 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernetworks in Meta-Reinforcement Learning
Oct 20, 2022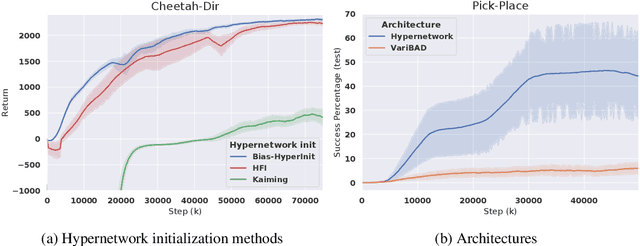

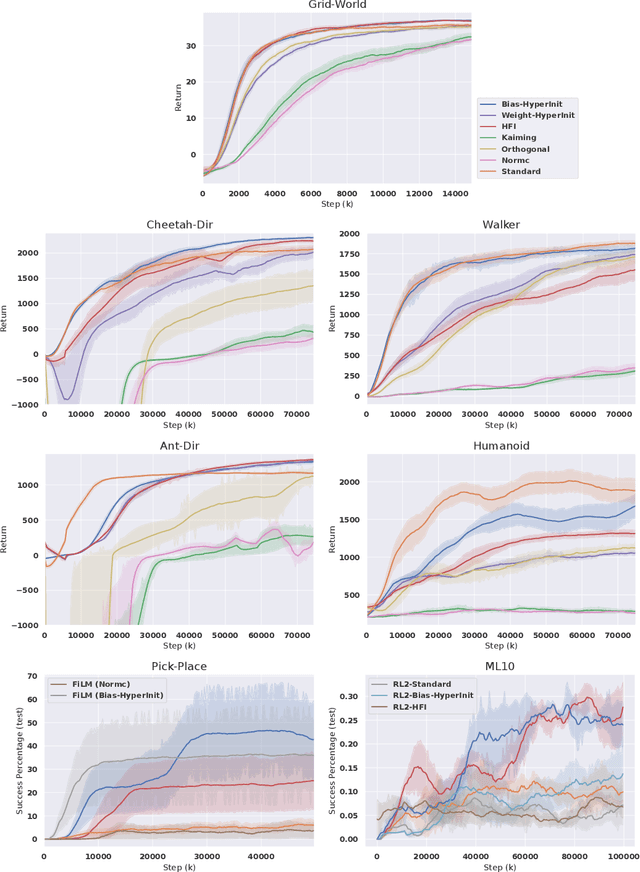
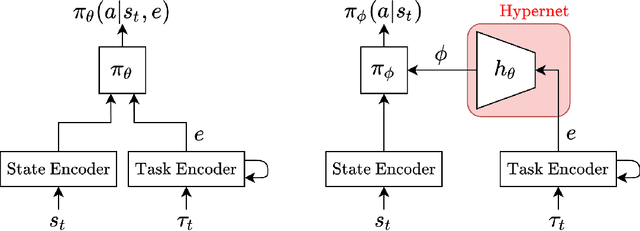
Training a reinforcement learning (RL) agent on a real-world robotics task remains generally impractical due to sample inefficiency. Multi-task RL and meta-RL aim to improve sample efficiency by generalizing over a distribution of related tasks. However, doing so is difficult in practice: In multi-task RL, state of the art methods often fail to outperform a degenerate solution that simply learns each task separately. Hypernetworks are a promising path forward since they replicate the separate policies of the degenerate solution while also allowing for generalization across tasks, and are applicable to meta-RL. However, evidence from supervised learning suggests hypernetwork performance is highly sensitive to the initialization. In this paper, we 1) show that hypernetwork initialization is also a critical factor in meta-RL, and that naive initializations yield poor performance; 2) propose a novel hypernetwork initialization scheme that matches or exceeds the performance of a state-of-the-art approach proposed for supervised settings, as well as being simpler and more general; and 3) use this method to show that hypernetworks can improve performance in meta-RL by evaluating on multiple simulated robotics benchmarks.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022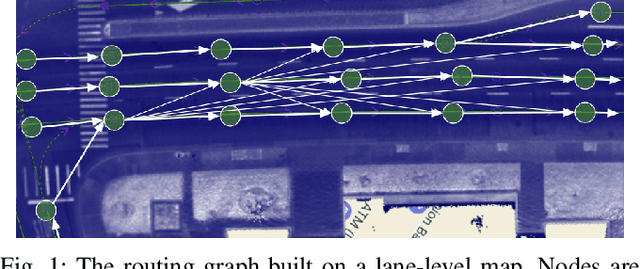
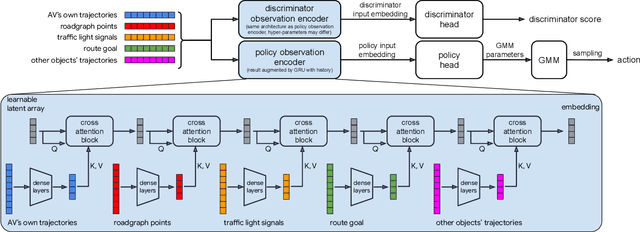
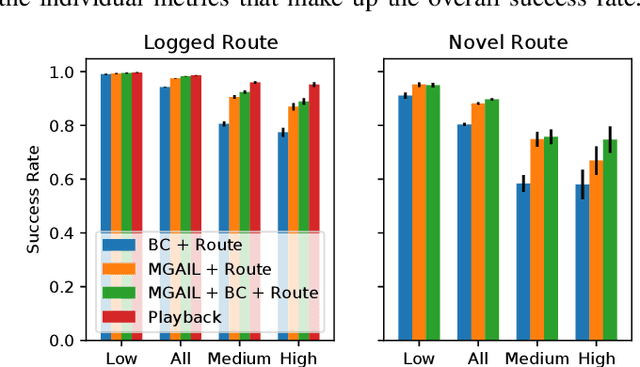
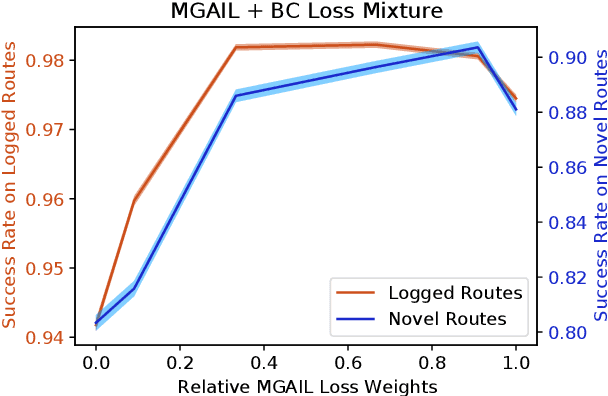
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
An Investigation of the Bias-Variance Tradeoff in Meta-Gradients
Sep 22, 2022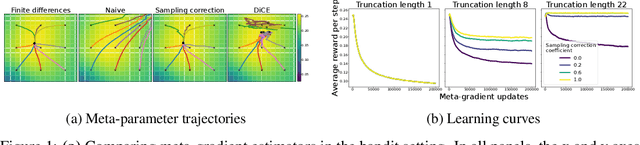

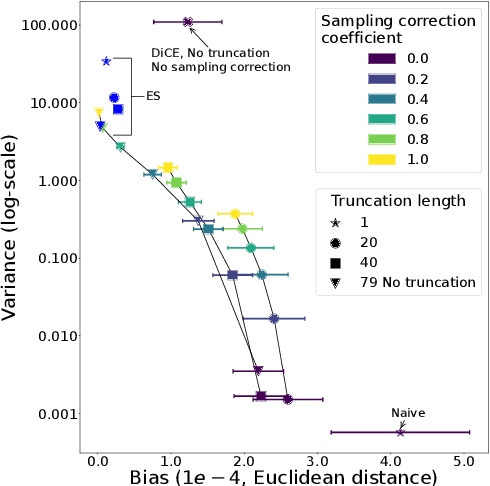

Meta-gradients provide a general approach for optimizing the meta-parameters of reinforcement learning (RL) algorithms. Estimation of meta-gradients is central to the performance of these meta-algorithms, and has been studied in the setting of MAML-style short-horizon meta-RL problems. In this context, prior work has investigated the estimation of the Hessian of the RL objective, as well as tackling the problem of credit assignment to pre-adaptation behavior by making a sampling correction. However, we show that Hessian estimation, implemented for example by DiCE and its variants, always adds bias and can also add variance to meta-gradient estimation. Meanwhile, meta-gradient estimation has been studied less in the important long-horizon setting, where backpropagation through the full inner optimization trajectories is not feasible. We study the bias and variance tradeoff arising from truncated backpropagation and sampling correction, and additionally compare to evolution strategies, which is a recently popular alternative strategy to long-horizon meta-learning. While prior work implicitly chooses points in this bias-variance space, we disentangle the sources of bias and variance and present an empirical study that relates existing estimators to each other.
Generalized Beliefs for Cooperative AI
Jun 26, 2022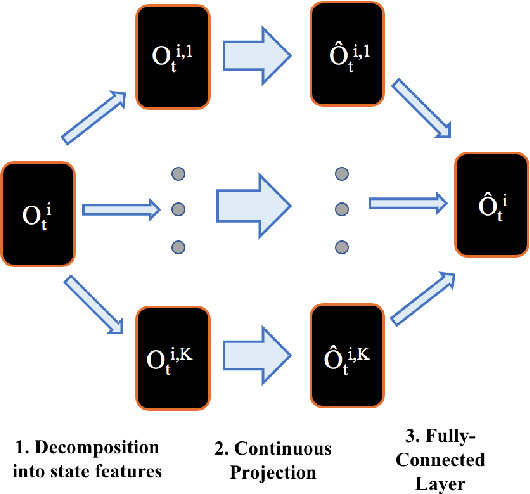
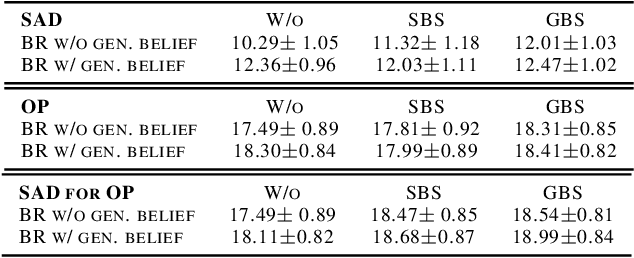
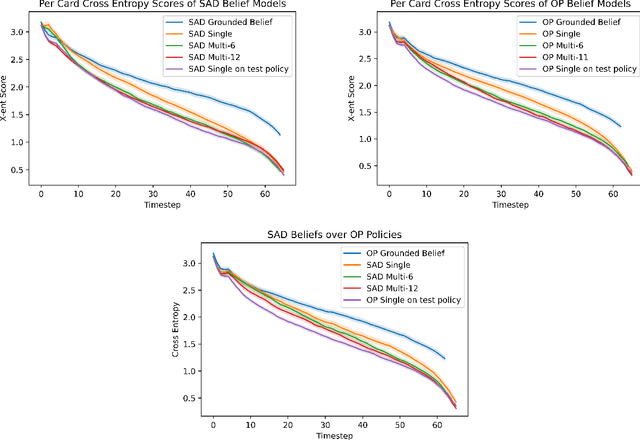

Self-play is a common paradigm for constructing solutions in Markov games that can yield optimal policies in collaborative settings. However, these policies often adopt highly-specialized conventions that make playing with a novel partner difficult. To address this, recent approaches rely on encoding symmetry and convention-awareness into policy training, but these require strong environmental assumptions and can complicate policy training. We therefore propose moving the learning of conventions to the belief space. Specifically, we propose a belief learning model that can maintain beliefs over rollouts of policies not seen at training time, and can thus decode and adapt to novel conventions at test time. We show how to leverage this model for both search and training of a best response over various pools of policies to greatly improve ad-hoc teamplay. We also show how our setup promotes explainability and interpretability of nuanced agent conventions.
Symphony: Learning Realistic and Diverse Agents for Autonomous Driving Simulation
May 06, 2022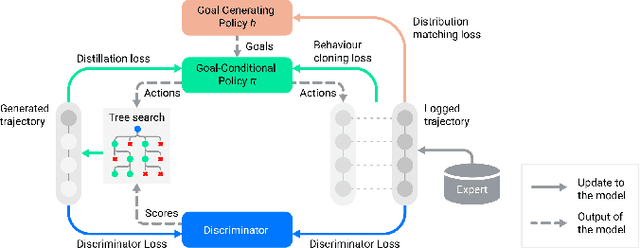
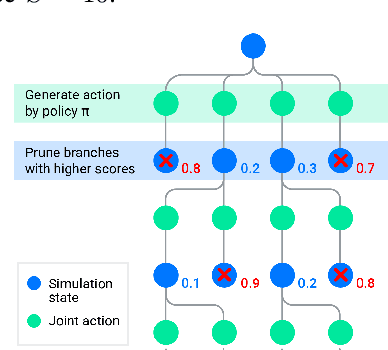
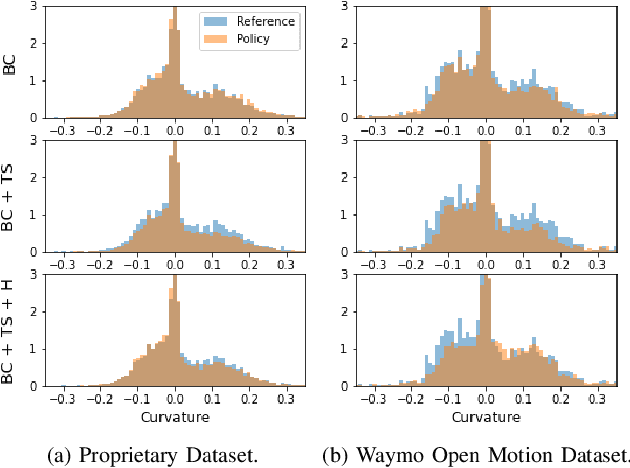
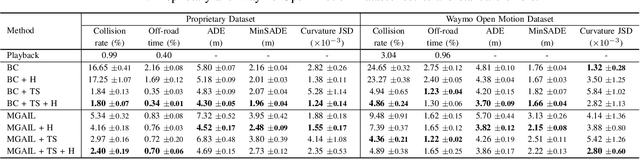
Simulation is a crucial tool for accelerating the development of autonomous vehicles. Making simulation realistic requires models of the human road users who interact with such cars. Such models can be obtained by applying learning from demonstration (LfD) to trajectories observed by cars already on the road. However, existing LfD methods are typically insufficient, yielding policies that frequently collide or drive off the road. To address this problem, we propose Symphony, which greatly improves realism by combining conventional policies with a parallel beam search. The beam search refines these policies on the fly by pruning branches that are unfavourably evaluated by a discriminator. However, it can also harm diversity, i.e., how well the agents cover the entire distribution of realistic behaviour, as pruning can encourage mode collapse. Symphony addresses this issue with a hierarchical approach, factoring agent behaviour into goal generation and goal conditioning. The use of such goals ensures that agent diversity neither disappears during adversarial training nor is pruned away by the beam search. Experiments on both proprietary and open Waymo datasets confirm that Symphony agents learn more realistic and diverse behaviour than several baselines.
Generalization in Cooperative Multi-Agent Systems
Jan 31, 2022


Collective intelligence is a fundamental trait shared by several species of living organisms. It has allowed them to thrive in the diverse environmental conditions that exist on our planet. From simple organisations in an ant colony to complex systems in human groups, collective intelligence is vital for solving complex survival tasks. As is commonly observed, such natural systems are flexible to changes in their structure. Specifically, they exhibit a high degree of generalization when the abilities or the total number of agents changes within a system. We term this phenomenon as Combinatorial Generalization (CG). CG is a highly desirable trait for autonomous systems as it can increase their utility and deployability across a wide range of applications. While recent works addressing specific aspects of CG have shown impressive results on complex domains, they provide no performance guarantees when generalizing towards novel situations. In this work, we shed light on the theoretical underpinnings of CG for cooperative multi-agent systems (MAS). Specifically, we study generalization bounds under a linear dependence of the underlying dynamics on the agent capabilities, which can be seen as a generalization of Successor Features to MAS. We then extend the results first for Lipschitz and then arbitrary dependence of rewards on team capabilities. Finally, empirical analysis on various domains using the framework of multi-agent reinforcement learning highlights important desiderata for multi-agent algorithms towards ensuring CG.
Monotonic Improvement Guarantees under Non-stationarity for Decentralized PPO
Jan 31, 2022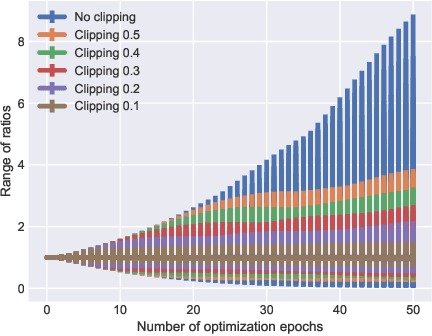
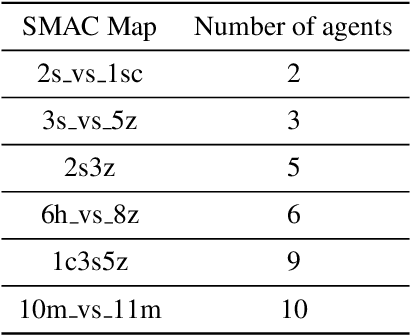
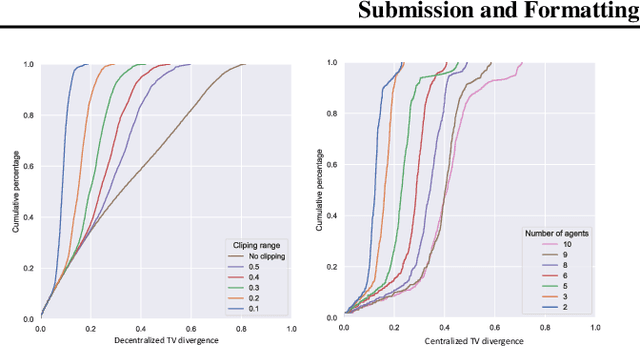
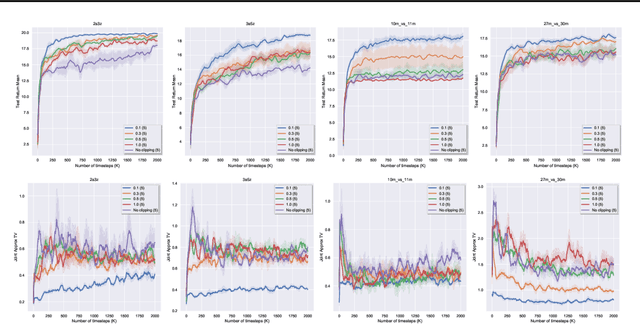
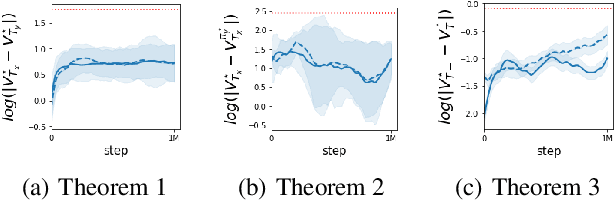
We present a new monotonic improvement guarantee for optimizing decentralized policies in cooperative Multi-Agent Reinforcement Learning (MARL), which holds even when the transition dynamics are non-stationary. This new analysis provides a theoretical understanding of the strong performance of two recent actor-critic methods for MARL, i.e., Independent Proximal Policy Optimization (IPPO) and Multi-Agent PPO (MAPPO), which both rely on independent ratios, i.e., computing probability ratios separately for each agent's policy. We show that, despite the non-stationarity that independent ratios cause, a monotonic improvement guarantee still arises as a result of enforcing the trust region constraint over all decentralized policies. We also show this trust region constraint can be effectively enforced in a principled way by bounding independent ratios based on the number of agents in training, providing a theoretical foundation for proximal ratio clipping. Moreover, we show that the surrogate objectives optimized in IPPO and MAPPO are essentially equivalent when their critics converge to a fixed point. Finally, our empirical results support the hypothesis that the strong performance of IPPO and MAPPO is a direct result of enforcing such a trust region constraint via clipping in centralized training, and the good values of the hyperparameters for this enforcement are highly sensitive to the number of agents, as predicted by our theoretical analysis.
You May Not Need Ratio Clipping in PPO
Jan 31, 2022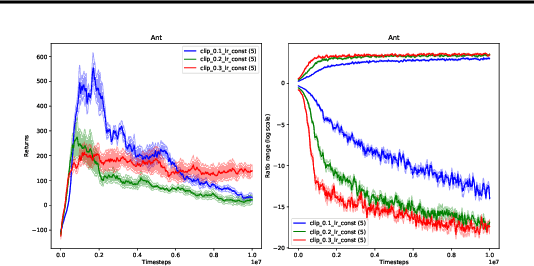

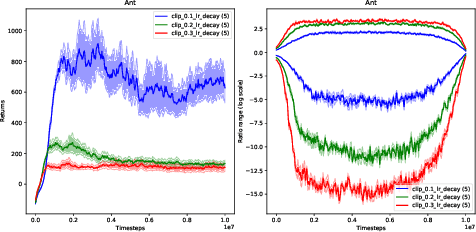
Proximal Policy Optimization (PPO) methods learn a policy by iteratively performing multiple mini-batch optimization epochs of a surrogate objective with one set of sampled data. Ratio clipping PPO is a popular variant that clips the probability ratios between the target policy and the policy used to collect samples. Ratio clipping yields a pessimistic estimate of the original surrogate objective, and has been shown to be crucial for strong performance. We show in this paper that such ratio clipping may not be a good option as it can fail to effectively bound the ratios. Instead, one can directly optimize the original surrogate objective for multiple epochs; the key is to find a proper condition to early stop the optimization epoch in each iteration. Our theoretical analysis sheds light on how to determine when to stop the optimization epoch, and call the resulting algorithm Early Stopping Policy Optimization (ESPO). We compare ESPO with PPO across many continuous control tasks and show that ESPO significantly outperforms PPO. Furthermore, we show that ESPO can be easily scaled up to distributed training with many workers, delivering strong performance as well.
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
Jan 20, 2022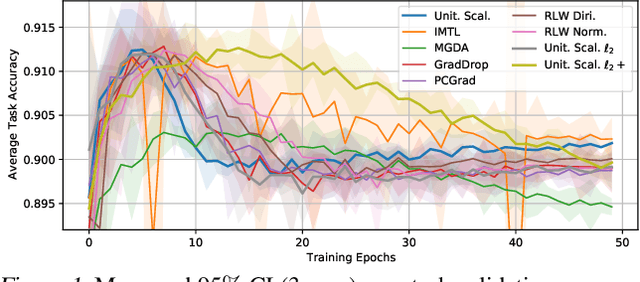


Recent multi-task learning research argues against unitary scalarization, where training simply minimizes the sum of the task losses. Several ad-hoc multi-task optimization algorithms have instead been proposed, inspired by various hypotheses about what makes multi-task settings difficult. The majority of these optimizers require per-task gradients, and introduce significant memory, runtime, and implementation overhead. We present a theoretical analysis suggesting that many specialized multi-task optimizers can be interpreted as forms of regularization. Moreover, we show that, when coupled with standard regularization and stabilization techniques from single-task learning, unitary scalarization matches or improves upon the performance of complex multi-task optimizers in both supervised and reinforcement learning settings. We believe our results call for a critical reevaluation of recent research in the area.
Deterministic and Discriminative Imitation (D2-Imitation): Revisiting Adversarial Imitation for Sample Efficiency
Dec 11, 2021
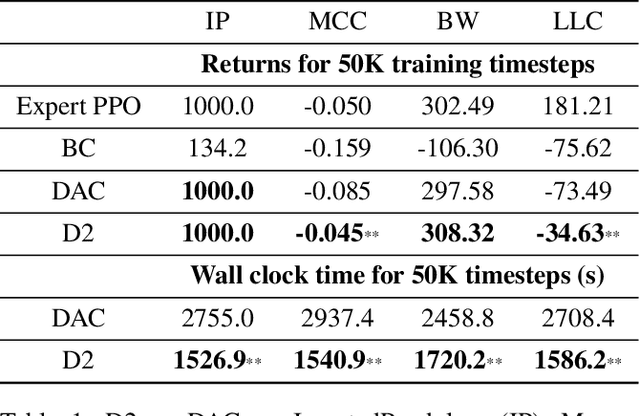
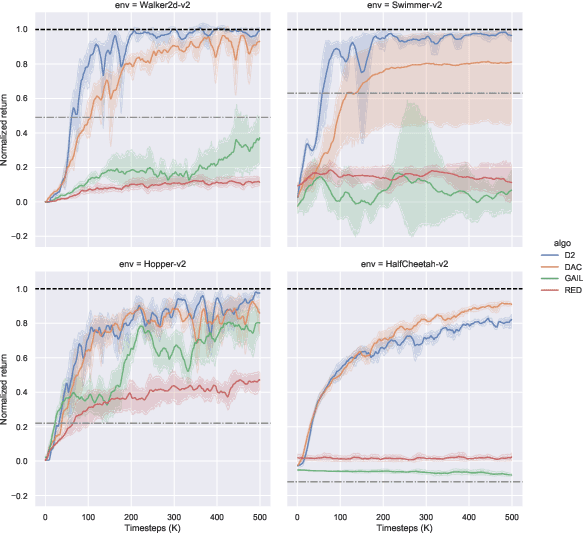
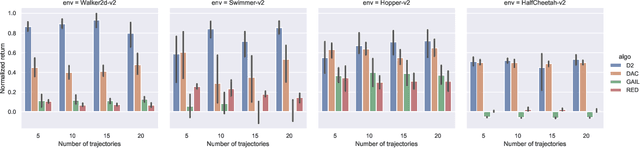
Sample efficiency is crucial for imitation learning methods to be applicable in real-world applications. Many studies improve sample efficiency by extending adversarial imitation to be off-policy regardless of the fact that these off-policy extensions could either change the original objective or involve complicated optimization. We revisit the foundation of adversarial imitation and propose an off-policy sample efficient approach that requires no adversarial training or min-max optimization. Our formulation capitalizes on two key insights: (1) the similarity between the Bellman equation and the stationary state-action distribution equation allows us to derive a novel temporal difference (TD) learning approach; and (2) the use of a deterministic policy simplifies the TD learning. Combined, these insights yield a practical algorithm, Deterministic and Discriminative Imitation (D2-Imitation), which operates by first partitioning samples into two replay buffers and then learning a deterministic policy via off-policy reinforcement learning. Our empirical results show that D2-Imitation is effective in achieving good sample efficiency, outperforming several off-policy extension approaches of adversarial imitation on many control tasks.