 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025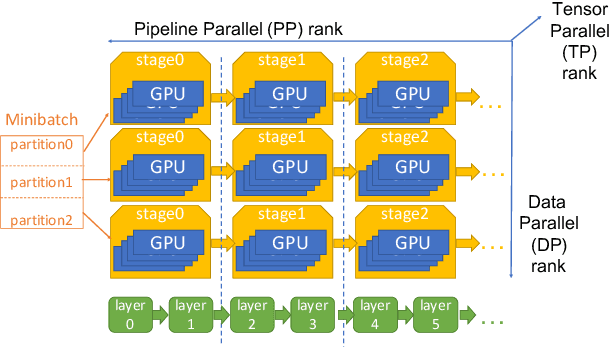

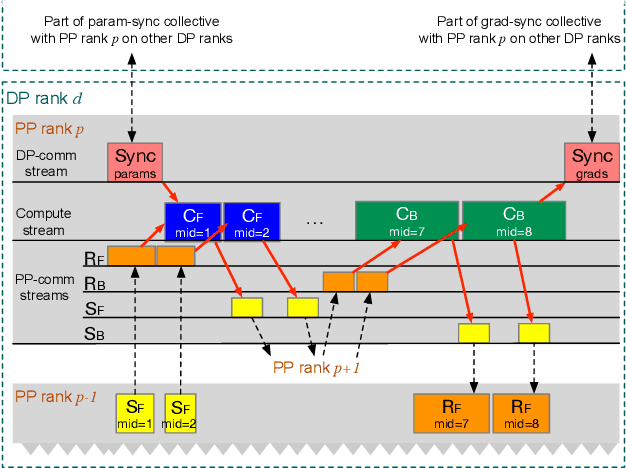
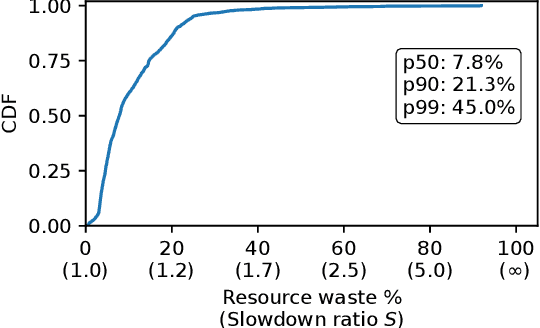
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
Advancing TDFN: Precise Fixation Point Generation Using Reconstruction Differences
Jan 26, 2025Wang and Wang (2025) proposed the Task-Driven Fixation Network (TDFN) based on the fixation mechanism, which leverages low-resolution information along with high-resolution details near fixation points to accomplish specific visual tasks. The model employs reinforcement learning to generate fixation points. However, training reinforcement learning models is challenging, particularly when aiming to generate pixel-level accurate fixation points on high-resolution images. This paper introduces an improved fixation point generation method by leveraging the difference between the reconstructed image and the input image to train the fixation point generator. This approach directs fixation points to areas with significant differences between the reconstructed and input images. Experimental results demonstrate that this method achieves highly accurate fixation points, significantly enhances the network's classification accuracy, and reduces the average number of required fixations to achieve a predefined accuracy level.
Task-Driven Fixation Network: An Efficient Architecture with Fixation Selection
Jan 02, 2025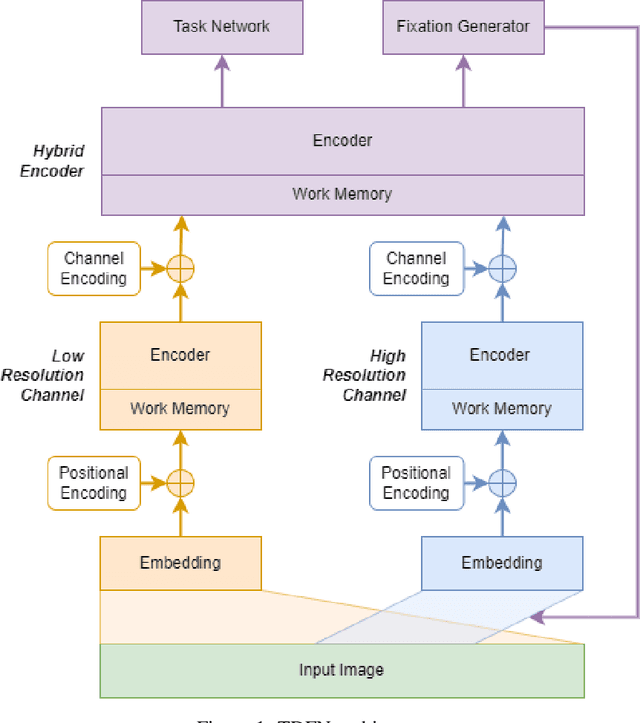
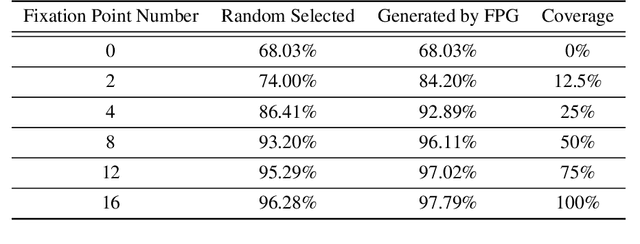
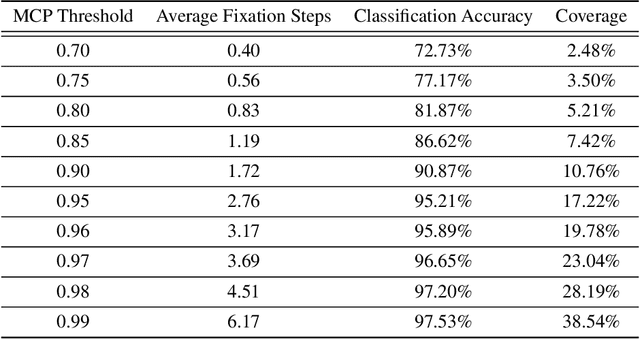

This paper presents a novel neural network architecture featuring automatic fixation point selection, designed to efficiently address complex tasks with reduced network size and computational overhead. The proposed model consists of: a low-resolution channel that captures low-resolution global features from input images; a high-resolution channel that sequentially extracts localized high-resolution features; and a hybrid encoding module that integrates the features from both channels. A defining characteristic of the hybrid encoding module is the inclusion of a fixation point generator, which dynamically produces fixation points, enabling the high-resolution channel to focus on regions of interest. The fixation points are generated in a task-driven manner, enabling the automatic selection of regions of interest. This approach avoids exhaustive high-resolution analysis of the entire image, maintaining task performance and computational efficiency.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024



Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.