 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-MuMER: Unified Multi-Task Fine-Tuning of Vision-Language Model for Handwritten Mathematical Expression Recognition
May 29, 2025Handwritten Mathematical Expression Recognition (HMER) remains a persistent challenge in Optical Character Recognition (OCR) due to the inherent freedom of symbol layout and variability in handwriting styles. Prior methods have faced performance bottlenecks, proposing isolated architectural modifications that are difficult to integrate coherently into a unified framework. Meanwhile, recent advances in pretrained vision-language models (VLMs) have demonstrated strong cross-task generalization, offering a promising foundation for developing unified solutions. In this paper, we introduce Uni-MuMER, which fully fine-tunes a VLM for the HMER task without modifying its architecture, effectively injecting domain-specific knowledge into a generalist framework. Our method integrates three data-driven tasks: Tree-Aware Chain-of-Thought (Tree-CoT) for structured spatial reasoning, Error-Driven Learning (EDL) for reducing confusion among visually similar characters, and Symbol Counting (SC) for improving recognition consistency in long expressions. Experiments on the CROHME and HME100K datasets show that Uni-MuMER achieves new state-of-the-art performance, surpassing the best lightweight specialized model SSAN by 16.31% and the top-performing VLM Gemini2.5-flash by 24.42% in the zero-shot setting. Our datasets, models, and code are open-sourced at: https://github.com/BFlameSwift/Uni-MuMER
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Aug 30, 2024



The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.
Vote&Mix: Plug-and-Play Token Reduction for Efficient Vision Transformer
Aug 30, 2024



Despite the remarkable success of Vision Transformers (ViTs) in various visual tasks, they are often hindered by substantial computational cost. In this work, we introduce Vote\&Mix (\textbf{VoMix}), a plug-and-play and parameter-free token reduction method, which can be readily applied to off-the-shelf ViT models \textit{without any training}. VoMix tackles the computational redundancy of ViTs by identifying tokens with high homogeneity through a layer-wise token similarity voting mechanism. Subsequently, the selected tokens are mixed into the retained set, thereby preserving visual information. Experiments demonstrate VoMix significantly improves the speed-accuracy tradeoff of ViTs on both images and videos. Without any training, VoMix achieves a 2$\times$ increase in throughput of existing ViT-H on ImageNet-1K and a 2.4$\times$ increase in throughput of existing ViT-L on Kinetics-400 video dataset, with a mere 0.3\% drop in top-1 accuracy.
SketchRef: A Benchmark Dataset and Evaluation Metrics for Automated Sketch Synthesis
Aug 16, 2024



Sketch, a powerful artistic technique to capture essential visual information about real-world objects, is increasingly gaining attention in the image synthesis field. However, evaluating the quality of synthesized sketches presents unique unsolved challenges. Current evaluation methods for sketch synthesis are inadequate due to the lack of a unified benchmark dataset, over-reliance on classification accuracy for recognizability, and unfair evaluation of sketches with different levels of simplification. To address these issues, we introduce SketchRef, a benchmark dataset comprising 4 categories of reference photos--animals, human faces, human bodies, and common objects--alongside novel evaluation metrics. Considering that classification accuracy is insufficient to measure the structural consistency between a sketch and its reference photo, we propose the mean Object Keypoint Similarity (mOKS) metric, utilizing pose estimation to assess structure-level recognizability. To ensure fair evaluation sketches with different simplification levels, we propose a recognizability calculation method constrained by simplicity. We also collect 8K responses from art enthusiasts, validating the effectiveness of our proposed evaluation methods. We hope this work can provide a comprehensive evaluation of sketch synthesis algorithms, thereby aligning their performance more closely with human understanding.
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
May 16, 2021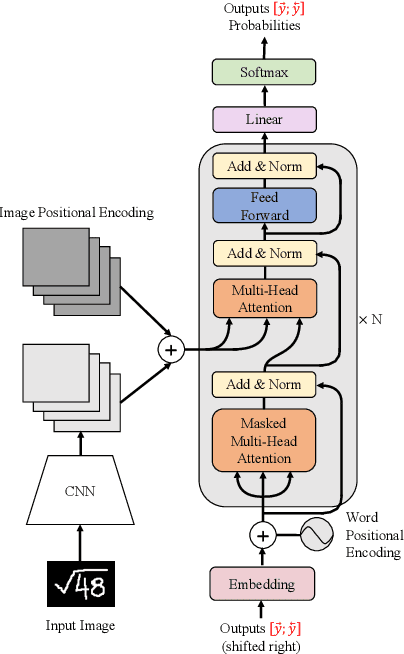
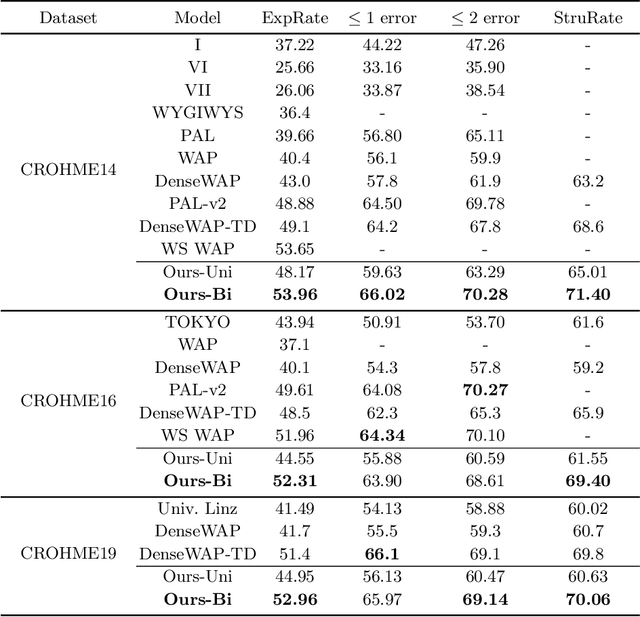
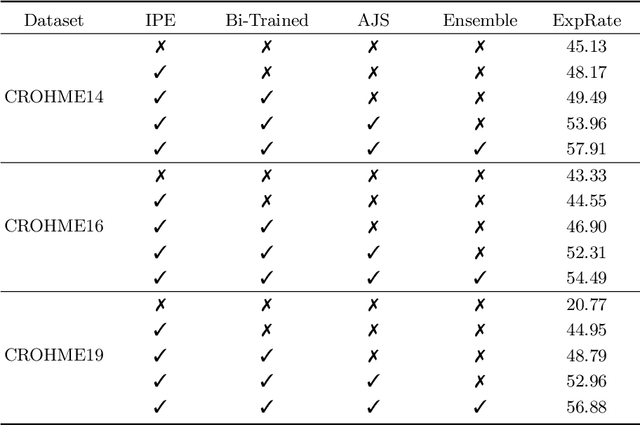
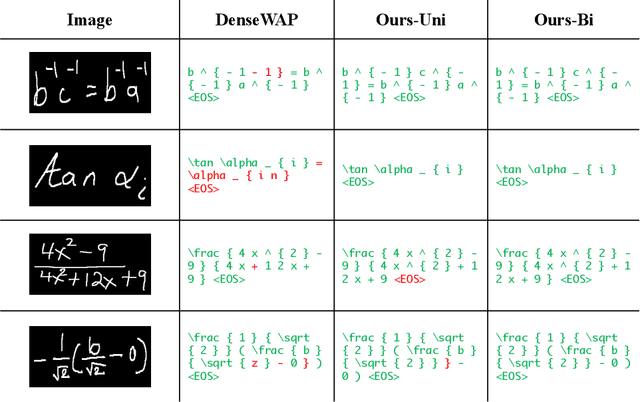
Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.
MathBERT: A Pre-Trained Model for Mathematical Formula Understanding
May 02, 2021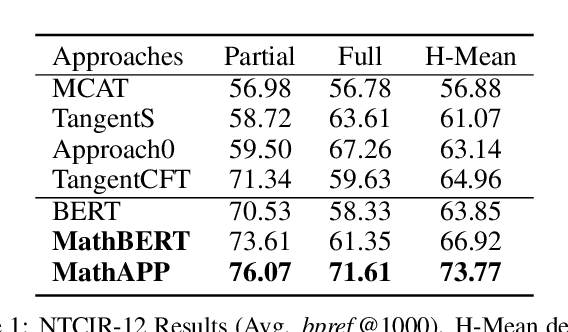
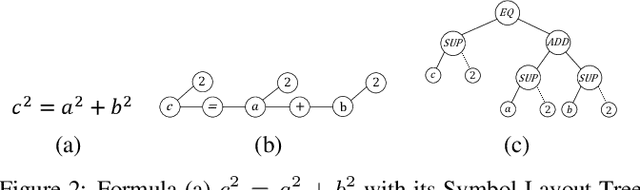
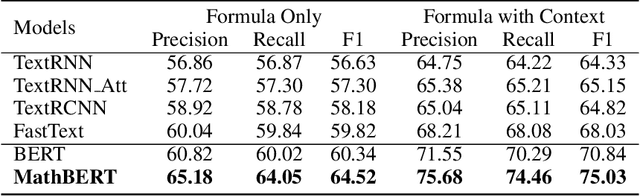
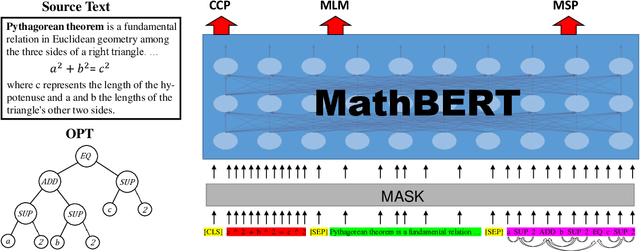
Large-scale pre-trained models like BERT, have obtained a great success in various Natural Language Processing (NLP) tasks, while it is still a challenge to adapt them to the math-related tasks. Current pre-trained models neglect the structural features and the semantic correspondence between formula and its context. To address these issues, we propose a novel pre-trained model, namely \textbf{MathBERT}, which is jointly trained with mathematical formulas and their corresponding contexts. In addition, in order to further capture the semantic-level structural features of formulas, a new pre-training task is designed to predict the masked formula substructures extracted from the Operator Tree (OPT), which is the semantic structural representation of formulas. We conduct various experiments on three downstream tasks to evaluate the performance of MathBERT, including mathematical information retrieval, formula topic classification and formula headline generation. Experimental results demonstrate that MathBERT significantly outperforms existing methods on all those three tasks. Moreover, we qualitatively show that this pre-trained model effectively captures the semantic-level structural information of formulas. To the best of our knowledge, MathBERT is the first pre-trained model for mathematical formula understanding.