 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Generative Phonology
Feb 12, 2021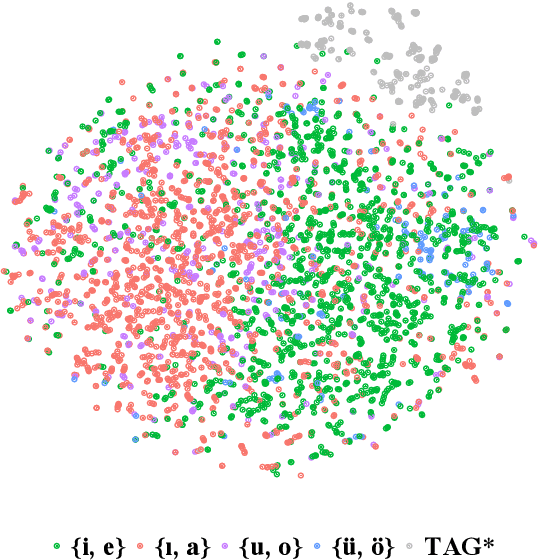
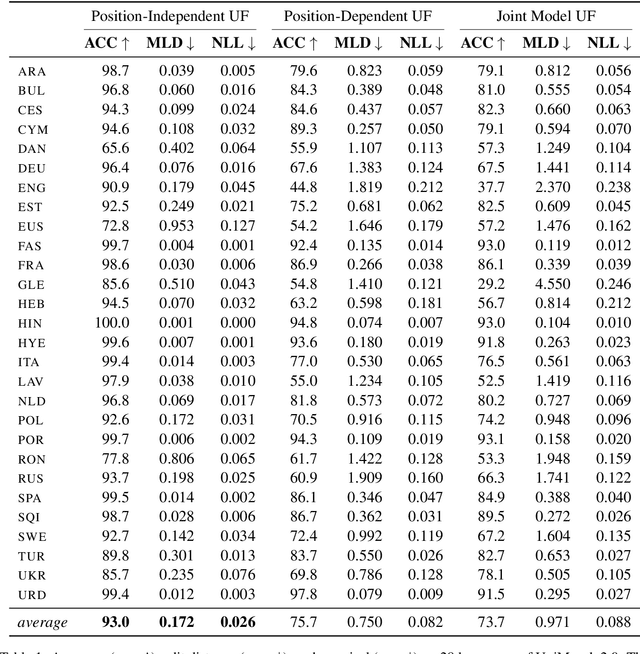
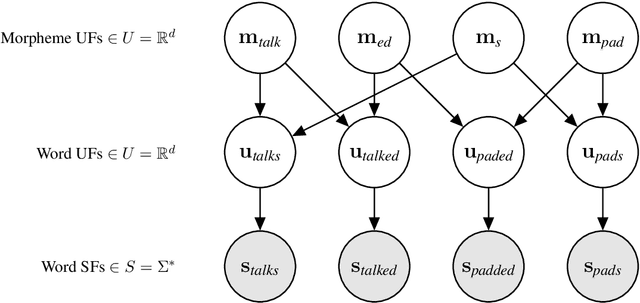
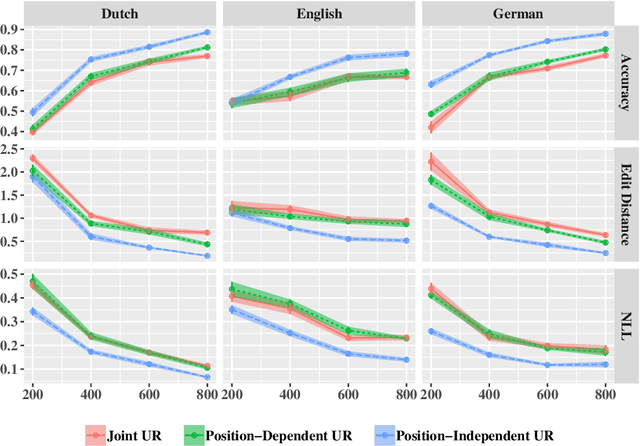
The goal of generative phonology, as formulated by Chomsky and Halle (1968), is to specify a formal system that explains the set of attested phonological strings in a language. Traditionally, a collection of rules (or constraints, in the case of optimality theory) and underlying forms (UF) are posited to work in tandem to generate phonological strings. However, the degree of abstraction of UFs with respect to their concrete realizations is contentious. As the main contribution of our work, we implement the phonological generative system as a neural model differentiable end-to-end, rather than as a set of rules or constraints. Contrary to traditional phonology, in our model, UFs are continuous vectors in $\mathbb{R}^d$, rather than discrete strings. As a consequence, UFs are discovered automatically rather than posited by linguists, and the model can scale to the size of a realistic vocabulary. Moreover, we compare several modes of the generative process, contemplating: i) the presence or absence of an underlying representation in between morphemes and surface forms (SFs); and ii) the conditional dependence or independence of UFs with respect to SFs. We evaluate the ability of each mode to predict attested phonological strings on 2 datasets covering 5 and 28 languages, respectively. The results corroborate two tenets of generative phonology, viz. the necessity for UFs and their independence from SFs. In general, our neural model of generative phonology learns both UFs and SFs automatically and on a large-scale.
Do Explicit Alignments Robustly Improve Multilingual Encoders?
Oct 06, 2020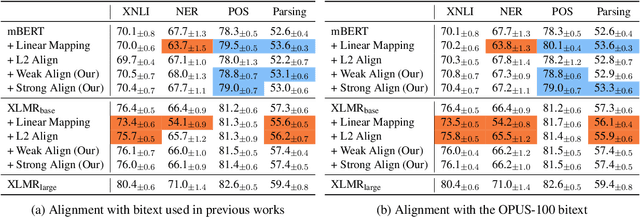
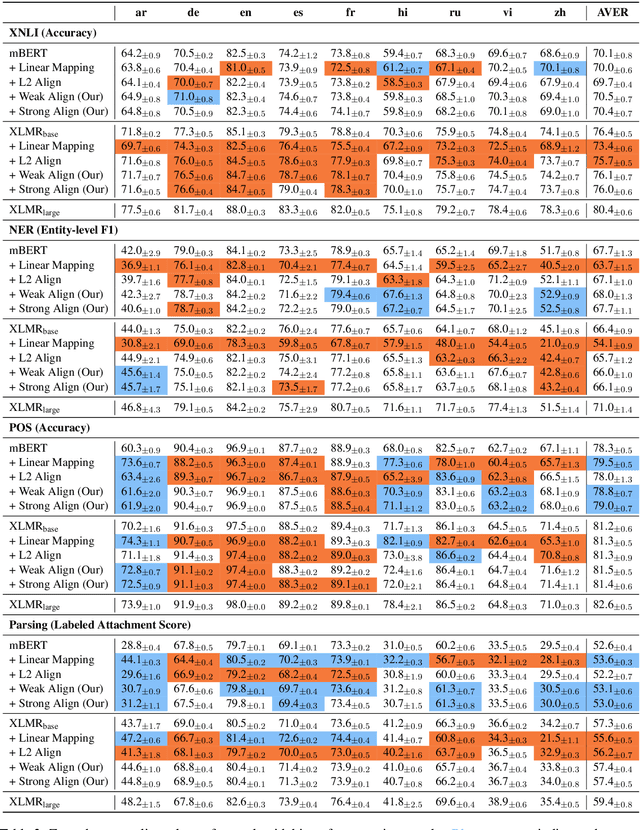
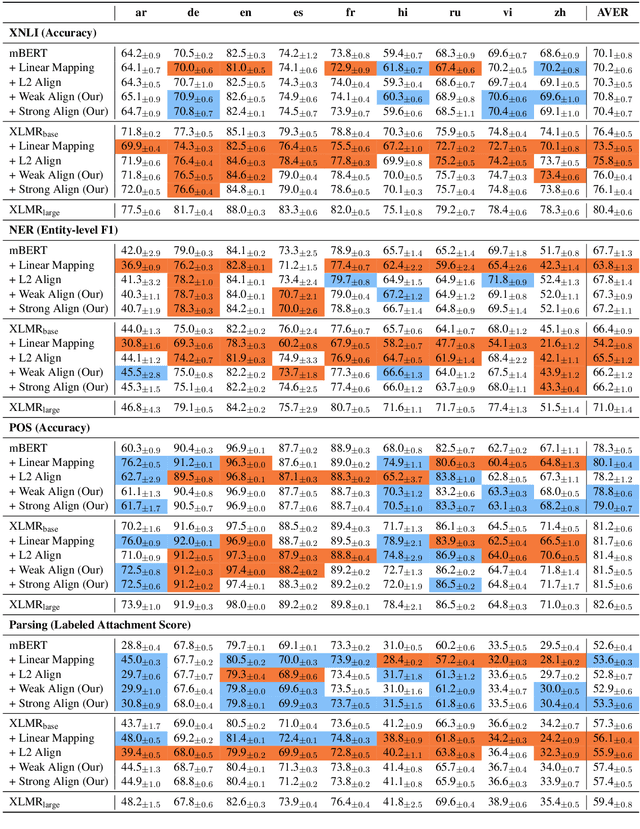
Multilingual BERT (mBERT), XLM-RoBERTa (XLMR) and other unsupervised multilingual encoders can effectively learn cross-lingual representation. Explicit alignment objectives based on bitexts like Europarl or MultiUN have been shown to further improve these representations. However, word-level alignments are often suboptimal and such bitexts are unavailable for many languages. In this paper, we propose a new contrastive alignment objective that can better utilize such signal, and examine whether these previous alignment methods can be adapted to noisier sources of aligned data: a randomly sampled 1 million pair subset of the OPUS collection. Additionally, rather than report results on a single dataset with a single model run, we report the mean and standard derivation of multiple runs with different seeds, on four datasets and tasks. Our more extensive analysis finds that, while our new objective outperforms previous work, overall these methods do not improve performance with a more robust evaluation framework. Furthermore, the gains from using a better underlying model eclipse any benefits from alignment training. These negative results dictate more care in evaluating these methods and suggest limitations in applying explicit alignment objectives.
Which *BERT? A Survey Organizing Contextualized Encoders
Oct 02, 2020Pretrained contextualized text encoders are now a staple of the NLP community. We present a survey on language representation learning with the aim of consolidating a series of shared lessons learned across a variety of recent efforts. While significant advancements continue at a rapid pace, we find that enough has now been discovered, in different directions, that we can begin to organize advances according to common themes. Through this organization, we highlight important considerations when interpreting recent contributions and choosing which model to use.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020
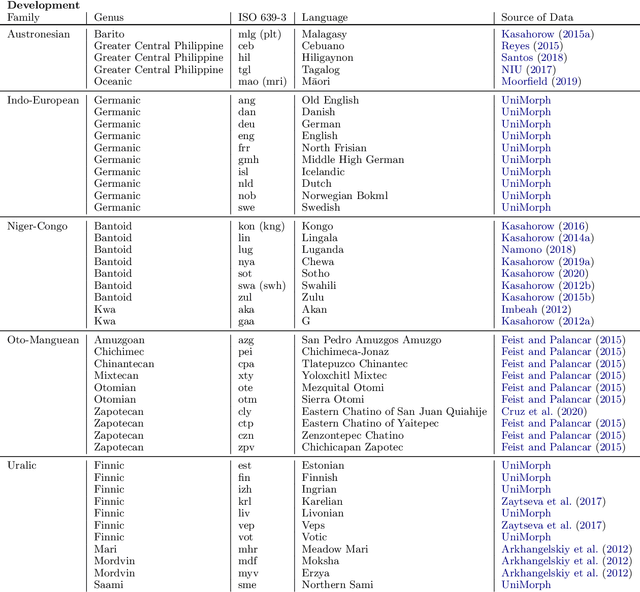
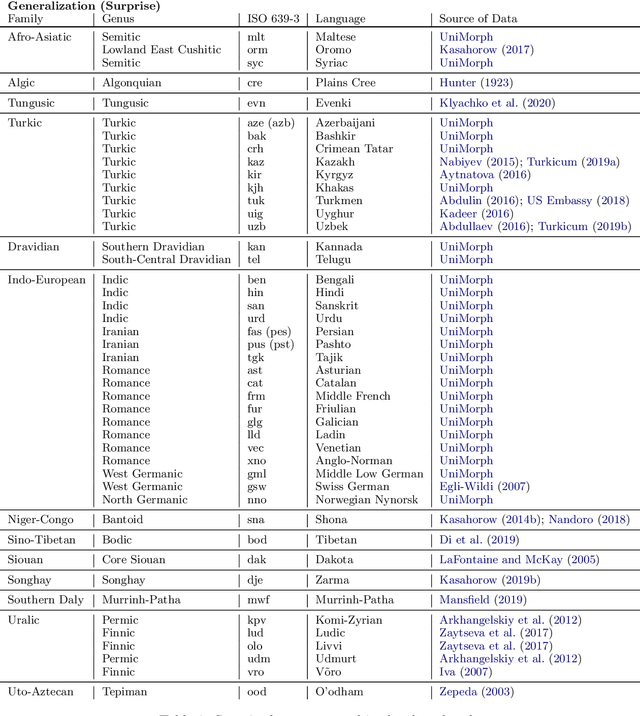
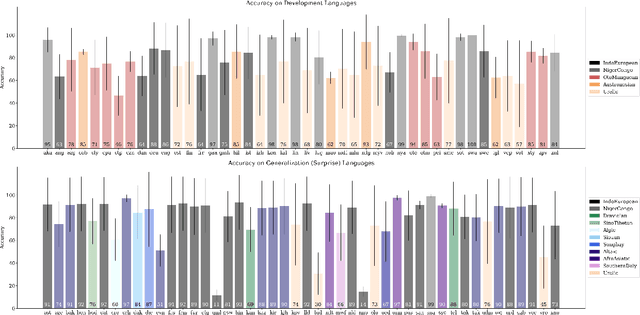
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
Applying the Transformer to Character-level Transduction
May 20, 2020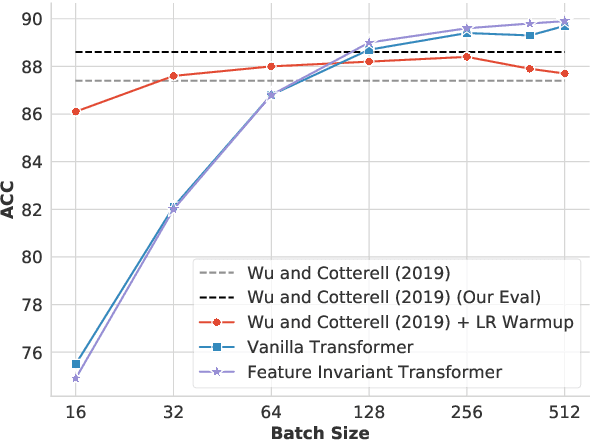
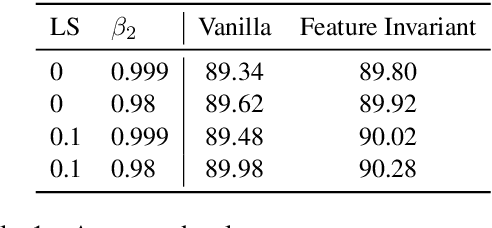

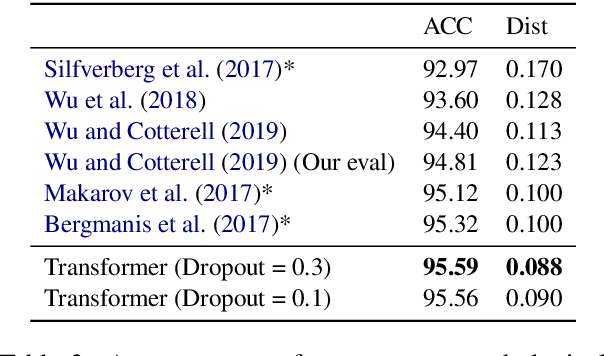
The transformer has been shown to outperform recurrent neural network-based sequence-to-sequence models in various word-level NLP tasks. The model offers other benefits as well: It trains faster and has fewer parameters. Yet for character-level transduction tasks, e.g. morphological inflection generation and historical text normalization, few shows success on outperforming recurrent models with the transformer. In an empirical study, we uncover that, in contrast to recurrent sequence-to-sequence models, the batch size plays a crucial role in the performance of the transformer on character-level tasks, and we show that with a large enough batch size, the transformer does indeed outperform recurrent models. We also introduce a simple technique to handle feature-guided character-level transduction that further improves performance. With these insights, we achieve state-of-the-art performance on morphological inflection and historical text normalization. We also show that the transformer outperforms a strong baseline on two other character-level transduction tasks: grapheme-to-phoneme conversion and transliteration. Code is available at https://github.com/shijie-wu/neural-transducer.
Are All Languages Created Equal in Multilingual BERT?
May 18, 2020
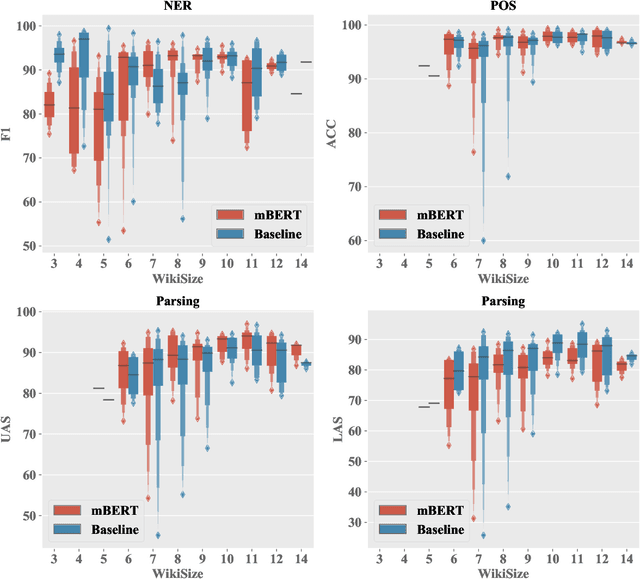
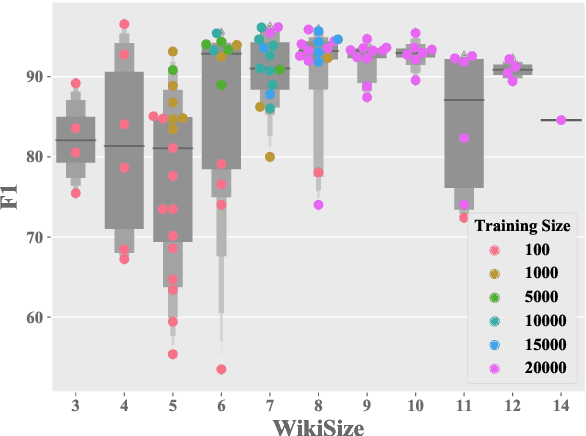
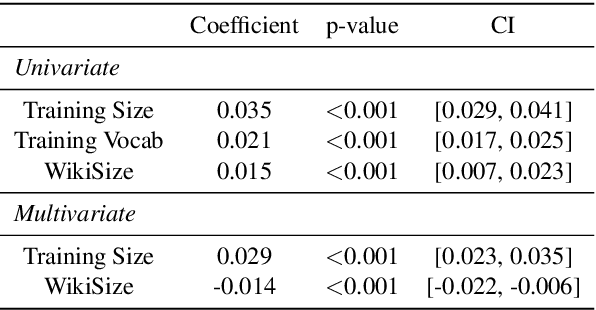
Multilingual BERT (mBERT) trained on 104 languages has shown surprisingly good cross-lingual performance on several NLP tasks, even without explicit cross-lingual signals. However, these evaluations have focused on cross-lingual transfer with high-resource languages, covering only a third of the languages covered by mBERT. We explore how mBERT performs on a much wider set of languages, focusing on the quality of representation for low-resource languages, measured by within-language performance. We consider three tasks: Named Entity Recognition (99 languages), Part-of-speech Tagging, and Dependency Parsing (54 languages each). mBERT does better than or comparable to baselines on high resource languages but does much worse for low resource languages. Furthermore, monolingual BERT models for these languages do even worse. Paired with similar languages, the performance gap between monolingual BERT and mBERT can be narrowed. We find that better models for low resource languages require more efficient pretraining techniques or more data.
The Paradigm Discovery Problem
May 04, 2020
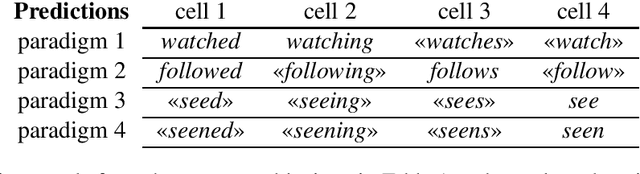
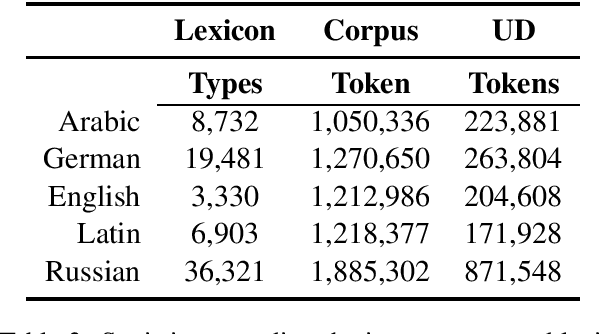
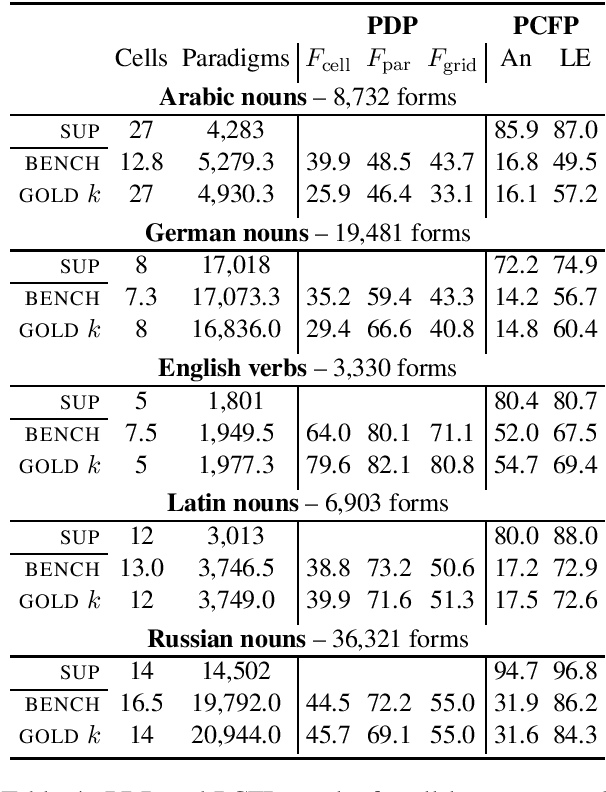
This work treats the paradigm discovery problem (PDP), the task of learning an inflectional morphological system from unannotated sentences. We formalize the PDP and develop evaluation metrics for judging systems. Using currently available resources, we construct datasets for the task. We also devise a heuristic benchmark for the PDP and report empirical results on five diverse languages. Our benchmark system first makes use of word embeddings and string similarity to cluster forms by cell and by paradigm. Then, we bootstrap a neural transducer on top of the clustered data to predict words to realize the empty paradigm slots. An error analysis of our system suggests clustering by cell across different inflection classes is the most pressing challenge for future work. Our code and data are available for public use.
Emerging Cross-lingual Structure in Pretrained Language Models
Nov 10, 2019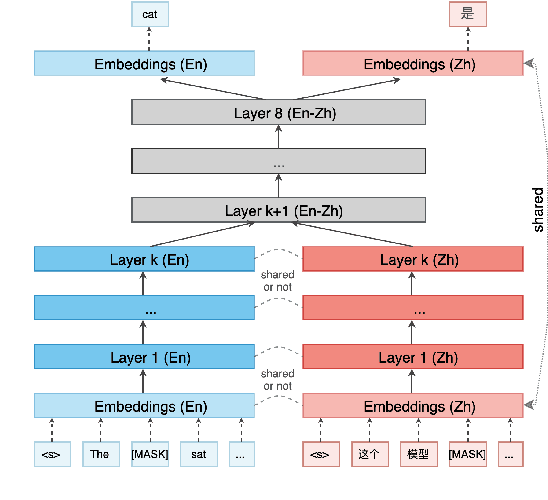
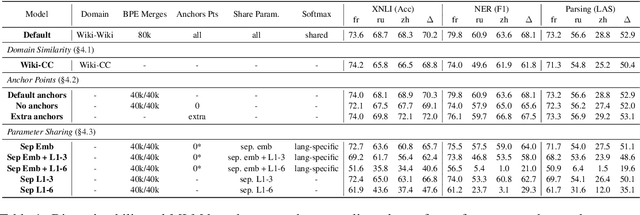
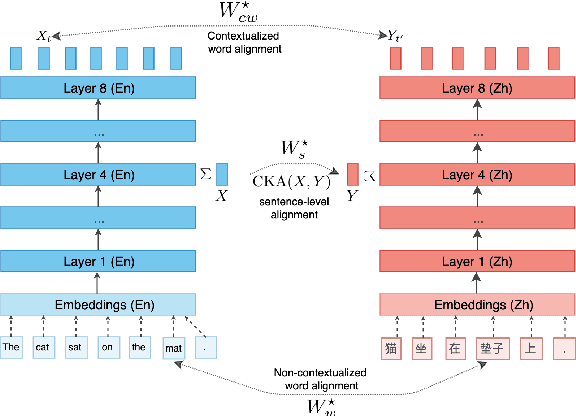
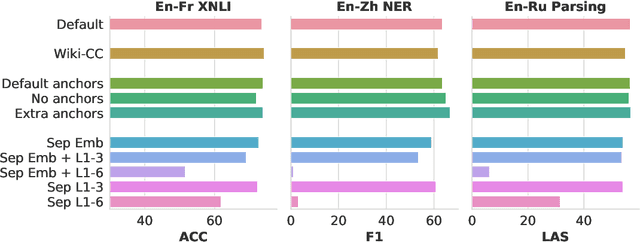
We study the problem of multilingual masked language modeling, i.e. the training of a single model on concatenated text from multiple languages, and present a detailed study of several factors that influence why these models are so effective for cross-lingual transfer. We show, contrary to what was previously hypothesized, that transfer is possible even when there is no shared vocabulary across the monolingual corpora and also when the text comes from very different domains. The only requirement is that there are some shared parameters in the top layers of the multi-lingual encoder. To better understand this result, we also show that representations from independently trained models in different languages can be aligned post-hoc quite effectively, strongly suggesting that, much like for non-contextual word embeddings, there are universal latent symmetries in the learned embedding spaces. For multilingual masked language modeling, these symmetries seem to be automatically discovered and aligned during the joint training process.
The SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
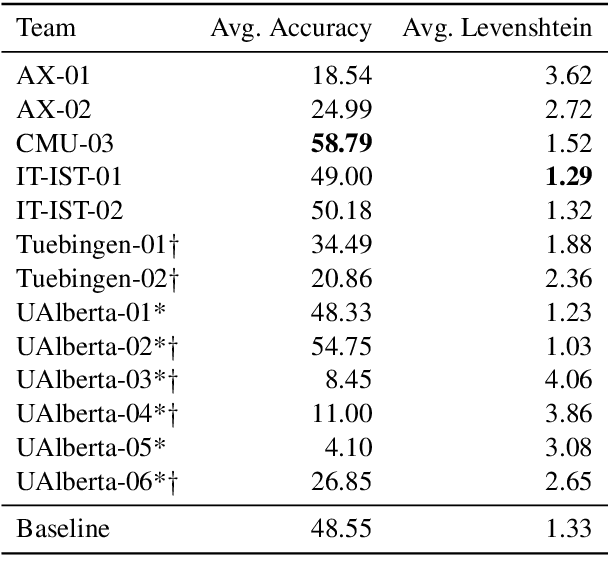
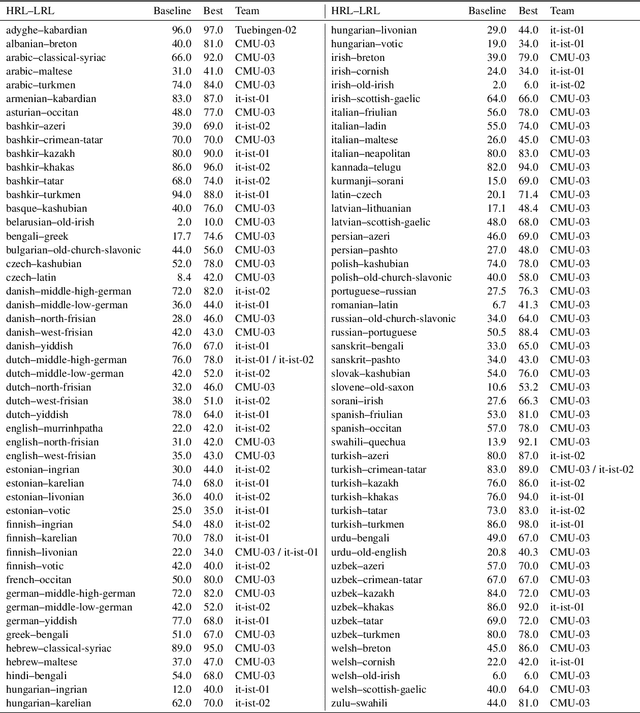
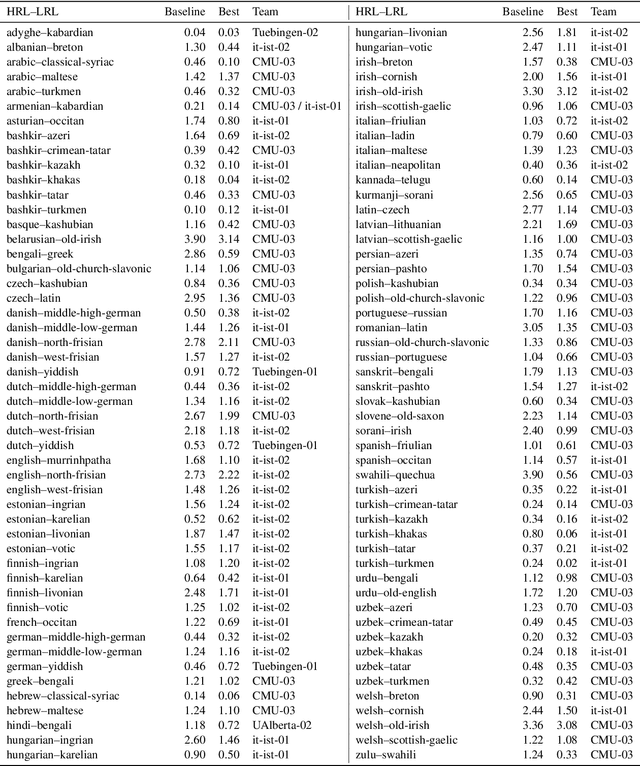
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
Morphological Irregularity Correlates with Frequency
Jun 27, 2019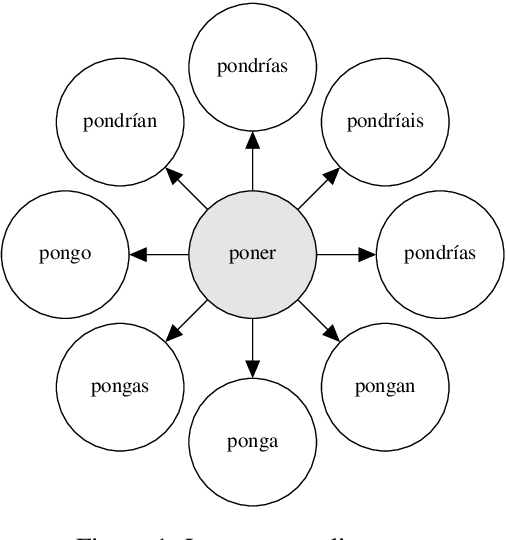


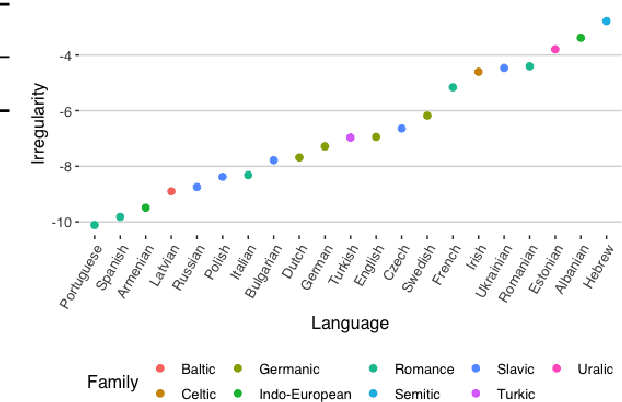
We present a study of morphological irregularity. Following recent work, we define an information-theoretic measure of irregularity based on the predictability of forms in a language. Using a neural transduction model, we estimate this quantity for the forms in 28 languages. We first present several validatory and exploratory analyses of irregularity. We then show that our analyses provide evidence for a correlation between irregularity and frequency: higher frequency items are more likely to be irregular and irregular items are more likely be highly frequent. To our knowledge, this result is the first of its breadth and confirms longstanding proposals from the linguistics literature. The correlation is more robust when aggregated at the level of whole paradigms--providing support for models of linguistic structure in which inflected forms are unified by abstract underlying stems or lexemes. Code is available at https://github.com/shijie-wu/neural-transducer.