 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Layer-wise SSL Features Improve Zero-Shot ASR Performance for Children's Speech?
Aug 28, 2025Automatic Speech Recognition (ASR) systems often struggle to accurately process children's speech due to its distinct and highly variable acoustic and linguistic characteristics. While recent advancements in self-supervised learning (SSL) models have greatly enhanced the transcription of adult speech, accurately transcribing children's speech remains a significant challenge. This study investigates the effectiveness of layer-wise features extracted from state-of-the-art SSL pre-trained models - specifically, Wav2Vec2, HuBERT, Data2Vec, and WavLM in improving the performance of ASR for children's speech in zero-shot scenarios. A detailed analysis of features extracted from these models was conducted, integrating them into a simplified DNN-based ASR system using the Kaldi toolkit. The analysis identified the most effective layers for enhancing ASR performance on children's speech in a zero-shot scenario, where WSJCAM0 adult speech was used for training and PFSTAR children speech for testing. Experimental results indicated that Layer 22 of the Wav2Vec2 model achieved the lowest Word Error Rate (WER) of 5.15%, representing a 51.64% relative improvement over the direct zero-shot decoding using Wav2Vec2 (WER of 10.65%). Additionally, age group-wise analysis demonstrated consistent performance improvements with increasing age, along with significant gains observed even in younger age groups using the SSL features. Further experiments on the CMU Kids dataset confirmed similar trends, highlighting the generalizability of the proposed approach.
* Accepted
Decoding Neural Signatures of Semantic Evaluations in Depression and Suicidality
Jul 30, 2025



Depression and suicidality profoundly impact cognition and emotion, yet objective neurophysiological biomarkers remain elusive. We investigated the spatiotemporal neural dynamics underlying affective semantic processing in individuals with varying levels of clinical severity of depression and suicidality using multivariate decoding of electroencephalography (EEG) data. Participants (N=137) completed a sentence evaluation task involving emotionally charged self-referential statements while EEG was recorded. We identified robust, neural signatures of semantic processing, with peak decoding accuracy between 300-600 ms -- a window associated with automatic semantic evaluation and conflict monitoring. Compared to healthy controls, individuals with depression and suicidality showed earlier onset, longer duration, and greater amplitude decoding responses, along with broader cross-temporal generalization and increased activation of frontocentral and parietotemporal components. These findings suggest altered sensitivity and impaired disengagement from emotionally salient content in the clinical groups, advancing our understanding of the neurocognitive basis of mental health and providing a principled basis for developing reliable EEG-based biomarkers of depression and suicidality.
Joint ASR and Speaker Role Tagging with Serialized Output Training
Jun 12, 2025



Automatic Speech Recognition systems have made significant progress with large-scale pre-trained models. However, most current systems focus solely on transcribing the speech without identifying speaker roles, a function that is critical for conversational AI. In this work, we investigate the use of serialized output training (SOT) for joint ASR and speaker role tagging. By augmenting Whisper with role-specific tokens and fine-tuning it with SOT, we enable the model to generate role-aware transcriptions in a single decoding pass. We compare the SOT approach against a self-supervised previous baseline method on two real-world conversational datasets. Our findings show that this approach achieves more than 10% reduction in multi-talker WER, demonstrating its feasibility as a unified model for speaker-role aware speech transcription.
Developing a High-performance Framework for Speech Emotion Recognition in Naturalistic Conditions Challenge for Emotional Attribute Prediction
Jun 12, 2025Speech emotion recognition (SER) in naturalistic conditions presents a significant challenge for the speech processing community. Challenges include disagreement in labeling among annotators and imbalanced data distributions. This paper presents a reproducible framework that achieves superior (top 1) performance in the Emotion Recognition in Naturalistic Conditions Challenge (IS25-SER Challenge) - Task 2, evaluated on the MSP-Podcast dataset. Our system is designed to tackle the aforementioned challenges through multimodal learning, multi-task learning, and imbalanced data handling. Specifically, our best system is trained by adding text embeddings, predicting gender, and including ``Other'' (O) and ``No Agreement'' (X) samples in the training set. Our system's results secured both first and second places in the IS25-SER Challenge, and the top performance was achieved by a simple two-system ensemble.
Neural Responses to Affective Sentences Reveal Signatures of Depression
Jun 06, 2025



Major Depressive Disorder (MDD) is a highly prevalent mental health condition, and a deeper understanding of its neurocognitive foundations is essential for identifying how core functions such as emotional and self-referential processing are affected. We investigate how depression alters the temporal dynamics of emotional processing by measuring neural responses to self-referential affective sentences using surface electroencephalography (EEG) in healthy and depressed individuals. Our results reveal significant group-level differences in neural activity during sentence viewing, suggesting disrupted integration of emotional and self-referential information in depression. Deep learning model trained on these responses achieves an area under the receiver operating curve (AUC) of 0.707 in distinguishing healthy from depressed participants, and 0.624 in differentiating depressed subgroups with and without suicidal ideation. Spatial ablations highlight anterior electrodes associated with semantic and affective processing as key contributors. These findings suggest stable, stimulus-driven neural signatures of depression that may inform future diagnostic tools.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025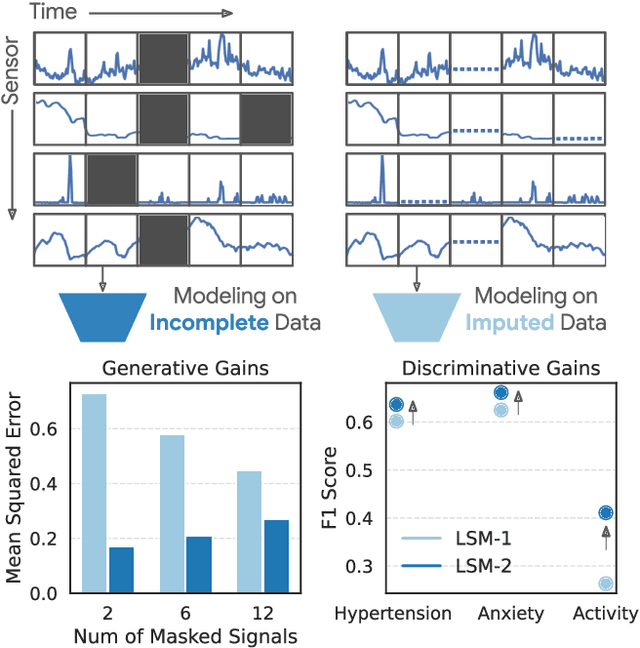
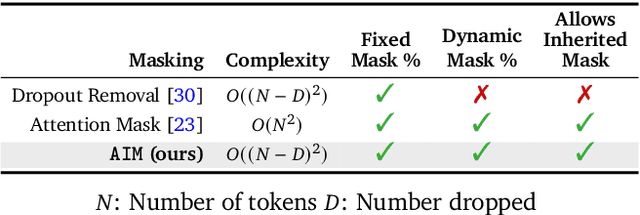
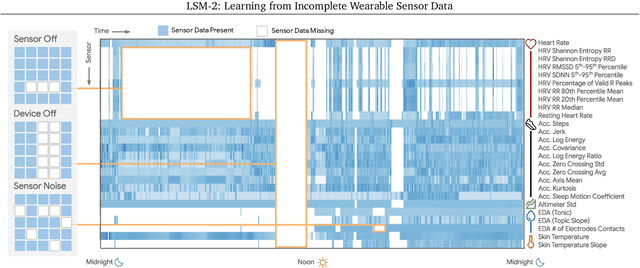
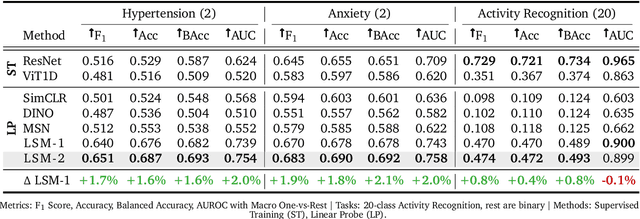
Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
Developing a Top-tier Framework in Naturalistic Conditions Challenge for Categorized Emotion Prediction: From Speech Foundation Models and Learning Objective to Data Augmentation and Engineering Choices
May 28, 2025Speech emotion recognition (SER), particularly for naturally expressed emotions, remains a challenging computational task. Key challenges include the inherent subjectivity in emotion annotation and the imbalanced distribution of emotion labels in datasets. This paper introduces the \texttt{SAILER} system developed for participation in the INTERSPEECH 2025 Emotion Recognition Challenge (Task 1). The challenge dataset, which contains natural emotional speech from podcasts, serves as a valuable resource for studying imbalanced and subjective emotion annotations. Our system is designed to be simple, reproducible, and effective, highlighting critical choices in modeling, learning objectives, data augmentation, and engineering choices. Results show that even a single system (without ensembling) can outperform more than 95\% of the submissions, with a Macro-F1 score exceeding 0.4. Moreover, an ensemble of three systems further improves performance, achieving a competitively ranked score (top-3 performing team). Our model is at: https://github.com/tiantiaf0627/vox-profile-release.
Large Language Models Do Multi-Label Classification Differently
May 23, 2025Multi-label classification is prevalent in real-world settings, but the behavior of Large Language Models (LLMs) in this setting is understudied. We investigate how autoregressive LLMs perform multi-label classification, with a focus on subjective tasks, by analyzing the output distributions of the models in each generation step. We find that their predictive behavior reflects the multiple steps in the underlying language modeling required to generate all relevant labels as they tend to suppress all but one label at each step. We further observe that as model scale increases, their token distributions exhibit lower entropy, yet the internal ranking of the labels improves. Finetuning methods such as supervised finetuning and reinforcement learning amplify this phenomenon. To further study this issue, we introduce the task of distribution alignment for multi-label settings: aligning LLM-derived label distributions with empirical distributions estimated from annotator responses in subjective tasks. We propose both zero-shot and supervised methods which improve both alignment and predictive performance over existing approaches.
Large Language Models based ASR Error Correction for Child Conversations
May 22, 2025



Automatic Speech Recognition (ASR) has recently shown remarkable progress, but accurately transcribing children's speech remains a significant challenge. Recent developments in Large Language Models (LLMs) have shown promise in improving ASR transcriptions. However, their applications in child speech including conversational scenarios are underexplored. In this study, we explore the use of LLMs in correcting ASR errors for conversational child speech. We demonstrate the promises and challenges of LLMs through experiments on two children's conversational speech datasets with both zero-shot and fine-tuned ASR outputs. We find that while LLMs are helpful in correcting zero-shot ASR outputs and fine-tuned CTC-based ASR outputs, it remains challenging for LLMs to improve ASR performance when incorporating contextual information or when using fine-tuned autoregressive ASR (e.g., Whisper) outputs.