 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilHuBERT: Speech Representation Learning by Layer-wise Distillation of Hidden-unit BERT
Oct 06, 2021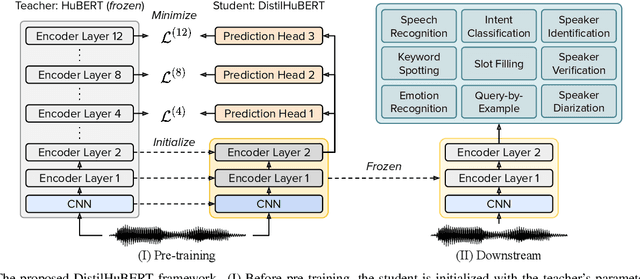
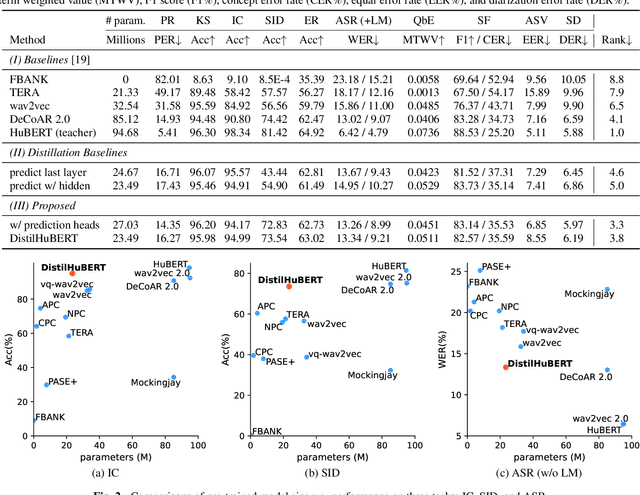
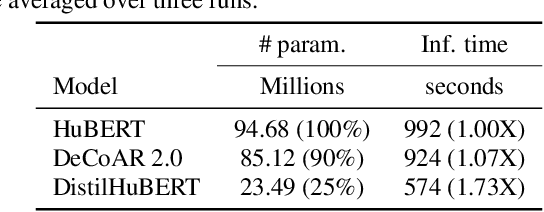
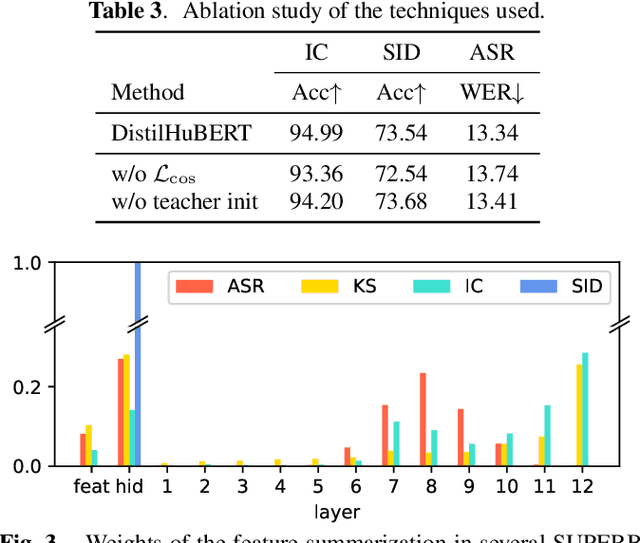
Self-supervised speech representation learning methods like wav2vec 2.0 and Hidden-unit BERT (HuBERT) leverage unlabeled speech data for pre-training and offer good representations for numerous speech processing tasks. Despite the success of these methods, they require large memory and high pre-training costs, making them inaccessible for researchers in academia and small companies. Therefore, this paper introduces DistilHuBERT, a novel multi-task learning framework to distill hidden representations from a HuBERT model directly. This method reduces HuBERT's size by 75% and 73% faster while retaining most performance in ten different tasks. Moreover, DistilHuBERT required little training time and data, opening the possibilities of pre-training personal and on-device SSL models for speech.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021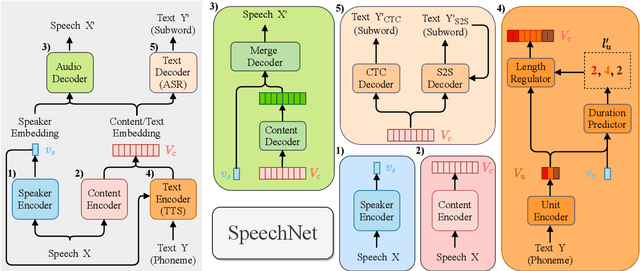
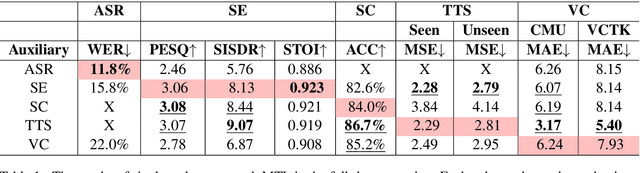
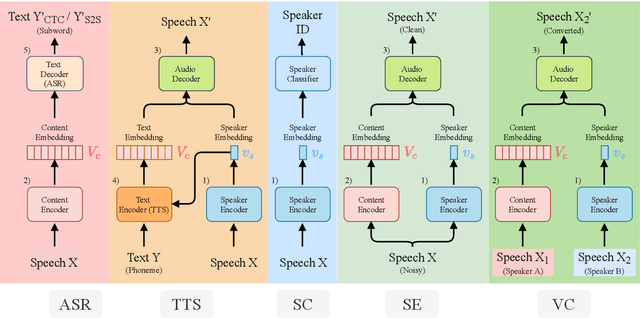
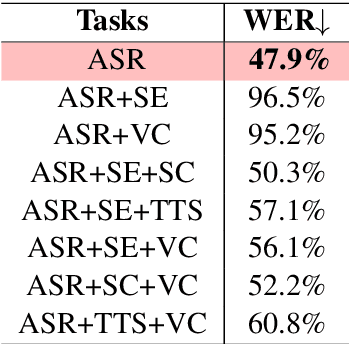
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021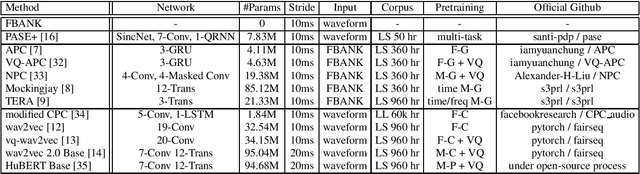
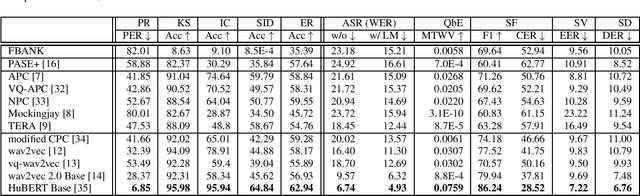
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
Understanding Self-Attention of Self-Supervised Audio Transformers
Jun 05, 2020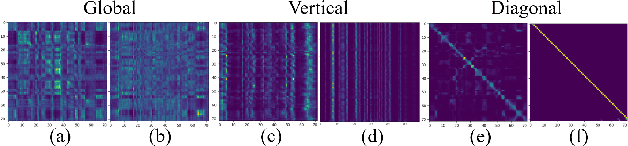
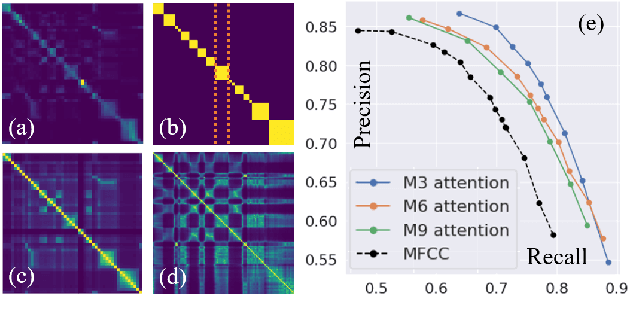
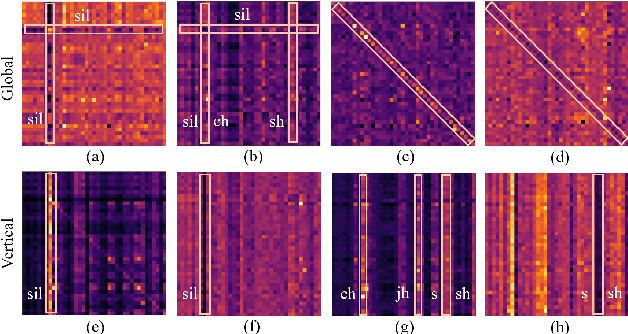
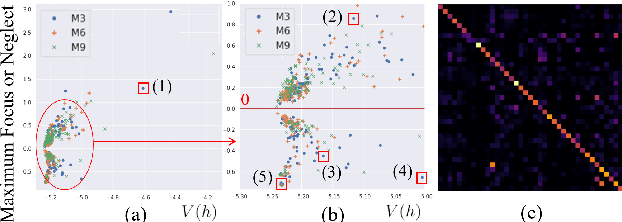
Self-supervised Audio Transformers (SAT) enable great success in many downstream speech applications like ASR, but how they work has not been widely explored yet. In this work, we present multiple strategies for the analysis of attention mechanisms in SAT. We categorize attentions into explainable categories, where we discover each category possesses its own unique functionality. We provide a visualization tool for understanding multi-head self-attention, importance ranking strategies for identifying critical attention, and attention refinement techniques to improve model performance.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019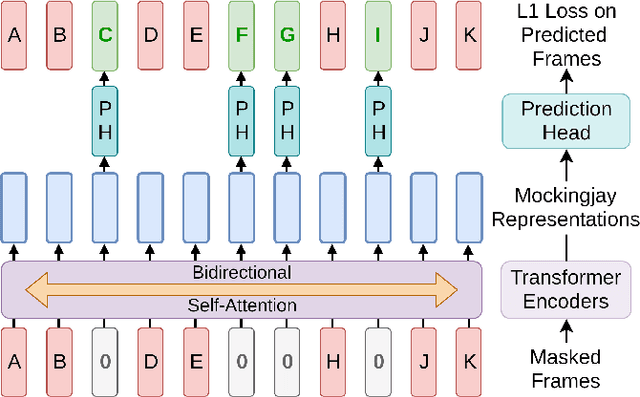
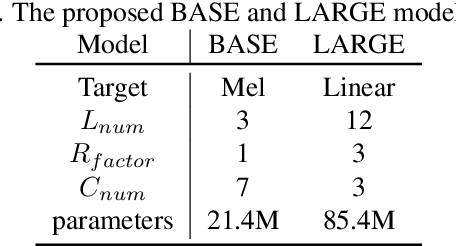
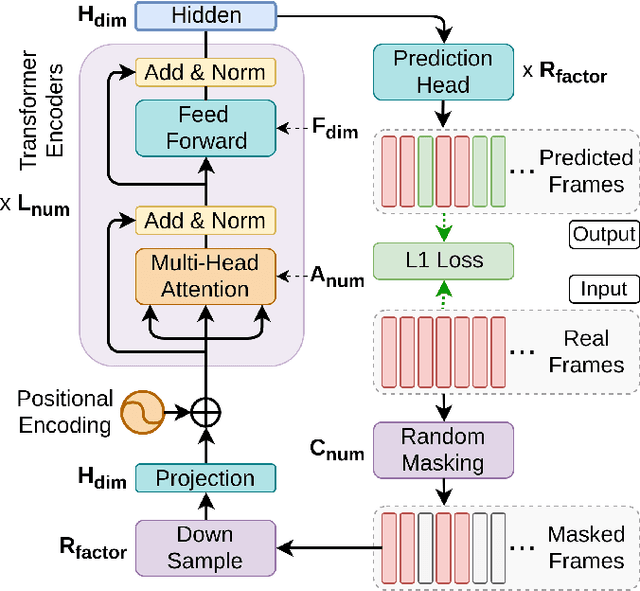
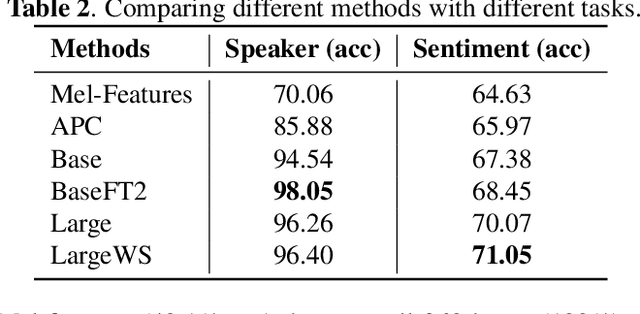
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.