 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Brain Foundation Model Meets Cauchy-Schwarz Divergence: A New Framework for Cross-Subject Motor Imagery Decoding
Jul 28, 2025Decoding motor imagery (MI) electroencephalogram (EEG) signals, a key non-invasive brain-computer interface (BCI) paradigm for controlling external systems, has been significantly advanced by deep learning. However, MI-EEG decoding remains challenging due to substantial inter-subject variability and limited labeled target data, which necessitate costly calibration for new users. Many existing multi-source domain adaptation (MSDA) methods indiscriminately incorporate all available source domains, disregarding the large inter-subject differences in EEG signals, which leads to negative transfer and excessive computational costs. Moreover, while many approaches focus on feature distribution alignment, they often neglect the explicit dependence between features and decision-level outputs, limiting their ability to preserve discriminative structures. To address these gaps, we propose a novel MSDA framework that leverages a pretrained large Brain Foundation Model (BFM) for dynamic and informed source subject selection, ensuring only relevant sources contribute to adaptation. Furthermore, we employ Cauchy-Schwarz (CS) and Conditional CS (CCS) divergences to jointly perform feature-level and decision-level alignment, enhancing domain invariance while maintaining class discriminability. Extensive evaluations on two benchmark MI-EEG datasets demonstrate that our framework outperforms a broad range of state-of-the-art baselines. Additional experiments with a large source pool validate the scalability and efficiency of BFM-guided selection, which significantly reduces training time without sacrificing performance.
MvHo-IB: Multi-View Higher-Order Information Bottleneck for Brain Disorder Diagnosis
Jul 03, 2025Recent evidence suggests that modeling higher-order interactions (HOIs) in functional magnetic resonance imaging (fMRI) data can enhance the diagnostic accuracy of machine learning systems. However, effectively extracting and utilizing HOIs remains a significant challenge. In this work, we propose MvHo-IB, a novel multi-view learning framework that integrates both pairwise interactions and HOIs for diagnostic decision-making, while automatically compressing task-irrelevant redundant information. MvHo-IB introduces several key innovations: (1) a principled method that combines O-information from information theory with a matrix-based Renyi alpha-order entropy estimator to quantify and extract HOIs, (2) a purpose-built Brain3DCNN encoder to effectively utilize these interactions, and (3) a new multi-view learning information bottleneck objective to enhance representation learning. Experiments on three benchmark fMRI datasets demonstrate that MvHo-IB achieves state-of-the-art performance, significantly outperforming previous methods, including recent hypergraph-based techniques. The implementation of MvHo-IB is available at https://github.com/zky04/MvHo-IB.
InfoDPCCA: Information-Theoretic Dynamic Probabilistic Canonical Correlation Analysis
Jun 10, 2025Extracting meaningful latent representations from high-dimensional sequential data is a crucial challenge in machine learning, with applications spanning natural science and engineering. We introduce InfoDPCCA, a dynamic probabilistic Canonical Correlation Analysis (CCA) framework designed to model two interdependent sequences of observations. InfoDPCCA leverages a novel information-theoretic objective to extract a shared latent representation that captures the mutual structure between the data streams and balances representation compression and predictive sufficiency while also learning separate latent components that encode information specific to each sequence. Unlike prior dynamic CCA models, such as DPCCA, our approach explicitly enforces the shared latent space to encode only the mutual information between the sequences, improving interpretability and robustness. We further introduce a two-step training scheme to bridge the gap between information-theoretic representation learning and generative modeling, along with a residual connection mechanism to enhance training stability. Through experiments on synthetic and medical fMRI data, we demonstrate that InfoDPCCA excels as a tool for representation learning. Code of InfoDPCCA is available at https://github.com/marcusstang/InfoDPCCA.
Aggregation of Dependent Expert Distributions in Multimodal Variational Autoencoders
May 02, 2025Multimodal learning with variational autoencoders (VAEs) requires estimating joint distributions to evaluate the evidence lower bound (ELBO). Current methods, the product and mixture of experts, aggregate single-modality distributions assuming independence for simplicity, which is an overoptimistic assumption. This research introduces a novel methodology for aggregating single-modality distributions by exploiting the principle of consensus of dependent experts (CoDE), which circumvents the aforementioned assumption. Utilizing the CoDE method, we propose a novel ELBO that approximates the joint likelihood of the multimodal data by learning the contribution of each subset of modalities. The resulting CoDE-VAE model demonstrates better performance in terms of balancing the trade-off between generative coherence and generative quality, as well as generating more precise log-likelihood estimations. CoDE-VAE further minimizes the generative quality gap as the number of modalities increases. In certain cases, it reaches a generative quality similar to that of unimodal VAEs, which is a desirable property that is lacking in most current methods. Finally, the classification accuracy achieved by CoDE-VAE is comparable to that of state-of-the-art multimodal VAE models.
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Deep Dynamic Probabilistic Canonical Correlation Analysis
Feb 07, 2025This paper presents Deep Dynamic Probabilistic Canonical Correlation Analysis (D2PCCA), a model that integrates deep learning with probabilistic modeling to analyze nonlinear dynamical systems. Building on the probabilistic extensions of Canonical Correlation Analysis (CCA), D2PCCA captures nonlinear latent dynamics and supports enhancements such as KL annealing for improved convergence and normalizing flows for a more flexible posterior approximation. D2PCCA naturally extends to multiple observed variables, making it a versatile tool for encoding prior knowledge about sequential datasets and providing a probabilistic understanding of the system's dynamics. Experimental validation on real financial datasets demonstrates the effectiveness of D2PCCA and its extensions in capturing latent dynamics.
Towards the Generalization of Multi-view Learning: An Information-theoretical Analysis
Jan 28, 2025Multiview learning has drawn widespread attention for its efficacy in leveraging cross-view consensus and complementarity information to achieve a comprehensive representation of data. While multi-view learning has undergone vigorous development and achieved remarkable success, the theoretical understanding of its generalization behavior remains elusive. This paper aims to bridge this gap by developing information-theoretic generalization bounds for multi-view learning, with a particular focus on multi-view reconstruction and classification tasks. Our bounds underscore the importance of capturing both consensus and complementary information from multiple different views to achieve maximally disentangled representations. These results also indicate that applying the multi-view information bottleneck regularizer is beneficial for satisfactory generalization performance. Additionally, we derive novel data-dependent bounds under both leave-one-out and supersample settings, yielding computational tractable and tighter bounds. In the interpolating regime, we further establish the fast-rate bound for multi-view learning, exhibiting a faster convergence rate compared to conventional square-root bounds. Numerical results indicate a strong correlation between the true generalization gap and the derived bounds across various learning scenarios.
ELEMENT: Episodic and Lifelong Exploration via Maximum Entropy
Dec 05, 2024This paper proposes \emph{Episodic and Lifelong Exploration via Maximum ENTropy} (ELEMENT), a novel, multiscale, intrinsically motivated reinforcement learning (RL) framework that is able to explore environments without using any extrinsic reward and transfer effectively the learned skills to downstream tasks. We advance the state of the art in three ways. First, we propose a multiscale entropy optimization to take care of the fact that previous maximum state entropy, for lifelong exploration with millions of state observations, suffers from vanishing rewards and becomes very expensive computationally across iterations. Therefore, we add an episodic maximum entropy over each episode to speedup the search further. Second, we propose a novel intrinsic reward for episodic entropy maximization named \emph{average episodic state entropy} which provides the optimal solution for a theoretical upper bound of the episodic state entropy objective. Third, to speed the lifelong entropy maximization, we propose a $k$ nearest neighbors ($k$NN) graph to organize the estimation of the entropy and updating processes that reduces the computation substantially. Our ELEMENT significantly outperforms state-of-the-art intrinsic rewards in both episodic and lifelong setups. Moreover, it can be exploited in task-agnostic pre-training, collecting data for offline reinforcement learning, etc.
Discovering Common Information in Multi-view Data
Jun 21, 2024



We introduce an innovative and mathematically rigorous definition for computing common information from multi-view data, drawing inspiration from G\'acs-K\"orner common information in information theory. Leveraging this definition, we develop a novel supervised multi-view learning framework to capture both common and unique information. By explicitly minimizing a total correlation term, the extracted common information and the unique information from each view are forced to be independent of each other, which, in turn, theoretically guarantees the effectiveness of our framework. To estimate information-theoretic quantities, our framework employs matrix-based R{\'e}nyi's $\alpha$-order entropy functional, which forgoes the need for variational approximation and distributional estimation in high-dimensional space. Theoretical proof is provided that our framework can faithfully discover both common and unique information from multi-view data. Experiments on synthetic and seven benchmark real-world datasets demonstrate the superior performance of our proposed framework over state-of-the-art approaches.
BAN: Detecting Backdoors Activated by Adversarial Neuron Noise
May 30, 2024
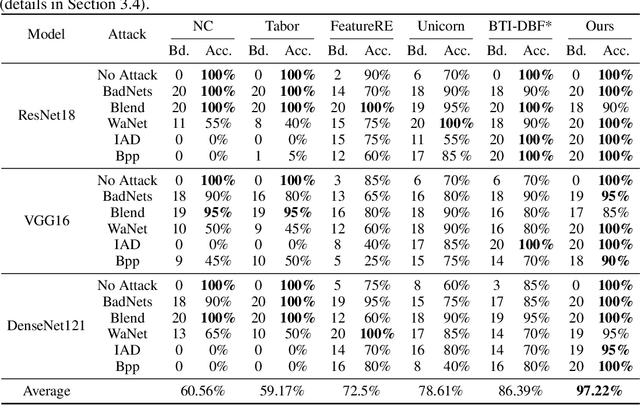
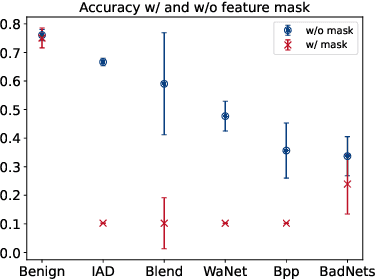
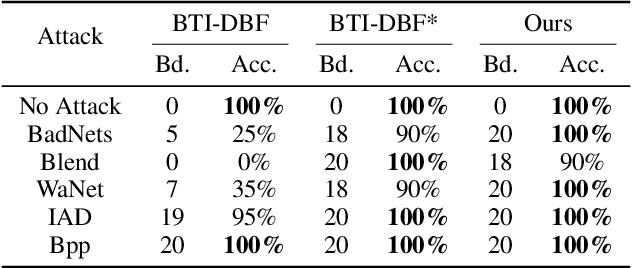
Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community. Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$\times$ (on CIFAR-10) and 5.11$\times$ (on ImageNet200) more efficient with 9.99% higher detect success rate than the state-of-the-art defense BTI-DBF. Our code and trained models are publicly available.\url{https://anonymous.4open.science/r/ban-4B32}