 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsing-based View-aware Embedding Network for Vehicle Re-Identification
Apr 10, 2020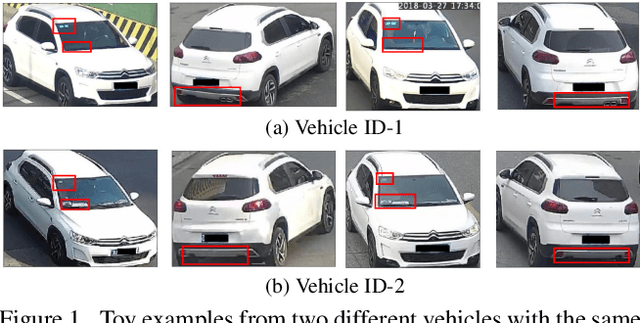
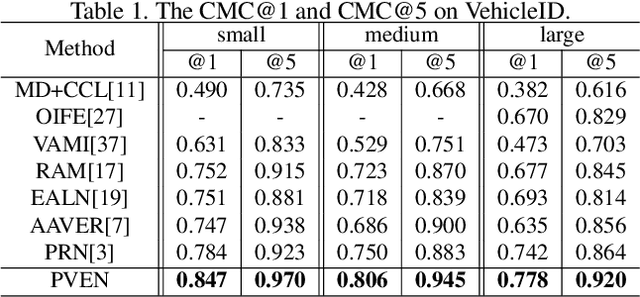
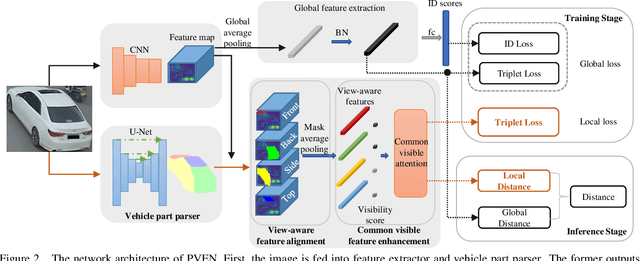
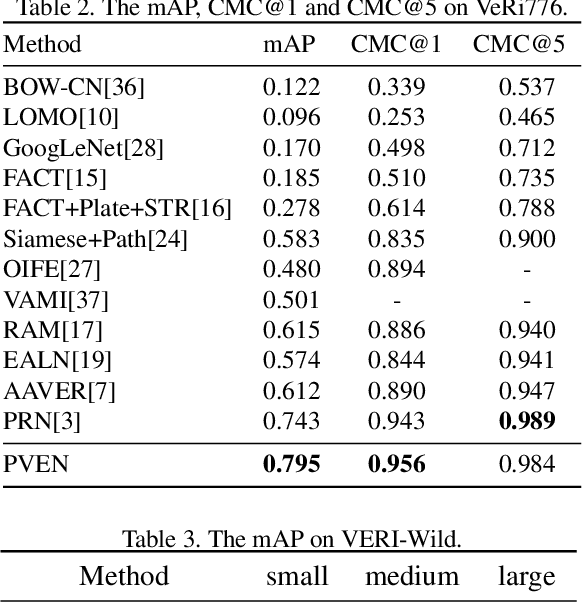
Vehicle Re-Identification is to find images of the same vehicle from various views in the cross-camera scenario. The main challenges of this task are the large intra-instance distance caused by different views and the subtle inter-instance discrepancy caused by similar vehicles. In this paper, we propose a parsing-based view-aware embedding network (PVEN) to achieve the view-aware feature alignment and enhancement for vehicle ReID. First, we introduce a parsing network to parse a vehicle into four different views, and then align the features by mask average pooling. Such alignment provides a fine-grained representation of the vehicle. Second, in order to enhance the view-aware features, we design a common-visible attention to focus on the common visible views, which not only shortens the distance among intra-instances, but also enlarges the discrepancy of inter-instances. The PVEN helps capture the stable discriminative information of vehicle under different views. The experiments conducted on three datasets show that our model outperforms state-of-the-art methods by a large margin.
State-Relabeling Adversarial Active Learning
Apr 10, 2020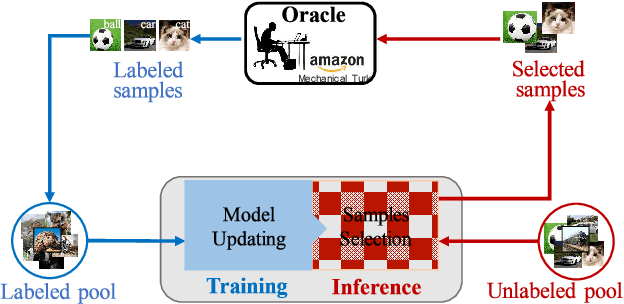
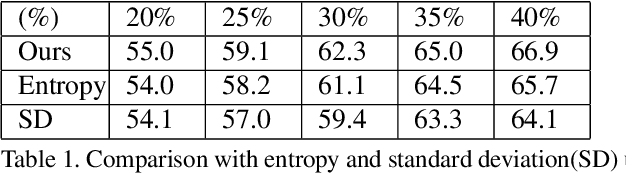
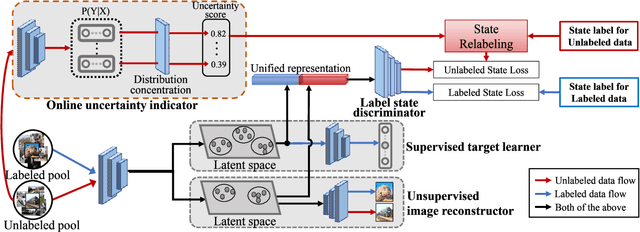
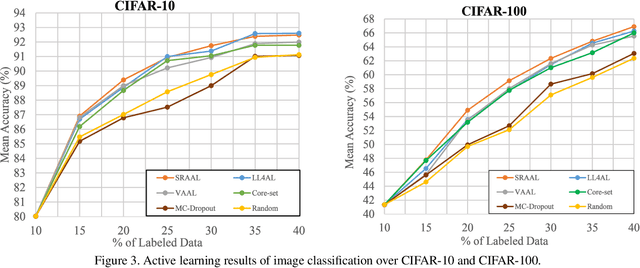
Active learning is to design label-efficient algorithms by sampling the most representative samples to be labeled by an oracle. In this paper, we propose a state relabeling adversarial active learning model (SRAAL), that leverages both the annotation and the labeled/unlabeled state information for deriving the most informative unlabeled samples. The SRAAL consists of a representation generator and a state discriminator. The generator uses the complementary annotation information with traditional reconstruction information to generate the unified representation of samples, which embeds the semantic into the whole data representation. Then, we design an online uncertainty indicator in the discriminator, which endues unlabeled samples with different importance. As a result, we can select the most informative samples based on the discriminator's predicted state. We also design an algorithm to initialize the labeled pool, which makes subsequent sampling more efficient. The experiments conducted on various datasets show that our model outperforms the previous state-of-art active learning methods and our initially sampling algorithm achieves better performance.
Gradually Vanishing Bridge for Adversarial Domain Adaptation
Mar 30, 2020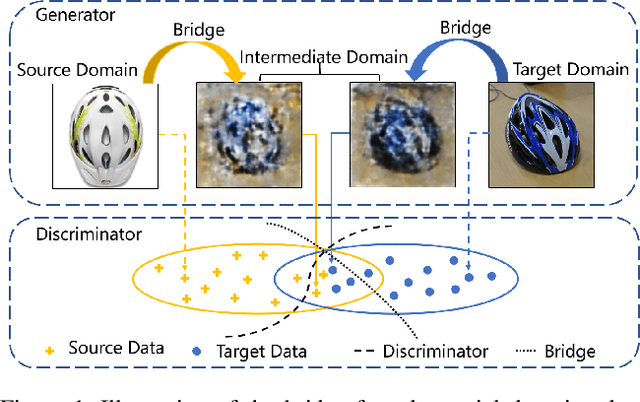
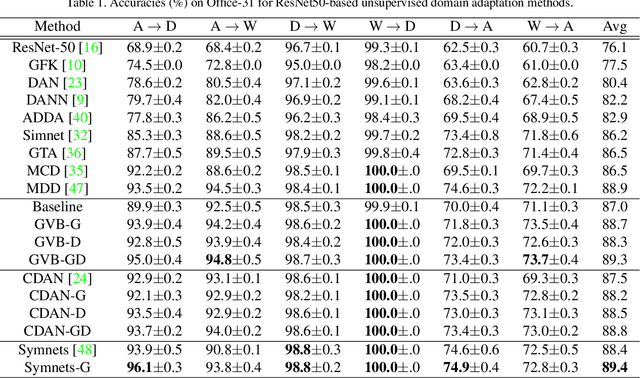
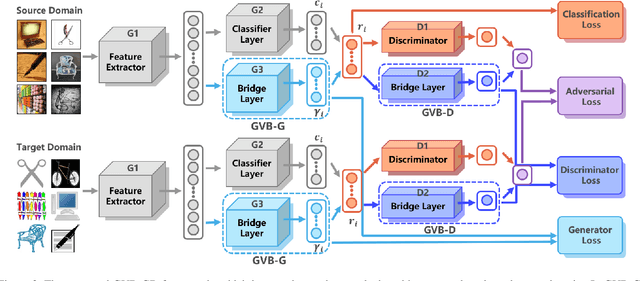
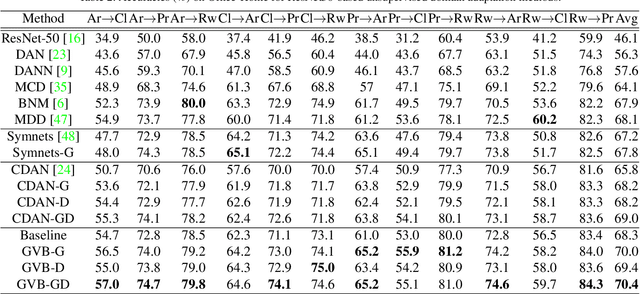
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods. The code is available at https://github.com/cuishuhao/GVB.
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
Mar 27, 2020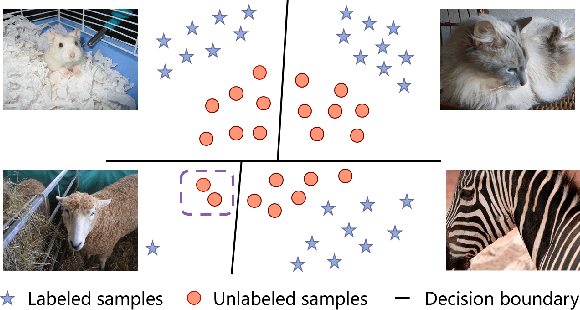
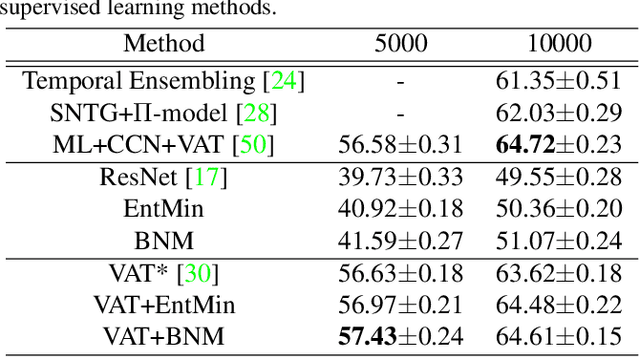
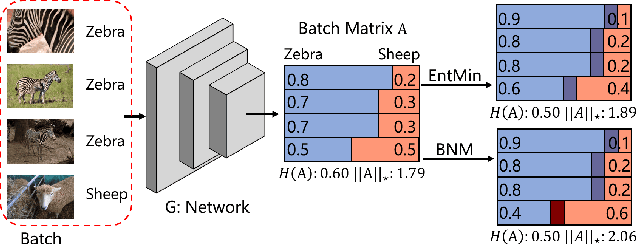
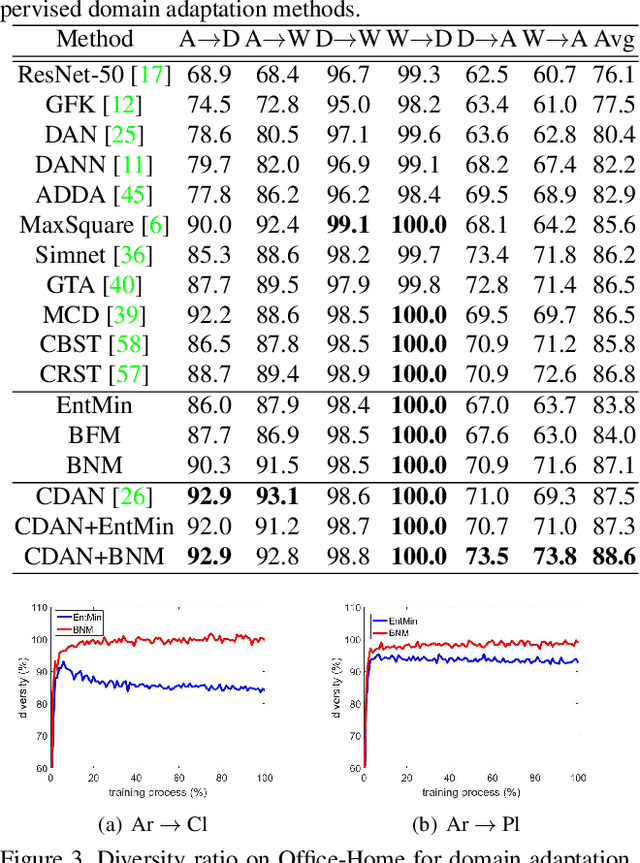
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods. The code is available at https://github.com/cuishuhao/BNM.
F3Net: Fusion, Feedback and Focus for Salient Object Detection
Nov 26, 2019
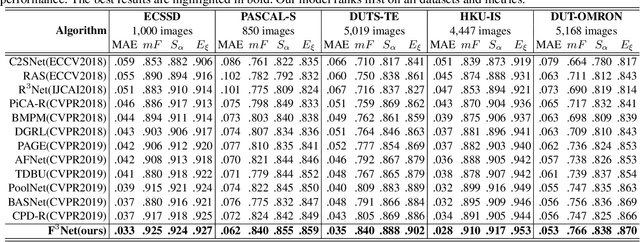
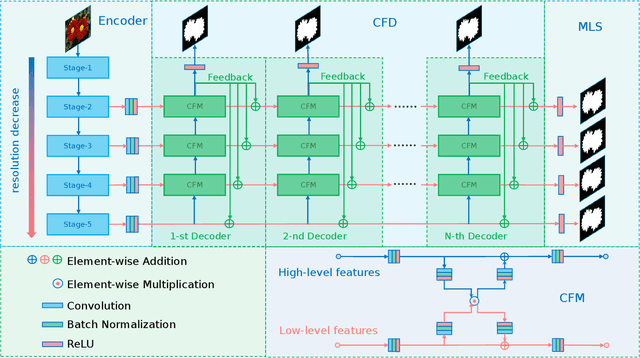
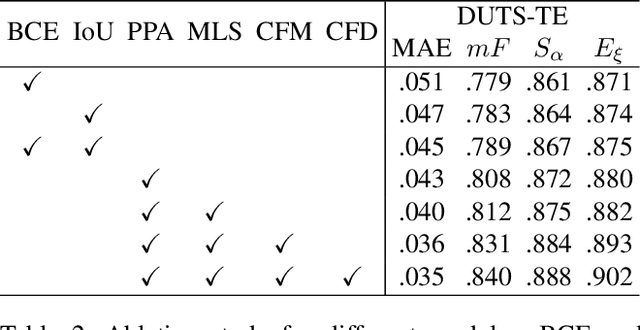
Most of existing salient object detection models have achieved great progress by aggregating multi-level features extracted from convolutional neural networks. However, because of the different receptive fields of different convolutional layers, there exists big differences between features generated by these layers. Common feature fusion strategies (addition or concatenation) ignore these differences and may cause suboptimal solutions. In this paper, we propose the F3Net to solve above problem, which mainly consists of cross feature module (CFM) and cascaded feedback decoder (CFD) trained by minimizing a new pixel position aware loss (PPA). Specifically, CFM aims to selectively aggregate multi-level features. Different from addition and concatenation, CFM adaptively selects complementary components from input features before fusion, which can effectively avoid introducing too much redundant information that may destroy the original features. Besides, CFD adopts a multi-stage feedback mechanism, where features closed to supervision will be introduced to the output of previous layers to supplement them and eliminate the differences between features. These refined features will go through multiple similar iterations before generating the final saliency maps. Furthermore, different from binary cross entropy, the proposed PPA loss doesn't treat pixels equally, which can synthesize the local structure information of a pixel to guide the network to focus more on local details. Hard pixels from boundaries or error-prone parts will be given more attention to emphasize their importance. F3Net is able to segment salient object regions accurately and provide clear local details. Comprehensive experiments on five benchmark datasets demonstrate that F3Net outperforms state-of-the-art approaches on six evaluation metrics.
Knowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding
Sep 05, 2019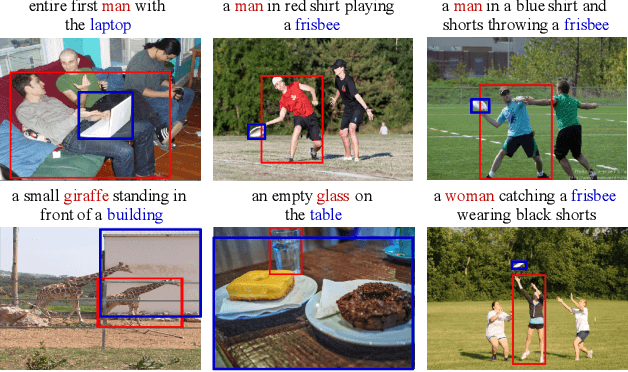
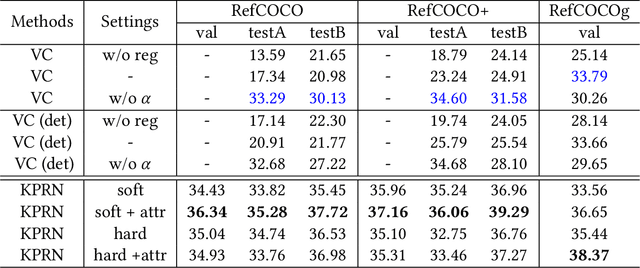
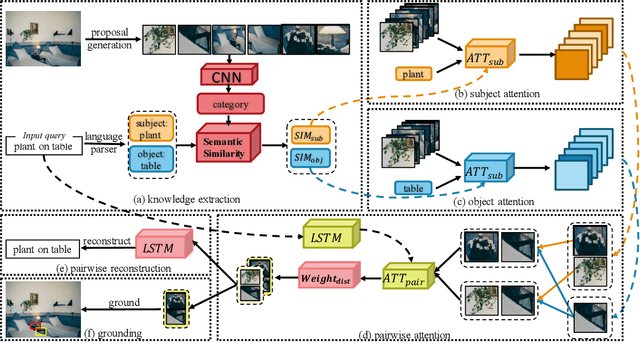
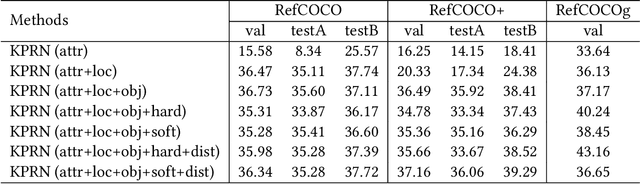
Weakly supervised referring expression grounding (REG) aims at localizing the referential entity in an image according to linguistic query, where the mapping between the image region (proposal) and the query is unknown in the training stage. In referring expressions, people usually describe a target entity in terms of its relationship with other contextual entities as well as visual attributes. However, previous weakly supervised REG methods rarely pay attention to the relationship between the entities. In this paper, we propose a knowledge-guided pairwise reconstruction network (KPRN), which models the relationship between the target entity (subject) and contextual entity (object) as well as grounds these two entities. Specifically, we first design a knowledge extraction module to guide the proposal selection of subject and object. The prior knowledge is obtained in a specific form of semantic similarities between each proposal and the subject/object. Second, guided by such knowledge, we design the subject and object attention module to construct the subject-object proposal pairs. The subject attention excludes the unrelated proposals from the candidate proposals. The object attention selects the most suitable proposal as the contextual proposal. Third, we introduce a pairwise attention and an adaptive weighting scheme to learn the correspondence between these proposal pairs and the query. Finally, a pairwise reconstruction module is used to measure the grounding for weakly supervised learning. Extensive experiments on four large-scale datasets show our method outperforms existing state-of-the-art methods by a large margin.
Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Aug 28, 2019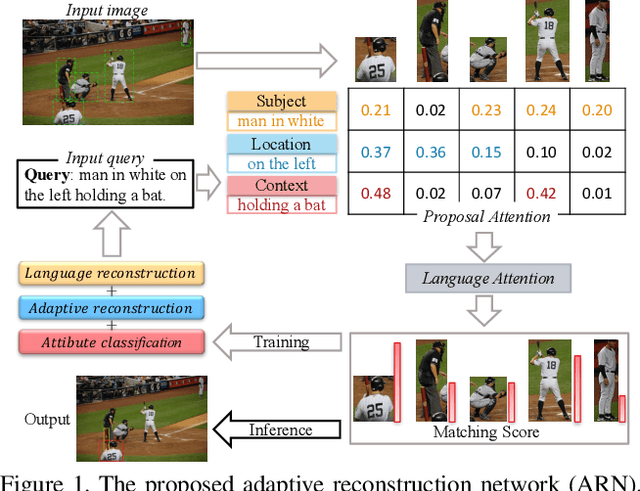
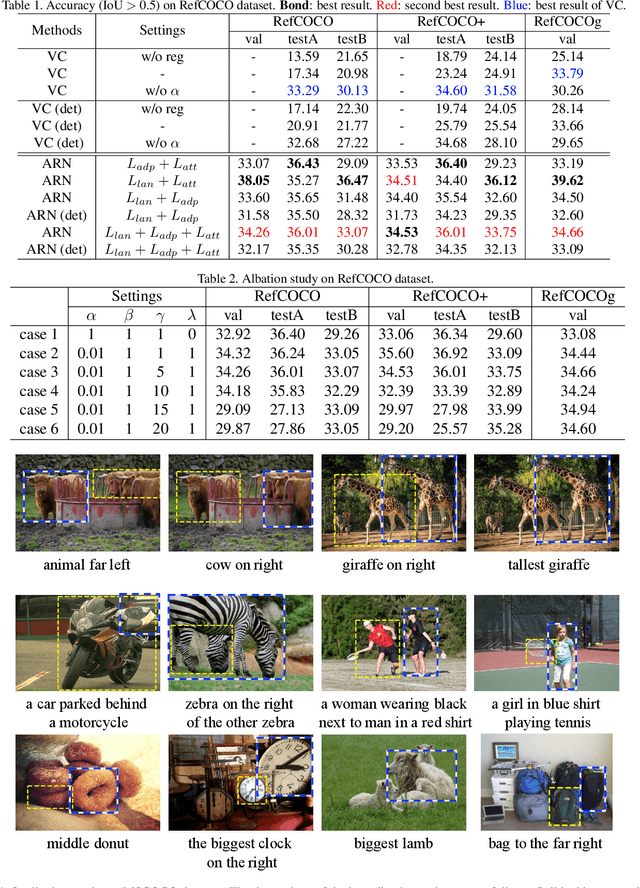
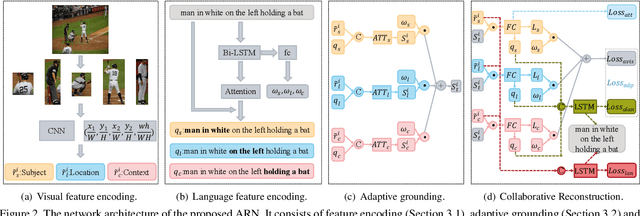
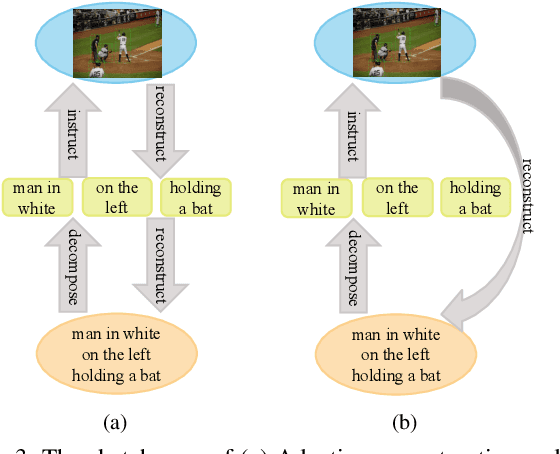
Weakly supervised referring expression grounding aims at localizing the referential object in an image according to the linguistic query, where the mapping between the referential object and query is unknown in the training stage. To address this problem, we propose a novel end-to-end adaptive reconstruction network (ARN). It builds the correspondence between image region proposal and query in an adaptive manner: adaptive grounding and collaborative reconstruction. Specifically, we first extract the subject, location and context features to represent the proposals and the query respectively. Then, we design the adaptive grounding module to compute the matching score between each proposal and query by a hierarchical attention model. Finally, based on attention score and proposal features, we reconstruct the input query with a collaborative loss of language reconstruction loss, adaptive reconstruction loss, and attribute classification loss. This adaptive mechanism helps our model to alleviate the variance of different referring expressions. Experiments on four large-scale datasets show ARN outperforms existing state-of-the-art methods by a large margin. Qualitative results demonstrate that the proposed ARN can better handle the situation where multiple objects of a particular category situated together.
Harmonized Multimodal Learning with Gaussian Process Latent Variable Models
Aug 14, 2019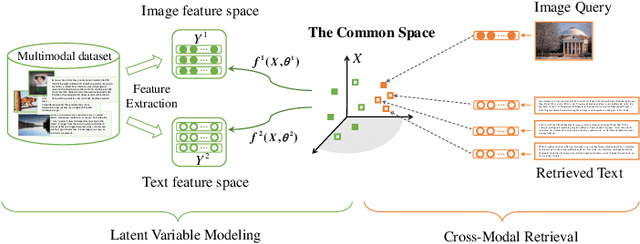
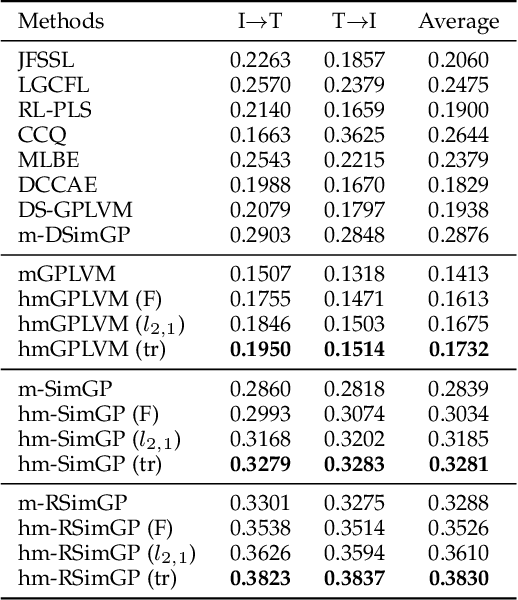
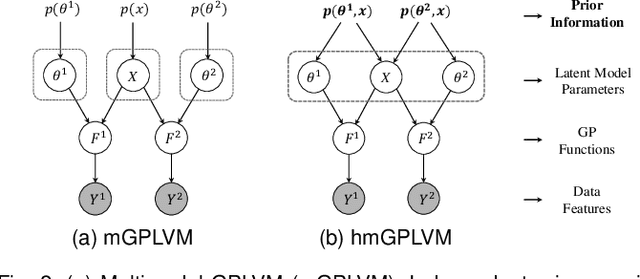
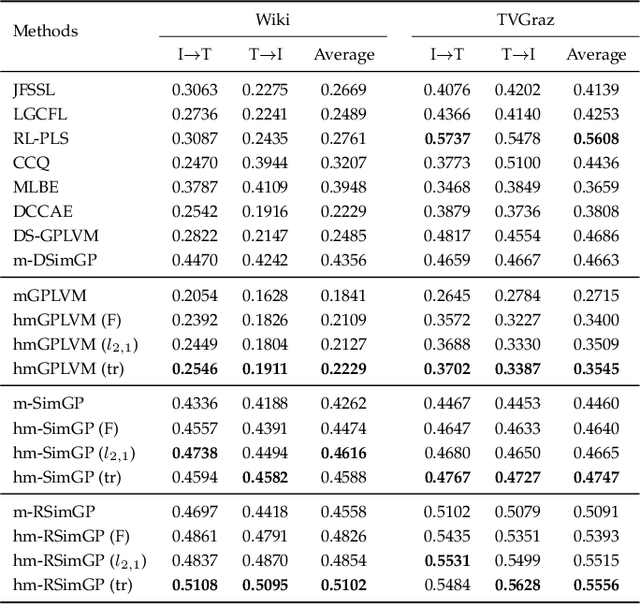
Multimodal learning aims to discover the relationship between multiple modalities. It has become an important research topic due to extensive multimodal applications such as cross-modal retrieval. This paper attempts to address the modality heterogeneity problem based on Gaussian process latent variable models (GPLVMs) to represent multimodal data in a common space. Previous multimodal GPLVM extensions generally adopt individual learning schemes on latent representations and kernel hyperparameters, which ignore their intrinsic relationship. To exploit strong complementarity among different modalities and GPLVM components, we develop a novel learning scheme called Harmonization, where latent model parameters are jointly learned from each other. Beyond the correlation fitting or intra-modal structure preservation paradigms widely used in existing studies, the harmonization is derived in a model-driven manner to encourage the agreement between modality-specific GP kernels and the similarity of latent representations. We present a range of multimodal learning models by incorporating the harmonization mechanism into several representative GPLVM-based approaches. Experimental results on four benchmark datasets show that the proposed models outperform the strong baselines for cross-modal retrieval tasks, and that the harmonized multimodal learning method is superior in discovering semantically consistent latent representation.
Unsupervised Open Domain Recognition by Semantic Discrepancy Minimization
Apr 18, 2019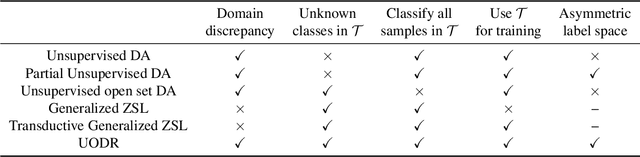
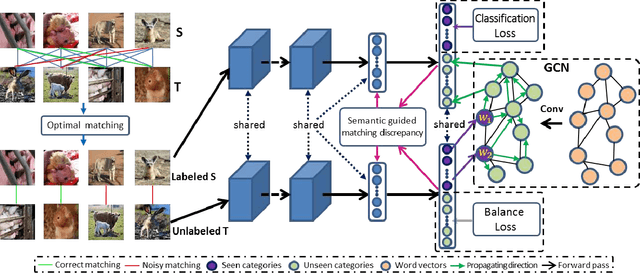

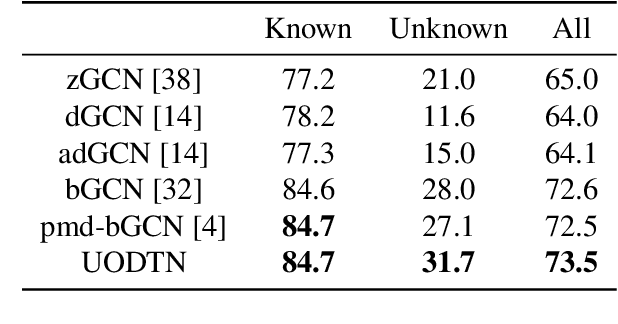
We address the unsupervised open domain recognition (UODR) problem, where categories in labeled source domain S is only a subset of those in unlabeled target domain T. The task is to correctly classify all samples in T including known and unknown categories. UODR is challenging due to the domain discrepancy, which becomes even harder to bridge when a large number of unknown categories exist in T. Moreover, the classification rules propagated by graph CNN (GCN) may be distracted by unknown categories and lack generalization capability. To measure the domain discrepancy for asymmetric label space between S and T, we propose Semantic-Guided Matching Discrepancy (SGMD), which first employs instance matching between S and T, and then the discrepancy is measured by a weighted feature distance between matched instances. We further design a limited balance constraint to achieve a more balanced classification output on known and unknown categories. We develop Unsupervised Open Domain Transfer Network (UODTN), which learns both the backbone classification network and GCN jointly by reducing the SGMD, enforcing the limited balance constraint and minimizing the classification loss on S. UODTN better preserves the semantic structure and enforces the consistency between the learned domain invariant visual features and the semantic embeddings. Experimental results show superiority of our method on recognizing images of both known and unknown categories.
Less Is More: Picking Informative Frames for Video Captioning
Mar 05, 2018
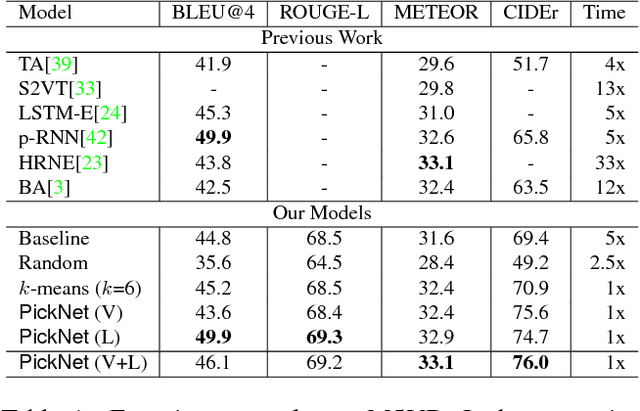
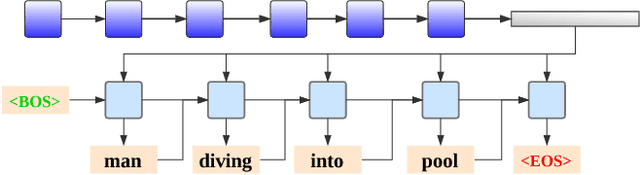
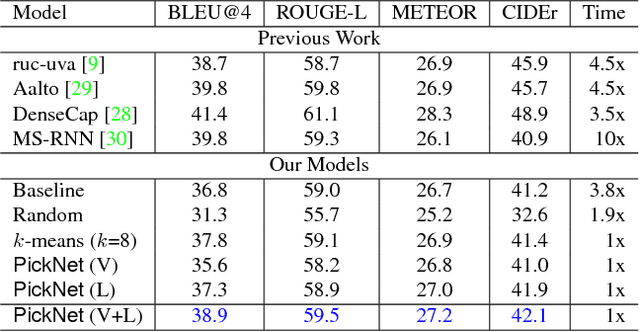
In video captioning task, the best practice has been achieved by attention-based models which associate salient visual components with sentences in the video. However, existing study follows a common procedure which includes a frame-level appearance modeling and motion modeling on equal interval frame sampling, which may bring about redundant visual information, sensitivity to content noise and unnecessary computation cost. We propose a plug-and-play PickNet to perform informative frame picking in video captioning. Based on a standard Encoder-Decoder framework, we develop a reinforcement-learning-based procedure to train the network sequentially, where the reward of each frame picking action is designed by maximizing visual diversity and minimizing textual discrepancy. If the candidate is rewarded, it will be selected and the corresponding latent representation of Encoder-Decoder will be updated for future trials. This procedure goes on until the end of the video sequence. Consequently, a compact frame subset can be selected to represent the visual information and perform video captioning without performance degradation. Experiment results shows that our model can use 6-8 frames to achieve competitive performance across popular benchmarks.