 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Representation Learning for Hierarchical Reinforcement Learning
Oct 02, 2018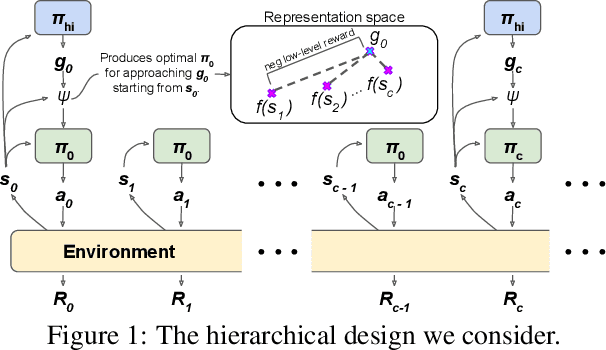
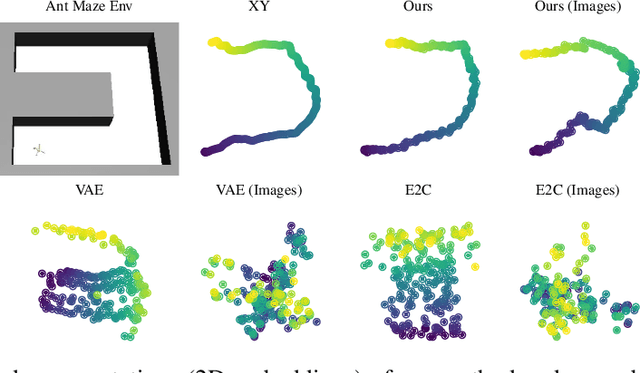
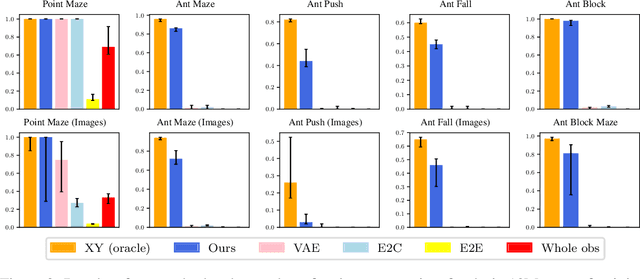
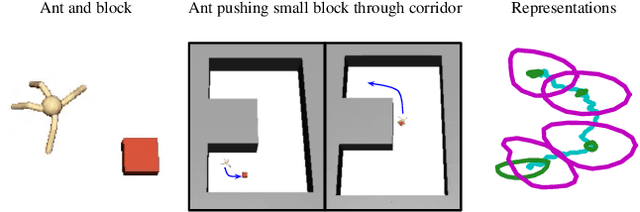
We study the problem of representation learning in goal-conditioned hierarchical reinforcement learning. In such hierarchical structures, a higher-level controller solves tasks by iteratively communicating goals which a lower-level policy is trained to reach. Accordingly, the choice of representation -- the mapping of observation space to goal space -- is crucial. To study this problem, we develop a notion of sub-optimality of a representation, defined in terms of expected reward of the optimal hierarchical policy using this representation. We derive expressions which bound the sub-optimality and show how these expressions can be translated to representation learning objectives which may be optimized in practice. Results on a number of difficult continuous-control tasks show that our approach to representation learning yields qualitatively better representations as well as quantitatively better hierarchical policies, compared to existing methods (see videos at https://sites.google.com/view/representation-hrl).
The Mirage of Action-Dependent Baselines in Reinforcement Learning
Apr 06, 2018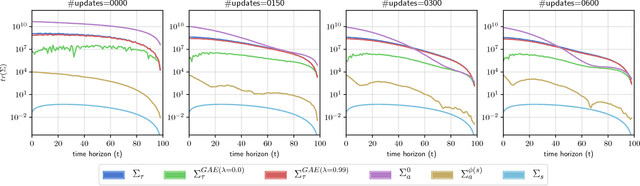
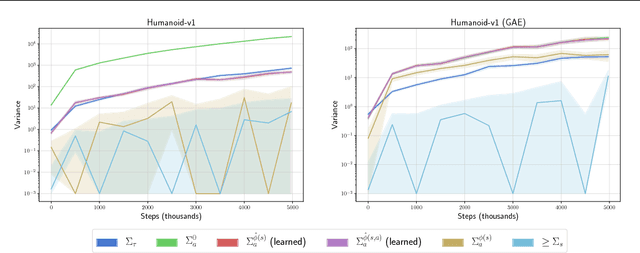
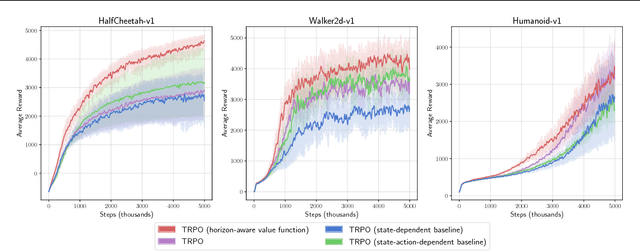
Policy gradient methods are a widely used class of model-free reinforcement learning algorithms where a state-dependent baseline is used to reduce gradient estimator variance. Several recent papers extend the baseline to depend on both the state and action and suggest that this significantly reduces variance and improves sample efficiency without introducing bias into the gradient estimates. To better understand this development, we decompose the variance of the policy gradient estimator and numerically show that learned state-action-dependent baselines do not in fact reduce variance over a state-dependent baseline in commonly tested benchmark domains. We confirm this unexpected result by reviewing the open-source code accompanying these prior papers, and show that subtle implementation decisions cause deviations from the methods presented in the papers and explain the source of the previously observed empirical gains. Furthermore, the variance decomposition highlights areas for improvement, which we demonstrate by illustrating a simple change to the typical value function parameterization that can significantly improve performance.
Temporal Difference Models: Model-Free Deep RL for Model-Based Control
Feb 25, 2018
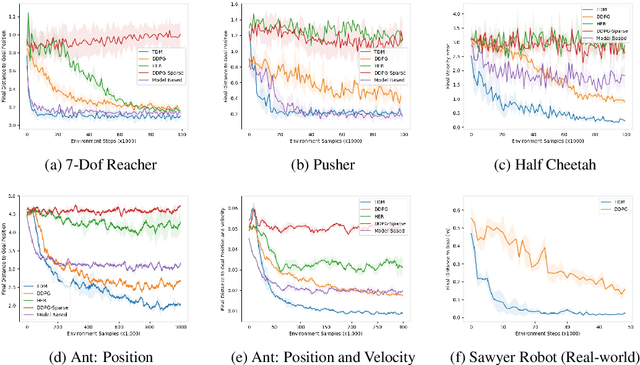
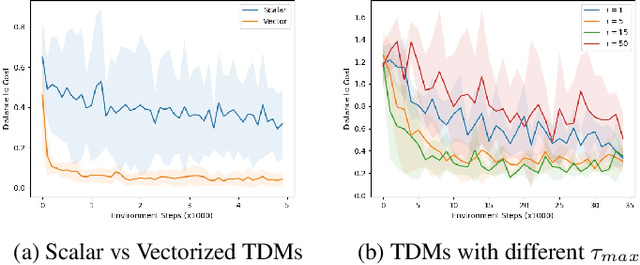
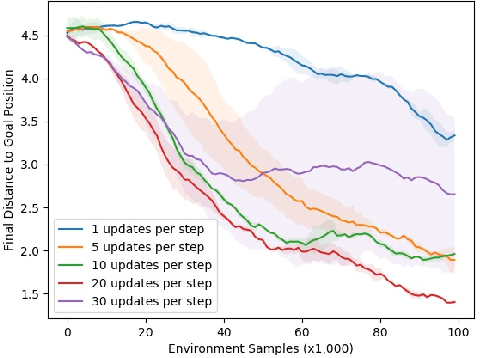
Model-free reinforcement learning (RL) is a powerful, general tool for learning complex behaviors. However, its sample efficiency is often impractically large for solving challenging real-world problems, even with off-policy algorithms such as Q-learning. A limiting factor in classic model-free RL is that the learning signal consists only of scalar rewards, ignoring much of the rich information contained in state transition tuples. Model-based RL uses this information, by training a predictive model, but often does not achieve the same asymptotic performance as model-free RL due to model bias. We introduce temporal difference models (TDMs), a family of goal-conditioned value functions that can be trained with model-free learning and used for model-based control. TDMs combine the benefits of model-free and model-based RL: they leverage the rich information in state transitions to learn very efficiently, while still attaining asymptotic performance that exceeds that of direct model-based RL methods. Our experimental results show that, on a range of continuous control tasks, TDMs provide a substantial improvement in efficiency compared to state-of-the-art model-based and model-free methods.
Leave no Trace: Learning to Reset for Safe and Autonomous Reinforcement Learning
Nov 18, 2017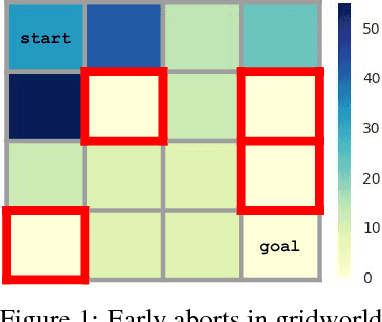
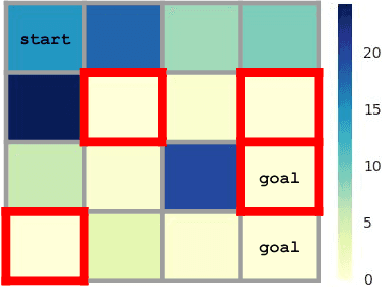
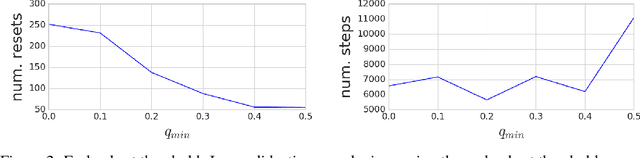
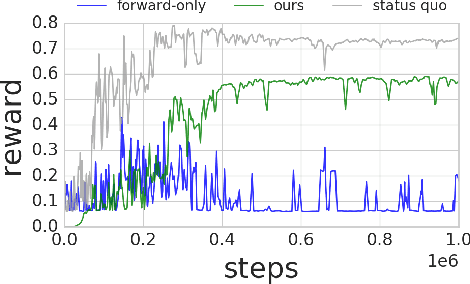
Deep reinforcement learning algorithms can learn complex behavioral skills, but real-world application of these methods requires a large amount of experience to be collected by the agent. In practical settings, such as robotics, this involves repeatedly attempting a task, resetting the environment between each attempt. However, not all tasks are easily or automatically reversible. In practice, this learning process requires extensive human intervention. In this work, we propose an autonomous method for safe and efficient reinforcement learning that simultaneously learns a forward and reset policy, with the reset policy resetting the environment for a subsequent attempt. By learning a value function for the reset policy, we can automatically determine when the forward policy is about to enter a non-reversible state, providing for uncertainty-aware safety aborts. Our experiments illustrate that proper use of the reset policy can greatly reduce the number of manual resets required to learn a task, can reduce the number of unsafe actions that lead to non-reversible states, and can automatically induce a curriculum.
Sequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with KL-control
Oct 16, 2017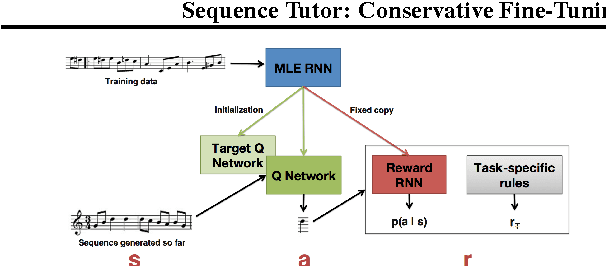
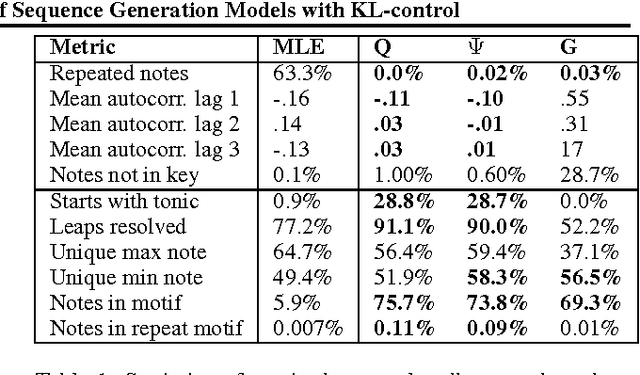
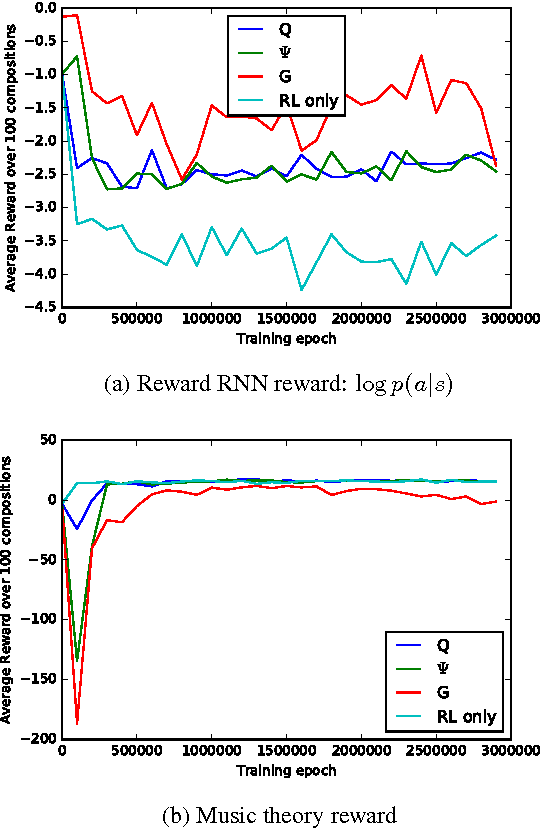
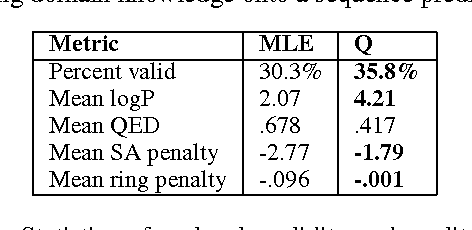
This paper proposes a general method for improving the structure and quality of sequences generated by a recurrent neural network (RNN), while maintaining information originally learned from data, as well as sample diversity. An RNN is first pre-trained on data using maximum likelihood estimation (MLE), and the probability distribution over the next token in the sequence learned by this model is treated as a prior policy. Another RNN is then trained using reinforcement learning (RL) to generate higher-quality outputs that account for domain-specific incentives while retaining proximity to the prior policy of the MLE RNN. To formalize this objective, we derive novel off-policy RL methods for RNNs from KL-control. The effectiveness of the approach is demonstrated on two applications; 1) generating novel musical melodies, and 2) computational molecular generation. For both problems, we show that the proposed method improves the desired properties and structure of the generated sequences, while maintaining information learned from data.
Categorical Reparameterization with Gumbel-Softmax
Aug 05, 2017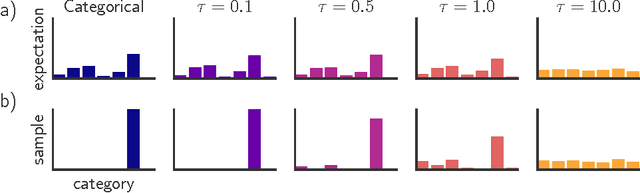

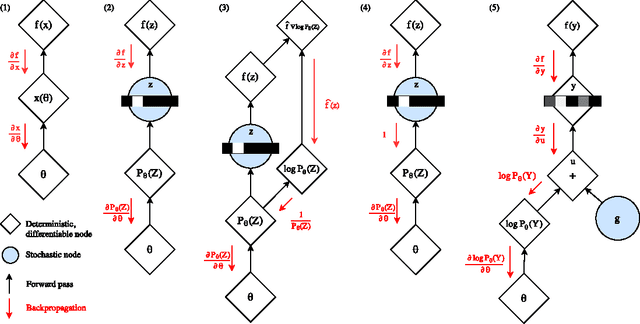
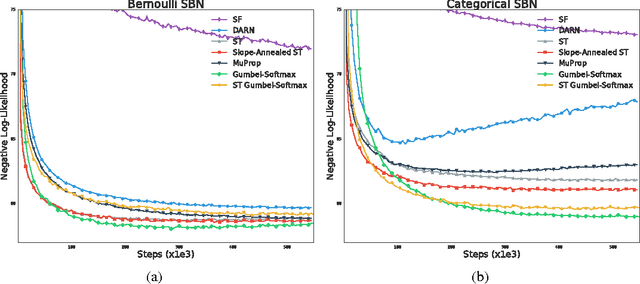
Categorical variables are a natural choice for representing discrete structure in the world. However, stochastic neural networks rarely use categorical latent variables due to the inability to backpropagate through samples. In this work, we present an efficient gradient estimator that replaces the non-differentiable sample from a categorical distribution with a differentiable sample from a novel Gumbel-Softmax distribution. This distribution has the essential property that it can be smoothly annealed into a categorical distribution. We show that our Gumbel-Softmax estimator outperforms state-of-the-art gradient estimators on structured output prediction and unsupervised generative modeling tasks with categorical latent variables, and enables large speedups on semi-supervised classification.
Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning
Jun 01, 2017
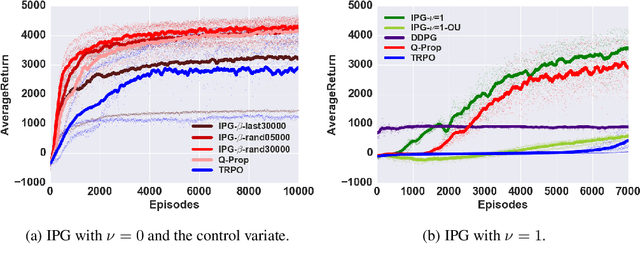
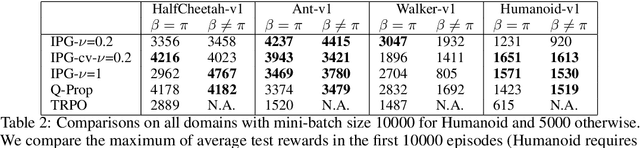
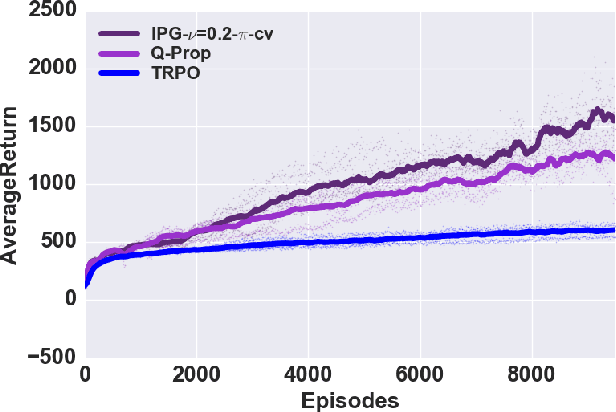
Off-policy model-free deep reinforcement learning methods using previously collected data can improve sample efficiency over on-policy policy gradient techniques. On the other hand, on-policy algorithms are often more stable and easier to use. This paper examines, both theoretically and empirically, approaches to merging on- and off-policy updates for deep reinforcement learning. Theoretical results show that off-policy updates with a value function estimator can be interpolated with on-policy policy gradient updates whilst still satisfying performance bounds. Our analysis uses control variate methods to produce a family of policy gradient algorithms, with several recently proposed algorithms being special cases of this family. We then provide an empirical comparison of these techniques with the remaining algorithmic details fixed, and show how different mixing of off-policy gradient estimates with on-policy samples contribute to improvements in empirical performance. The final algorithm provides a generalization and unification of existing deep policy gradient techniques, has theoretical guarantees on the bias introduced by off-policy updates, and improves on the state-of-the-art model-free deep RL methods on a number of OpenAI Gym continuous control benchmarks.
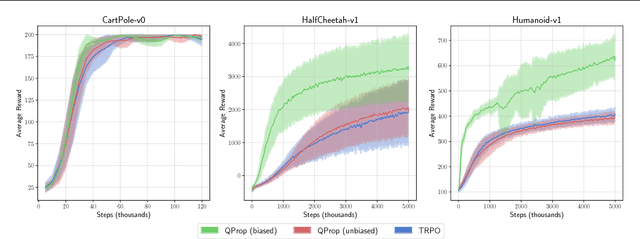
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic
Feb 27, 2017
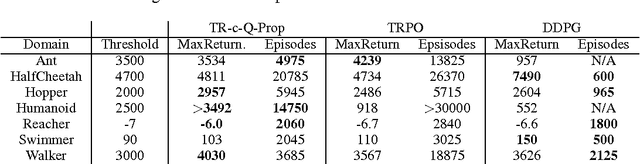
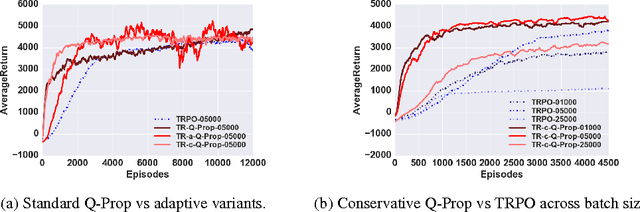

Model-free deep reinforcement learning (RL) methods have been successful in a wide variety of simulated domains. However, a major obstacle facing deep RL in the real world is their high sample complexity. Batch policy gradient methods offer stable learning, but at the cost of high variance, which often requires large batches. TD-style methods, such as off-policy actor-critic and Q-learning, are more sample-efficient but biased, and often require costly hyperparameter sweeps to stabilize. In this work, we aim to develop methods that combine the stability of policy gradients with the efficiency of off-policy RL. We present Q-Prop, a policy gradient method that uses a Taylor expansion of the off-policy critic as a control variate. Q-Prop is both sample efficient and stable, and effectively combines the benefits of on-policy and off-policy methods. We analyze the connection between Q-Prop and existing model-free algorithms, and use control variate theory to derive two variants of Q-Prop with conservative and aggressive adaptation. We show that conservative Q-Prop provides substantial gains in sample efficiency over trust region policy optimization (TRPO) with generalized advantage estimation (GAE), and improves stability over deep deterministic policy gradient (DDPG), the state-of-the-art on-policy and off-policy methods, on OpenAI Gym's MuJoCo continuous control environments.
Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
Nov 23, 2016
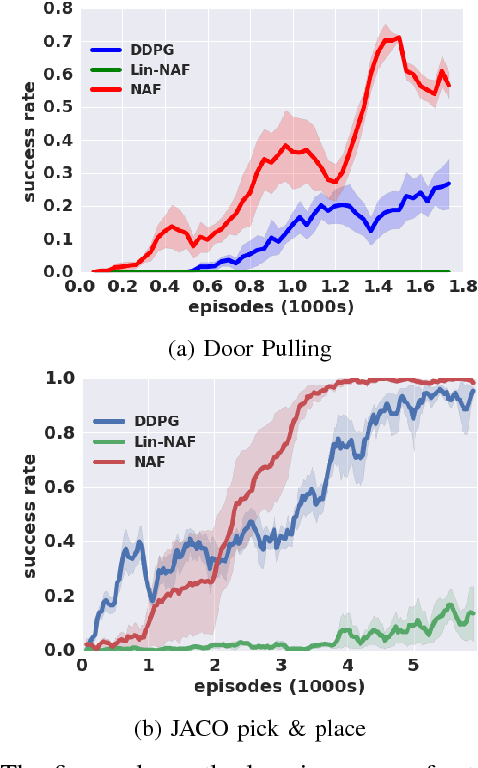
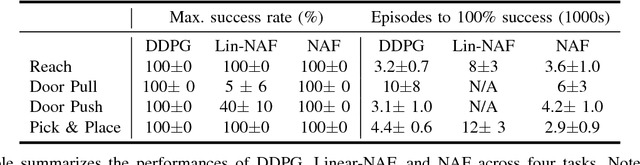
Reinforcement learning holds the promise of enabling autonomous robots to learn large repertoires of behavioral skills with minimal human intervention. However, robotic applications of reinforcement learning often compromise the autonomy of the learning process in favor of achieving training times that are practical for real physical systems. This typically involves introducing hand-engineered policy representations and human-supplied demonstrations. Deep reinforcement learning alleviates this limitation by training general-purpose neural network policies, but applications of direct deep reinforcement learning algorithms have so far been restricted to simulated settings and relatively simple tasks, due to their apparent high sample complexity. In this paper, we demonstrate that a recent deep reinforcement learning algorithm based on off-policy training of deep Q-functions can scale to complex 3D manipulation tasks and can learn deep neural network policies efficiently enough to train on real physical robots. We demonstrate that the training times can be further reduced by parallelizing the algorithm across multiple robots which pool their policy updates asynchronously. Our experimental evaluation shows that our method can learn a variety of 3D manipulation skills in simulation and a complex door opening skill on real robots without any prior demonstrations or manually designed representations.
Continuous Deep Q-Learning with Model-based Acceleration
Mar 02, 2016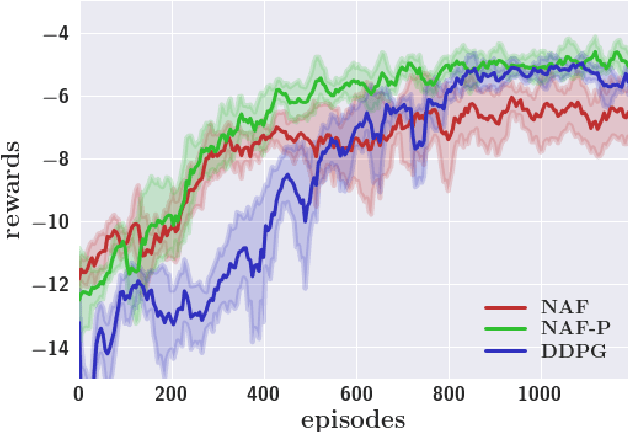
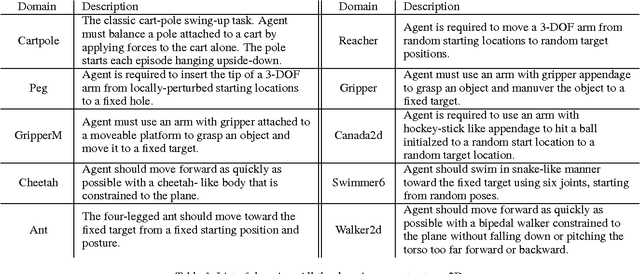
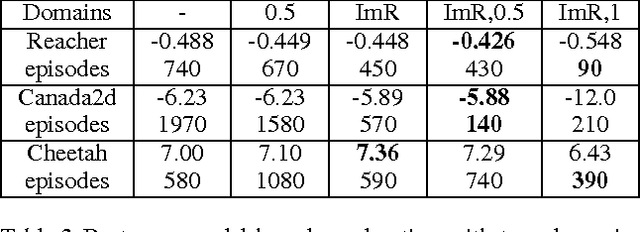
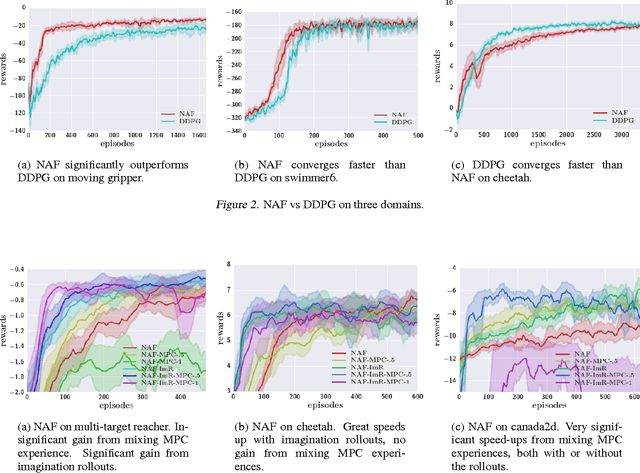
Model-free reinforcement learning has been successfully applied to a range of challenging problems, and has recently been extended to handle large neural network policies and value functions. However, the sample complexity of model-free algorithms, particularly when using high-dimensional function approximators, tends to limit their applicability to physical systems. In this paper, we explore algorithms and representations to reduce the sample complexity of deep reinforcement learning for continuous control tasks. We propose two complementary techniques for improving the efficiency of such algorithms. First, we derive a continuous variant of the Q-learning algorithm, which we call normalized adantage functions (NAF), as an alternative to the more commonly used policy gradient and actor-critic methods. NAF representation allows us to apply Q-learning with experience replay to continuous tasks, and substantially improves performance on a set of simulated robotic control tasks. To further improve the efficiency of our approach, we explore the use of learned models for accelerating model-free reinforcement learning. We show that iteratively refitted local linear models are especially effective for this, and demonstrate substantially faster learning on domains where such models are applicable.