 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSC: Topology-Conditioned Stackelberg Coordination for Multi-Agent Reinforcement Learning in Interactive Driving
Feb 27, 2026Safe and efficient autonomous driving in dense traffic is fundamentally a decentralized multi-agent coordination problem, where interactions at conflict points such as merging and weaving must be resolved reliably under partial observability. With only local and incomplete cues, interaction patterns can change rapidly, often causing unstable behaviors such as oscillatory yielding or unsafe commitments. Existing multi-agent reinforcement learning (MARL) approaches either adopt synchronous decision-making, which exacerbate non-stationarity, or depend on centralized sequencing mechanisms that scale poorly as traffic density increases. To address these limitations, we propose Topology-conditioned Stackelberg Coordination (TSC), a learning framework for decentralized interactive driving under communication-free execution, which extracts a time-varying directed priority graph from braid-inspired weaving relations between trajectories, thereby defining local leader-follower dependencies without constructing a global order of play. Conditioned on this graph, TSC endogenously factorizes dense interactions into graph-local Stackelberg subgames and, under centralized training and decentralized execution (CTDE), learns a sequential coordination policy that anticipates leaders via action prediction and trains followers through action-conditioned value learning to approximate local best responses, improving training stability and safety in dense traffic. Experiments across four dense traffic scenarios show that TSC achieves superior performance over representative MARL baselines across key metrics, most notably reducing collisions while maintaining competitive traffic efficiency and control smoothness.
Advancing TDFN: Precise Fixation Point Generation Using Reconstruction Differences
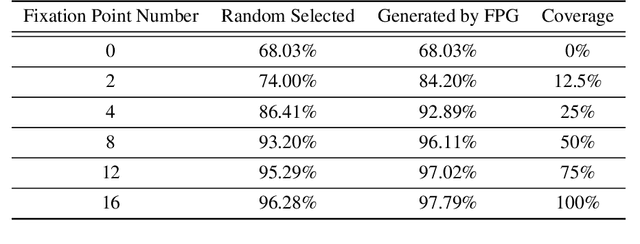
Jan 26, 2025Wang and Wang (2025) proposed the Task-Driven Fixation Network (TDFN) based on the fixation mechanism, which leverages low-resolution information along with high-resolution details near fixation points to accomplish specific visual tasks. The model employs reinforcement learning to generate fixation points. However, training reinforcement learning models is challenging, particularly when aiming to generate pixel-level accurate fixation points on high-resolution images. This paper introduces an improved fixation point generation method by leveraging the difference between the reconstructed image and the input image to train the fixation point generator. This approach directs fixation points to areas with significant differences between the reconstructed and input images. Experimental results demonstrate that this method achieves highly accurate fixation points, significantly enhances the network's classification accuracy, and reduces the average number of required fixations to achieve a predefined accuracy level.
Task-Driven Fixation Network: An Efficient Architecture with Fixation Selection
Jan 02, 2025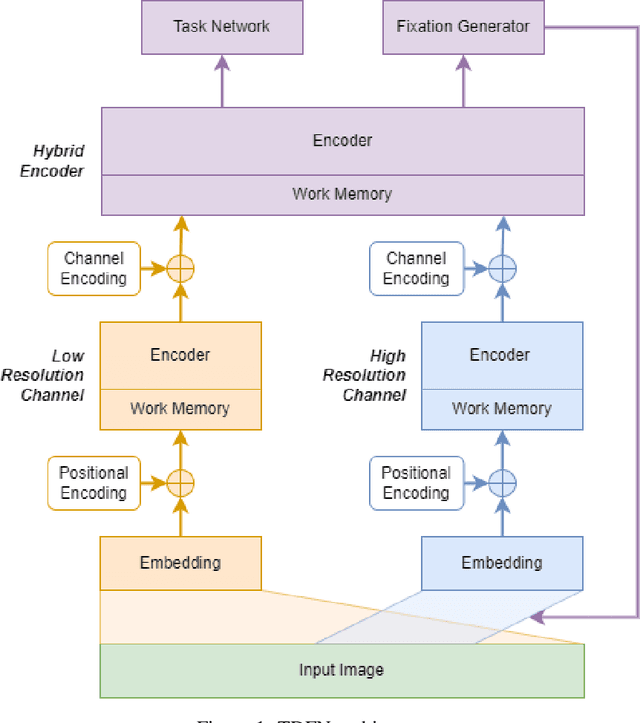
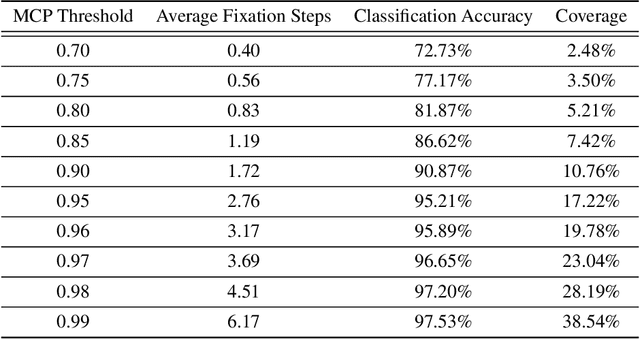

This paper presents a novel neural network architecture featuring automatic fixation point selection, designed to efficiently address complex tasks with reduced network size and computational overhead. The proposed model consists of: a low-resolution channel that captures low-resolution global features from input images; a high-resolution channel that sequentially extracts localized high-resolution features; and a hybrid encoding module that integrates the features from both channels. A defining characteristic of the hybrid encoding module is the inclusion of a fixation point generator, which dynamically produces fixation points, enabling the high-resolution channel to focus on regions of interest. The fixation points are generated in a task-driven manner, enabling the automatic selection of regions of interest. This approach avoids exhaustive high-resolution analysis of the entire image, maintaining task performance and computational efficiency.