 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALO: A Versatile Anytime Framework for LiDAR-based Object Detection Deep Neural Networks
Sep 17, 2024



This work addresses the challenge of adapting dynamic deadline requirements for LiDAR object detection deep neural networks (DNNs). The computing latency of object detection is critically important to ensure safe and efficient navigation. However, state-of-the-art LiDAR object detection DNNs often exhibit significant latency, hindering their real-time performance on resource-constrained edge platforms. Therefore, a tradeoff between detection accuracy and latency should be dynamically managed at runtime to achieve optimum results. In this paper, we introduce VALO (Versatile Anytime algorithm for LiDAR Object detection), a novel data-centric approach that enables anytime computing of 3D LiDAR object detection DNNs. VALO employs a deadline-aware scheduler to selectively process input regions, making execution time and accuracy tradeoffs without architectural modifications. Additionally, it leverages efficient forecasting of past detection results to mitigate possible loss of accuracy due to partial processing of input. Finally, it utilizes a novel input reduction technique within its detection heads to significantly accelerate execution without sacrificing accuracy. We implement VALO on state-of-the-art 3D LiDAR object detection networks, namely CenterPoint and VoxelNext, and demonstrate its dynamic adaptability to a wide range of time constraints while achieving higher accuracy than the prior state-of-the-art. Code is available athttps://github.com/CSL-KU/VALO}{github.com/CSL-KU/VALO.
Anytime-Lidar: Deadline-aware 3D Object Detection
Aug 25, 2022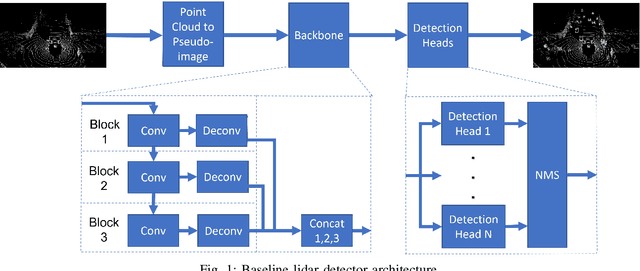
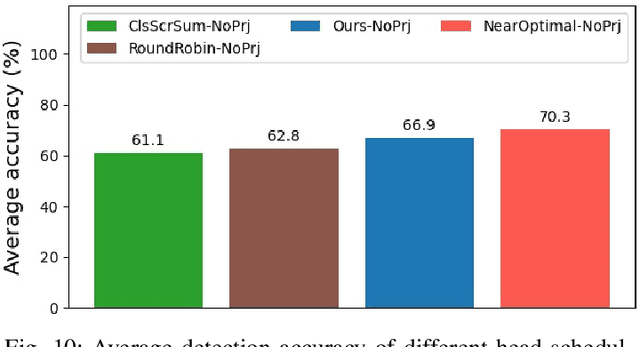
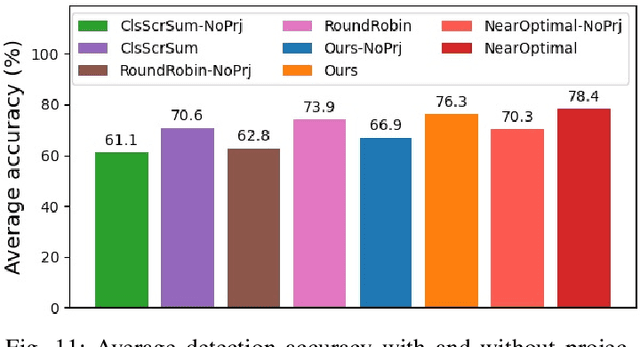
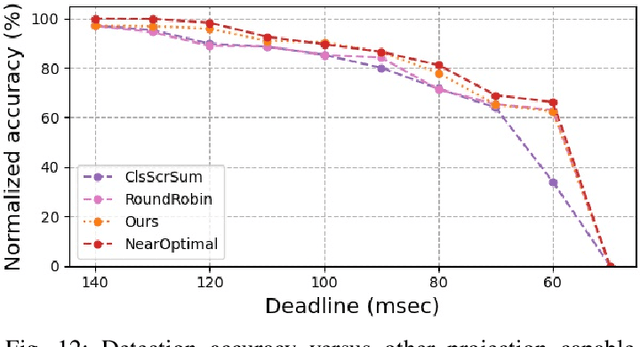
In this work, we present a novel scheduling framework enabling anytime perception for deep neural network (DNN) based 3D object detection pipelines. We focus on computationally expensive region proposal network (RPN) and per-category multi-head detector components, which are common in 3D object detection pipelines, and make them deadline-aware. We propose a scheduling algorithm, which intelligently selects the subset of the components to make effective time and accuracy trade-off on the fly. We minimize accuracy loss of skipping some of the neural network sub-components by projecting previously detected objects onto the current scene through estimations. We apply our approach to a state-of-art 3D object detection network, PointPillars, and evaluate its performance on Jetson Xavier AGX using nuScenes dataset. Compared to the baselines, our approach significantly improve the network's accuracy under various deadline constraints.
CrossRoI: Cross-camera Region of Interest Optimization for Efficient Real Time Video Analytics at Scale
May 13, 2021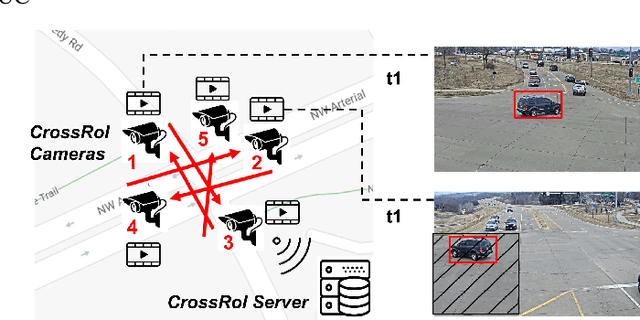
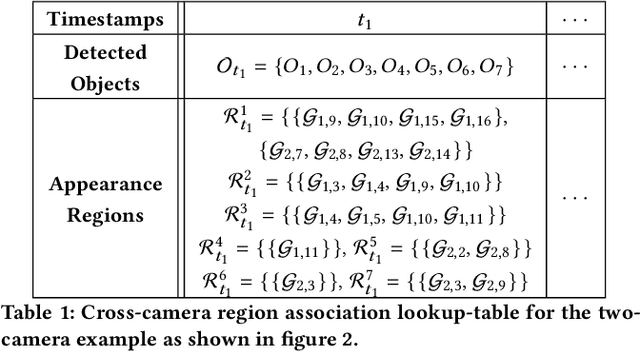
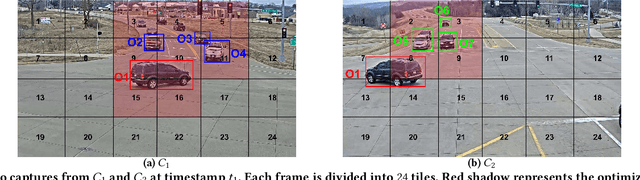
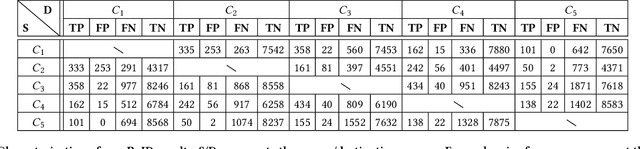
Video cameras are pervasively deployed in city scale for public good or community safety (i.e. traffic monitoring or suspected person tracking). However, analyzing large scale video feeds in real time is data intensive and poses severe challenges to network and computation systems today. We present CrossRoI, a resource-efficient system that enables real time video analytics at scale via harnessing the videos content associations and redundancy across a fleet of cameras. CrossRoI exploits the intrinsic physical correlations of cross-camera viewing fields to drastically reduce the communication and computation costs. CrossRoI removes the repentant appearances of same objects in multiple cameras without harming comprehensive coverage of the scene. CrossRoI operates in two phases - an offline phase to establish cross-camera correlations, and an efficient online phase for real time video inference. Experiments on real-world video feeds show that CrossRoI achieves 42% - 65% reduction for network overhead and 25% - 34% reduction for response delay in real time video analytics applications with more than 99% query accuracy, when compared to baseline methods. If integrated with SotA frame filtering systems, the performance gains of CrossRoI reach 50% - 80% (network overhead) and 33% - 61% (end-to-end delay).
Scheduling Real-time Deep Learning Services as Imprecise Computations
Nov 02, 2020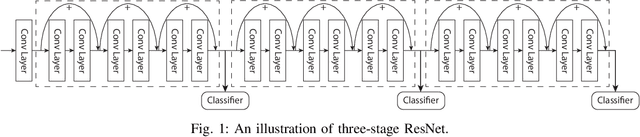
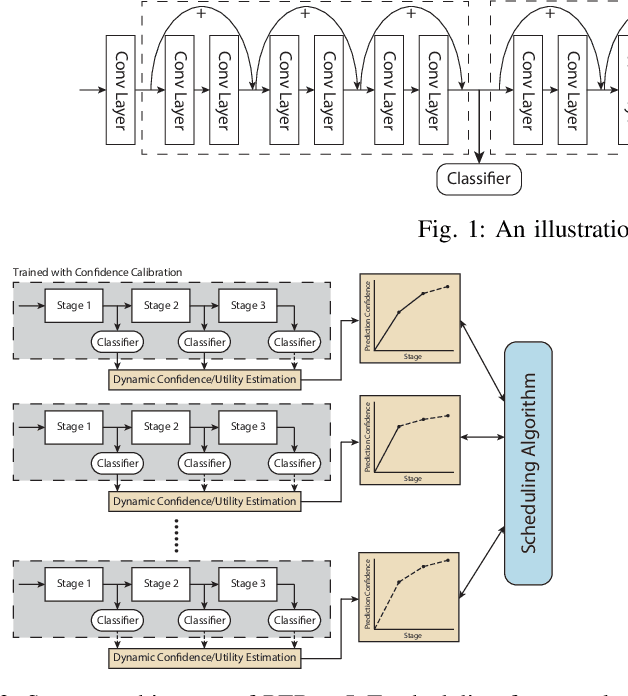
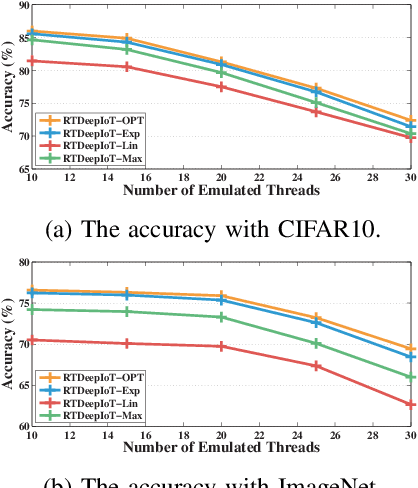
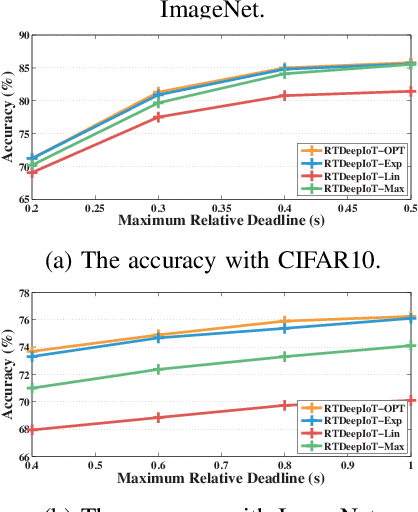
The paper presents an efficient real-time scheduling algorithm for intelligent real-time edge services, defined as those that perform machine intelligence tasks, such as voice recognition, LIDAR processing, or machine vision, on behalf of local embedded devices that are themselves unable to support extensive computations. The work contributes to a recent direction in real-time computing that develops scheduling algorithms for machine intelligence tasks with anytime prediction. We show that deep neural network workflows can be cast as imprecise computations, each with a mandatory part and (several) optional parts whose execution utility depends on input data. The goal of the real-time scheduler is to maximize the average accuracy of deep neural network outputs while meeting task deadlines, thanks to opportunistic shedding of the least necessary optional parts. The work is motivated by the proliferation of increasingly ubiquitous but resource-constrained embedded devices (for applications ranging from autonomous cars to the Internet of Things) and the desire to develop services that endow them with intelligence. Experiments on recent GPU hardware and a state of the art deep neural network for machine vision illustrate that our scheme can increase the overall accuracy by 10%-20% while incurring (nearly) no deadline misses.
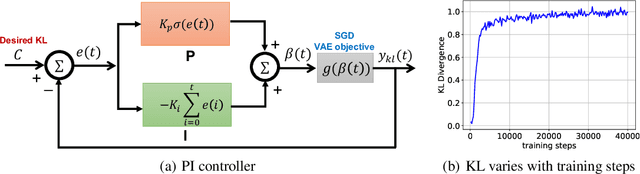
ControlVAE: Tuning, Analytical Properties, and Performance Analysis
Oct 31, 2020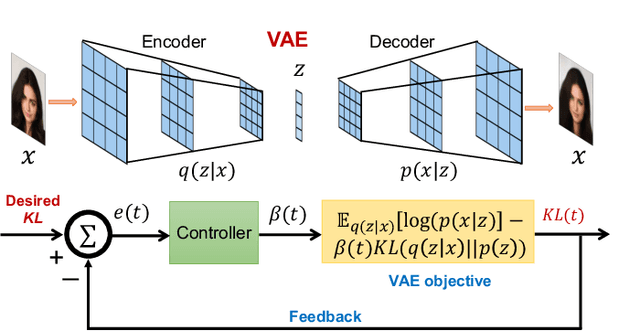
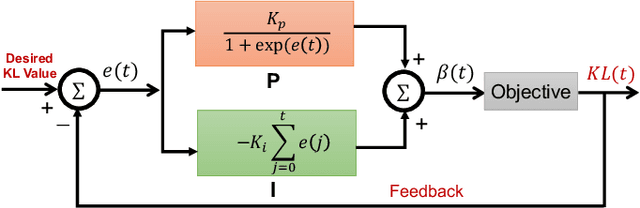
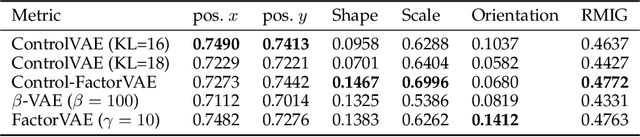
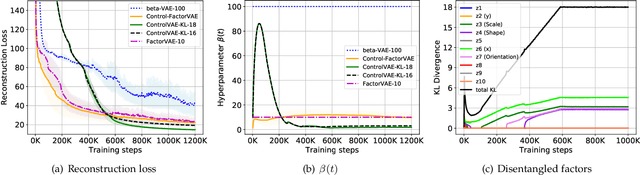
This paper reviews the novel concept of controllable variational autoencoder (ControlVAE), discusses its parameter tuning to meet application needs, derives its key analytic properties, and offers useful extensions and applications. ControlVAE is a new variational autoencoder (VAE) framework that combines the automatic control theory with the basic VAE to stabilize the KL-divergence of VAE models to a specified value. It leverages a non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to dynamically tune the weight of the KL-divergence term in the evidence lower bound (ELBO) using the output KL-divergence as feedback. This allows us to precisely control the KL-divergence to a desired value (set point), which is effective in avoiding posterior collapse and learning disentangled representations. In order to improve the ELBO over the regular VAE, we provide simplified theoretical analysis to inform setting the set point of KL-divergence for ControlVAE. We observe that compared to other methods that seek to balance the two terms in VAE's objective, ControlVAE leads to better learning dynamics. In particular, it can achieve a good trade-off between reconstruction quality and KL-divergence. We evaluate the proposed method on three tasks: image generation, language modeling and disentangled representation learning. The results show that ControlVAE can achieve much better reconstruction quality than the other methods for comparable disentanglement. On the language modeling task, ControlVAE can avoid posterior collapse (KL vanishing) and improve the diversity of generated text. Moreover, our method can change the optimization trajectory, improving the ELBO and the reconstruction quality for image generation.
A Spherical Hidden Markov Model for Semantics-Rich Human Mobility Modeling
Oct 05, 2020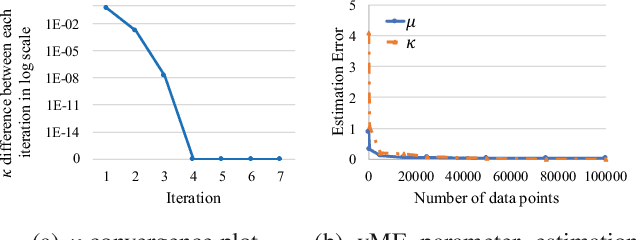
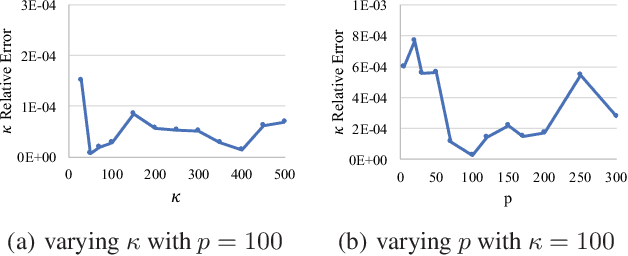
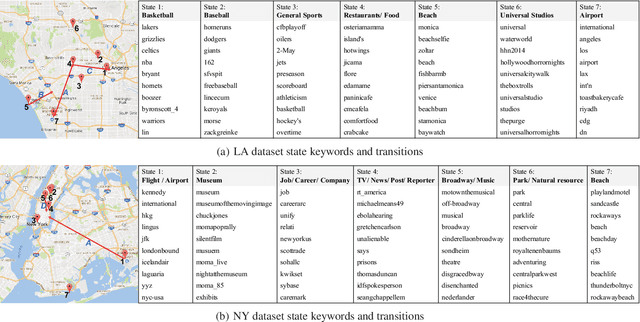
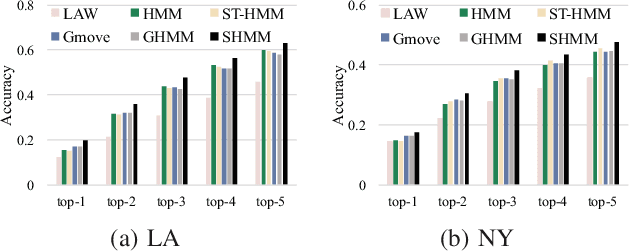
We study the problem of modeling human mobility from semantic trace data, wherein each GPS record in a trace is associated with a text message that describes the user's activity. Existing methods fall short in unveiling human movement regularities, because they either do not model the text data at all or suffer from text sparsity severely. We propose SHMM, a multi-modal spherical hidden Markov model for semantics-rich human mobility modeling. Under the hidden Markov assumption, SHMM models the generation process of a given trace by jointly considering the observed location, time, and text at each step of the trace. The distinguishing characteristic of SHMM is the text modeling part. We use fixed-size vector representations to encode the semantics of the text messages, and model the generation of the l2-normalized text embeddings on a unit sphere with the von Mises-Fisher (vMF) distribution. Compared with other alternatives like multi-variate Gaussian, our choice of the vMF distribution not only incurs much fewer parameters, but also better leverages the discriminative power of text embeddings in a directional metric space. The parameter inference for the vMF distribution is non-trivial since it involves functional inversion of ratios of Bessel functions. We theoretically prove that: 1) the classical Expectation-Maximization algorithm can work with vMF distributions; and 2) while closed-form solutions are hard to be obtained for the M-step, Newton's method is guaranteed to converge to the optimal solution with quadratic convergence rate. We have performed extensive experiments on both synthetic and real-life data. The results on synthetic data verify our theoretical analysis; while the results on real-life data demonstrate that SHMM learns meaningful semantics-rich mobility models, outperforms state-of-the-art mobility models for next location prediction, and incurs lower training cost.
DynamicVAE: Decoupling Reconstruction Error and Disentangled Representation Learning
Sep 30, 2020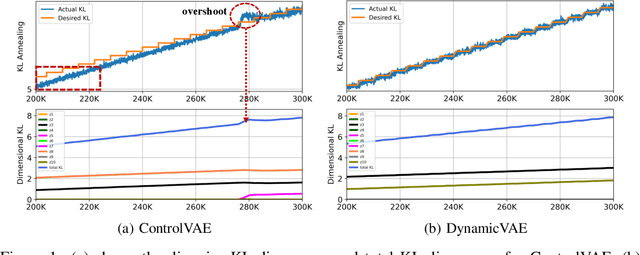

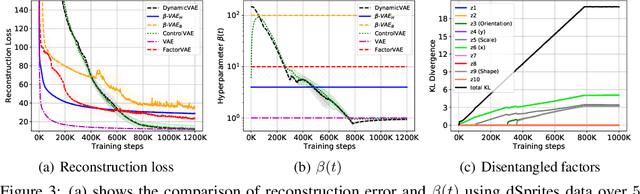
This paper challenges the common assumption that the weight $\beta$, in $\beta$-VAE, should be larger than $1$ in order to effectively disentangle latent factors. We demonstrate that $\beta$-VAE, with $\beta < 1$, can not only attain good disentanglement but also significantly improve reconstruction accuracy via dynamic control. The paper removes the inherent trade-off between reconstruction accuracy and disentanglement for $\beta$-VAE. Existing methods, such as $\beta$-VAE and FactorVAE, assign a large weight to the KL-divergence term in the objective function, leading to high reconstruction errors for the sake of better disentanglement. To mitigate this problem, a ControlVAE has recently been developed that dynamically tunes the KL-divergence weight in an attempt to control the trade-off to more a favorable point. However, ControlVAE fails to eliminate the conflict between the need for a large $\beta$ (for disentanglement) and the need for a small $\beta$. Instead, we propose DynamicVAE that maintains a different $\beta$ at different stages of training, thereby decoupling disentanglement and reconstruction accuracy. In order to evolve the weight, $\beta$, along a trajectory that enables such decoupling, DynamicVAE leverages a modified incremental PI (proportional-integral) controller, and employs a moving average as well as a hybrid annealing method to evolve the value of KL-divergence smoothly in a tightly controlled fashion. We theoretically prove the stability of the proposed approach. Evaluation results on three benchmark datasets demonstrate that DynamicVAE significantly improves the reconstruction accuracy while achieving disentanglement comparable to the best of existing methods. The results verify that our method can separate disentangled representation learning and reconstruction, removing the inherent tension between the two.
Hypergraph Learning with Line Expansion
May 24, 2020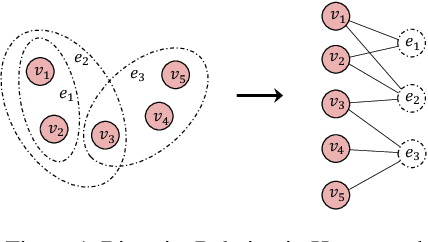

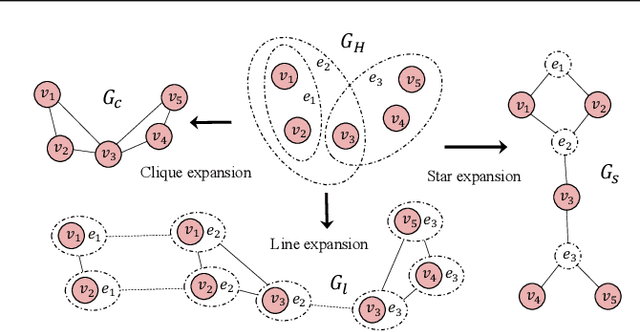

Previous hypergraph expansions are solely carried out on either vertex level or hyperedge level, thereby missing the symmetric nature of data co-occurrence, and resulting in information loss. To address the problem, this paper treats vertices and hyperedges equally and proposes a new hypergraph formulation named the \emph{line expansion (LE)} for hypergraphs learning. The new expansion bijectively induces a homogeneous structure from the hypergraph by treating vertex-hyperedge pairs as "line nodes". By reducing the hypergraph to a simple graph, the proposed \emph{line expansion} makes existing graph learning algorithms compatible with the higher-order structure and has been proven as a unifying framework for various hypergraph expansions. We evaluate the proposed line expansion on five hypergraph datasets, the results show that our method beats SOTA baselines by a significant margin.
Controllable Variational Autoencoder
Apr 13, 2020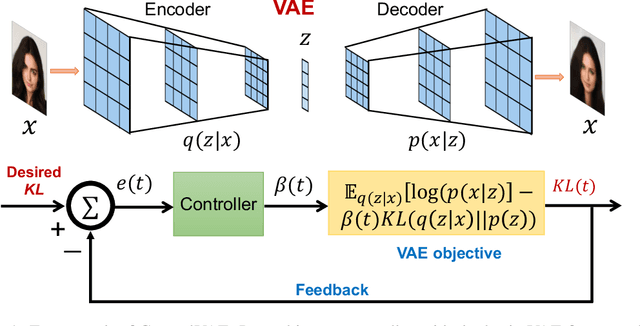

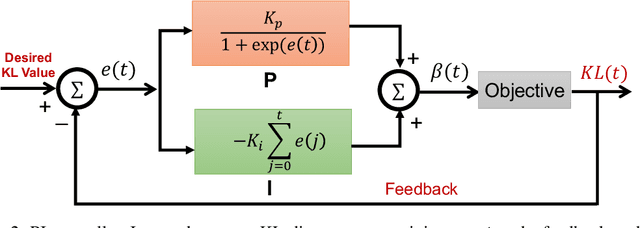

Variational Autoencoders (VAE) and their variants have been widely used in a variety of applications, such as dialog generation, image generation and disentangled representation learning. However, the existing VAE models have some limitations in different applications. For example, a VAE easily suffers from KL vanishing in language modeling and low reconstruction quality for disentangling. To address these issues, we propose a novel controllable variational autoencoder framework, ControlVAE, that combines a controller, inspired by automatic control theory, with the basic VAE to improve the performance of resulting generative models. Specifically, we design a new non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to automatically tune the hyperparameter (weight) added in the VAE objective using the output KL-divergence as feedback during model training. The framework is evaluated using three applications; namely, language modeling, disentangled representation learning, and image generation. The results show that ControlVAE can achieve better disentangling and reconstruction quality than the existing methods. For language modelling, it not only averts the KL-vanishing, but also improves the diversity of generated text. Finally, we also demonstrate that ControlVAE improves the reconstruction quality of generated images compared to the original VAE.
Revisiting "Over-smoothing" in Deep GCNs
Mar 30, 2020
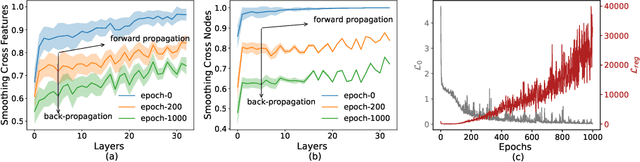

Oversmoothing has been assumed to be the major cause of performance drop in deep graph convolutional networks (GCNs). The evidence is usually derived from Simple Graph Convolution (SGC), a linear variant of GCNs. In this paper, we revisit graph node classification from an optimization perspective and argue that GCNs can actually learn anti-oversmoothing, whereas overfitting is the real obstacle in deep GCNs. This work interprets GCNs and SGCs as two-step optimization problems and provides the reason why deep SGC suffers from oversmoothing but deep GCNs do not. Our conclusion is compatible with the previous understanding of SGC, but we clarify why the same reasoning does not apply to GCNs. Based on our formulation, we provide more insights into the convolution operator and further propose a mean-subtraction trick to accelerate the training of deep GCNs. We verify our theory and propositions on three graph benchmarks. The experiments show that (i) in GCN, overfitting leads to the performance drop and oversmoothing does not exist even model goes to very deep (100 layers); (ii) mean-subtraction speeds up the model convergence as well as retains the same expressive power; (iii) the weight of neighbor averaging (1 is the common setting) does not significantly affect the model performance once it is above the threshold (> 0.5).