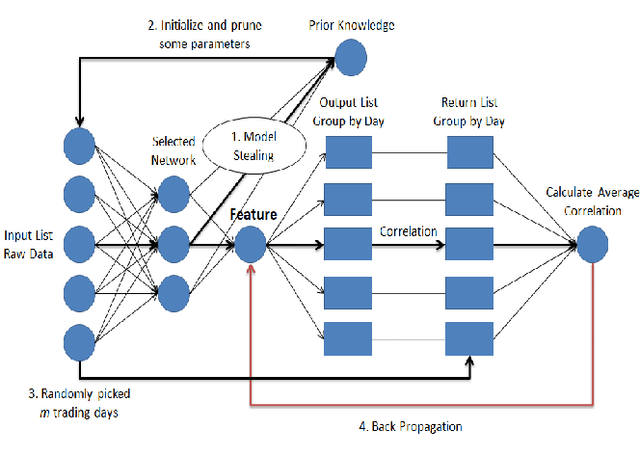

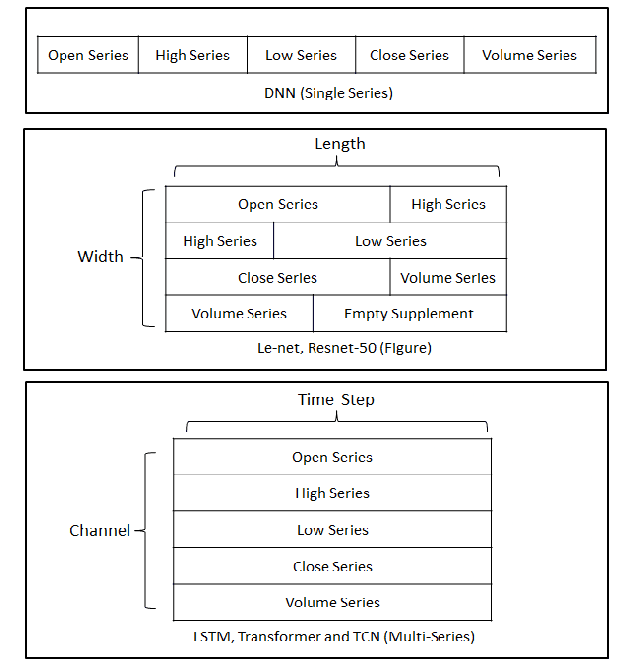
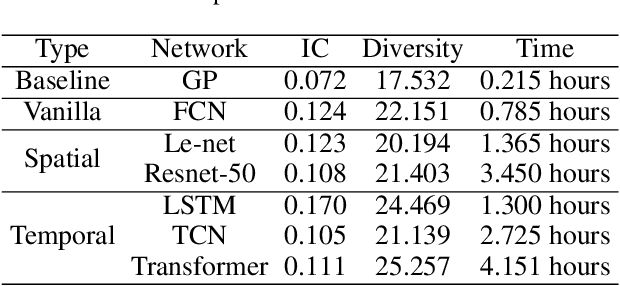
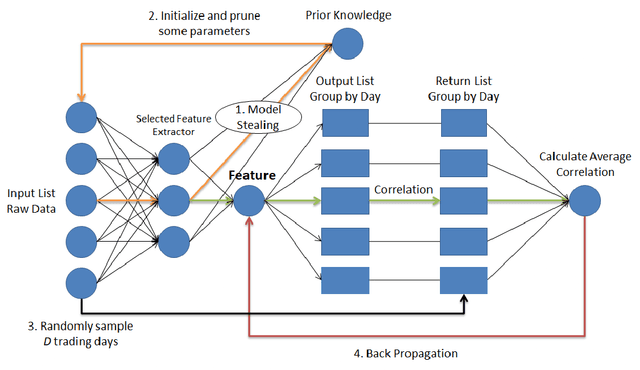
In financial automatic feature construction task, genetic programming is the state-of-the-art-technic. It uses reverse polish expression to represent features and then uses genetic programming to simulate the evolution process. With the development of deep learning, there are more powerful feature extractors for option. And we think that comprehending the relationship between different feature extractors and data shall be the key. In this work, we put prior knowledge into alpha discovery neural network, combined with different kinds of feature extractors to do this task. We find that in the same type of network, simple network structure can produce more informative features than sophisticated network structure, and it costs less training time. However, complex network is good at providing more diversified features. In both experiment and real business environment, fully-connected network and recurrent network are good at extracting information from financial time series, but convolution network structure can not effectively extract this information.