 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Continuous Motion for 3D Point Cloud Object Tracking
Mar 14, 2023The task of 3D single object tracking (SOT) with LiDAR point clouds is crucial for various applications, such as autonomous driving and robotics. However, existing approaches have primarily relied on appearance matching or motion modeling within only two successive frames, thereby overlooking the long-range continuous motion property of objects in 3D space. To address this issue, this paper presents a novel approach that views each tracklet as a continuous stream: at each timestamp, only the current frame is fed into the network to interact with multi-frame historical features stored in a memory bank, enabling efficient exploitation of sequential information. To achieve effective cross-frame message passing, a hybrid attention mechanism is designed to account for both long-range relation modeling and local geometric feature extraction. Furthermore, to enhance the utilization of multi-frame features for robust tracking, a contrastive sequence enhancement strategy is designed, which uses ground truth tracklets to augment training sequences and promote discrimination against false positives in a contrastive manner. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art method by significant margins (approximately 8%, 6%, and 12% improvements in the success performance on KITTI, nuScenes, and Waymo, respectively).
Regularized Vector Quantization for Tokenized Image Synthesis
Mar 11, 2023Quantizing images into discrete representations has been a fundamental problem in unified generative modeling. Predominant approaches learn the discrete representation either in a deterministic manner by selecting the best-matching token or in a stochastic manner by sampling from a predicted distribution. However, deterministic quantization suffers from severe codebook collapse and misalignment with inference stage while stochastic quantization suffers from low codebook utilization and perturbed reconstruction objective. This paper presents a regularized vector quantization framework that allows to mitigate above issues effectively by applying regularization from two perspectives. The first is a prior distribution regularization which measures the discrepancy between a prior token distribution and the predicted token distribution to avoid codebook collapse and low codebook utilization. The second is a stochastic mask regularization that introduces stochasticity during quantization to strike a good balance between inference stage misalignment and unperturbed reconstruction objective. In addition, we design a probabilistic contrastive loss which serves as a calibrated metric to further mitigate the perturbed reconstruction objective. Extensive experiments show that the proposed quantization framework outperforms prevailing vector quantization methods consistently across different generative models including auto-regressive models and diffusion models.
FAC: 3D Representation Learning via Foreground Aware Feature Contrast
Mar 11, 2023Contrastive learning has recently demonstrated great potential for unsupervised pre-training in 3D scene understanding tasks. However, most existing work randomly selects point features as anchors while building contrast, leading to a clear bias toward background points that often dominate in 3D scenes. Also, object awareness and foreground-to-background discrimination are neglected, making contrastive learning less effective. To tackle these issues, we propose a general foreground-aware feature contrast (FAC) framework to learn more effective point cloud representations in pre-training. FAC consists of two novel contrast designs to construct more effective and informative contrast pairs. The first is building positive pairs within the same foreground segment where points tend to have the same semantics. The second is that we prevent over-discrimination between 3D segments/objects and encourage foreground-to-background distinctions at the segment level with adaptive feature learning in a Siamese correspondence network, which adaptively learns feature correlations within and across point cloud views effectively. Visualization with point activation maps shows that our contrast pairs capture clear correspondences among foreground regions during pre-training. Quantitative experiments also show that FAC achieves superior knowledge transfer and data efficiency in various downstream 3D semantic segmentation and object detection tasks.
Backdoor Attacks Against Deep Image Compression via Adaptive Frequency Trigger
Feb 28, 2023Recent deep-learning-based compression methods have achieved superior performance compared with traditional approaches. However, deep learning models have proven to be vulnerable to backdoor attacks, where some specific trigger patterns added to the input can lead to malicious behavior of the models. In this paper, we present a novel backdoor attack with multiple triggers against learned image compression models. Motivated by the widely used discrete cosine transform (DCT) in existing compression systems and standards, we propose a frequency-based trigger injection model that adds triggers in the DCT domain. In particular, we design several attack objectives for various attacking scenarios, including: 1) attacking compression quality in terms of bit-rate and reconstruction quality; 2) attacking task-driven measures, such as down-stream face recognition and semantic segmentation. Moreover, a novel simple dynamic loss is designed to balance the influence of different loss terms adaptively, which helps achieve more efficient training. Extensive experiments show that with our trained trigger injection models and simple modification of encoder parameters (of the compression model), the proposed attack can successfully inject several backdoors with corresponding triggers in a single image compression model.
DETR4D: Direct Multi-View 3D Object Detection with Sparse Attention
Dec 15, 20223D object detection with surround-view images is an essential task for autonomous driving. In this work, we propose DETR4D, a Transformer-based framework that explores sparse attention and direct feature query for 3D object detection in multi-view images. We design a novel projective cross-attention mechanism for query-image interaction to address the limitations of existing methods in terms of geometric cue exploitation and information loss for cross-view objects. In addition, we introduce a heatmap generation technique that bridges 3D and 2D spaces efficiently via query initialization. Furthermore, unlike the common practice of fusing intermediate spatial features for temporal aggregation, we provide a new perspective by introducing a novel hybrid approach that performs cross-frame fusion over past object queries and image features, enabling efficient and robust modeling of temporal information. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of the proposed DETR4D.
Domain Adaptive Scene Text Detection via Subcategorization
Dec 01, 2022Most existing scene text detectors require large-scale training data which cannot scale well due to two major factors: 1) scene text images often have domain-specific distributions; 2) collecting large-scale annotated scene text images is laborious. We study domain adaptive scene text detection, a largely neglected yet very meaningful task that aims for optimal transfer of labelled scene text images while handling unlabelled images in various new domains. Specifically, we design SCAST, a subcategory-aware self-training technique that mitigates the network overfitting and noisy pseudo labels in domain adaptive scene text detection effectively. SCAST consists of two novel designs. For labelled source data, it introduces pseudo subcategories for both foreground texts and background stuff which helps train more generalizable source models with multi-class detection objectives. For unlabelled target data, it mitigates the network overfitting by co-regularizing the binary and subcategory classifiers trained in the source domain. Extensive experiments show that SCAST achieves superior detection performance consistently across multiple public benchmarks, and it also generalizes well to other domain adaptive detection tasks such as vehicle detection.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Aug 24, 2022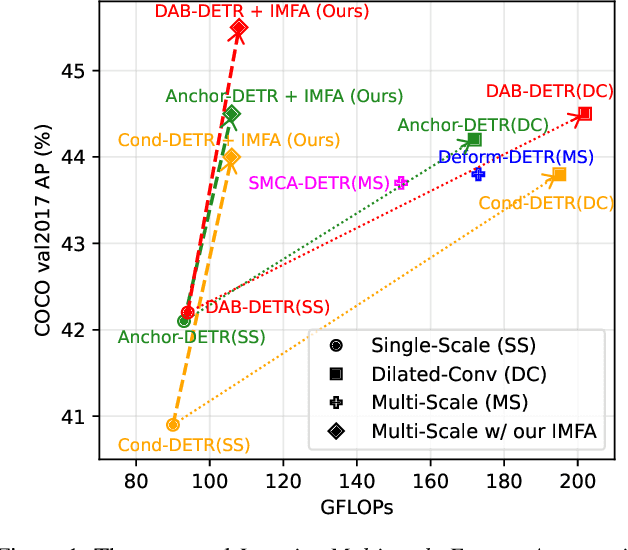
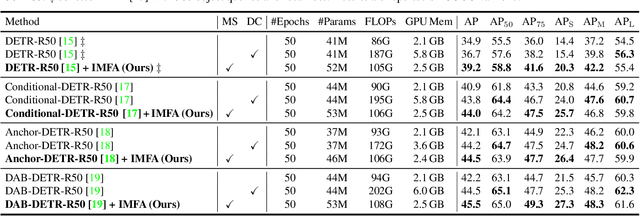
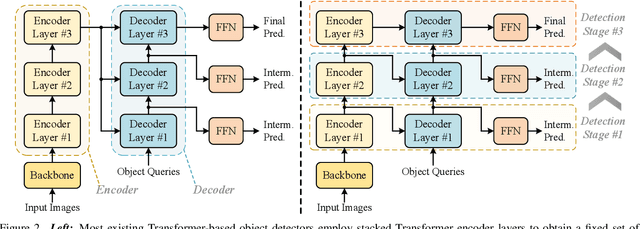
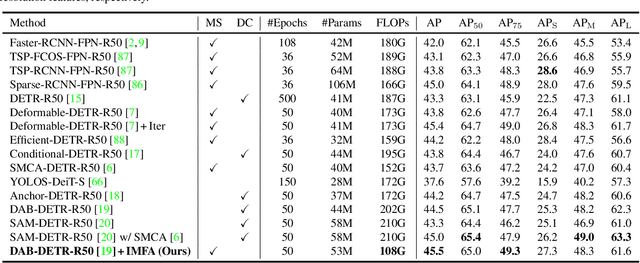
Multi-scale features have been proven highly effective for object detection, and most ConvNet-based object detectors adopt Feature Pyramid Network (FPN) as a basic component for exploiting multi-scale features. However, for the recently proposed Transformer-based object detectors, directly incorporating multi-scale features leads to prohibitive computational overhead due to the high complexity of the attention mechanism for processing high-resolution features. This paper presents Iterative Multi-scale Feature Aggregation (IMFA) -- a generic paradigm that enables the efficient use of multi-scale features in Transformer-based object detectors. The core idea is to exploit sparse multi-scale features from just a few crucial locations, and it is achieved with two novel designs. First, IMFA rearranges the Transformer encoder-decoder pipeline so that the encoded features can be iteratively updated based on the detection predictions. Second, IMFA sparsely samples scale-adaptive features for refined detection from just a few keypoint locations under the guidance of prior detection predictions. As a result, the sampled multi-scale features are sparse yet still highly beneficial for object detection. Extensive experiments show that the proposed IMFA boosts the performance of multiple Transformer-based object detectors significantly yet with slight computational overhead. Project page: https://github.com/ZhangGongjie/IMFA.
Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022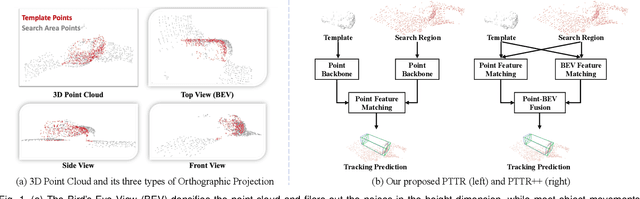
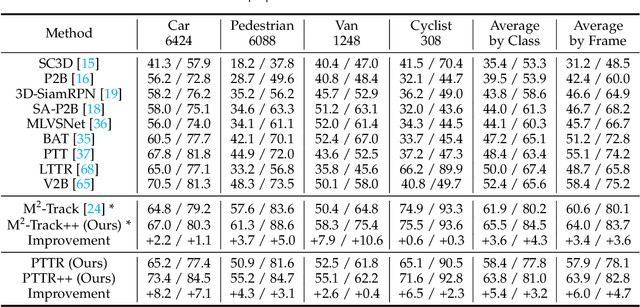
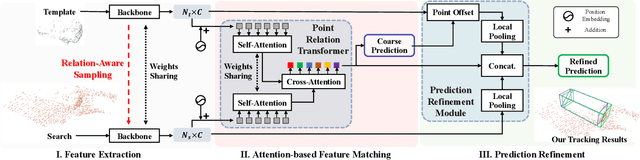
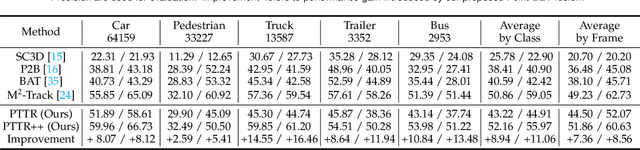
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.
Latent Multi-Relation Reasoning for GAN-Prior based Image Super-Resolution
Aug 04, 2022



Recently, single image super-resolution (SR) under large scaling factors has witnessed impressive progress by introducing pre-trained generative adversarial networks (GANs) as priors. However, most GAN-Priors based SR methods are constrained by an attribute disentanglement problem in inverted latent codes which directly leads to mismatches of visual attributes in the generator layers and further degraded reconstruction. In addition, stochastic noises fed to the generator are employed for unconditional detail generation, which tends to produce unfaithful details that compromise the fidelity of the generated SR image. We design LAREN, a LAtent multi-Relation rEasoNing technique that achieves superb large-factor SR through graph-based multi-relation reasoning in latent space. LAREN consists of two innovative designs. The first is graph-based disentanglement that constructs a superior disentangled latent space via hierarchical multi-relation reasoning. The second is graph-based code generation that produces image-specific codes progressively via recursive relation reasoning which enables prior GANs to generate desirable image details. Extensive experiments show that LAREN achieves superior large-factor image SR and outperforms the state-of-the-art consistently across multiple benchmarks.
TransPillars: Coarse-to-Fine Aggregation for Multi-Frame 3D Object Detection
Aug 04, 2022



3D object detection using point clouds has attracted increasing attention due to its wide applications in autonomous driving and robotics. However, most existing studies focus on single point cloud frames without harnessing the temporal information in point cloud sequences. In this paper, we design TransPillars, a novel transformer-based feature aggregation technique that exploits temporal features of consecutive point cloud frames for multi-frame 3D object detection. TransPillars aggregates spatial-temporal point cloud features from two perspectives. First, it fuses voxel-level features directly from multi-frame feature maps instead of pooled instance features to preserve instance details with contextual information that are essential to accurate object localization. Second, it introduces a hierarchical coarse-to-fine strategy to fuse multi-scale features progressively to effectively capture the motion of moving objects and guide the aggregation of fine features. Besides, a variant of deformable transformer is introduced to improve the effectiveness of cross-frame feature matching. Extensive experiments show that our proposed TransPillars achieves state-of-art performance as compared to existing multi-frame detection approaches. Code will be released.