 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Dec 28, 2023Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks. It improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance -- all without the need for manual training labels.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023



The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.
GSVA: Generalized Segmentation via Multimodal Large Language Models
Dec 15, 2023



Generalized Referring Expression Segmentation (GRES) extends the scope of classic RES to referring to multiple objects in one expression or identifying the empty targets absent in the image. GRES poses challenges in modeling the complex spatial relationships of the instances in the image and identifying non-existing referents. Recently, Multimodal Large Language Models (MLLMs) have shown tremendous progress in these complicated vision-language tasks. Connecting Large Language Models (LLMs) and vision models, MLLMs are proficient in understanding contexts with visual inputs. Among them, LISA, as a representative, adopts a special [SEG] token to prompt a segmentation mask decoder, e.g., SAM, to enable MLLMs in the RES task. However, existing solutions to of GRES remain unsatisfactory since current segmentation MLLMs cannot properly handle the cases where users might reference multiple subjects in a singular prompt or provide descriptions incongruent with any image target. In this paper, we propose Generalized Segmentation Vision Assistant (GSVA) to address this gap. Specifically, GSVA reuses the [SEG] token to prompt the segmentation model towards supporting multiple mask references simultaneously and innovatively learns to generate a [REJ] token to reject the null targets explicitly. Experiments validate GSVA's efficacy in resolving the GRES issue, marking a notable enhancement and setting a new record on the GRES benchmark gRefCOCO dataset. GSVA also proves effective across various classic referring expression segmentation and comprehension tasks.
Smooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models
Dec 07, 2023



Recently, diffusion models have made remarkable progress in text-to-image (T2I) generation, synthesizing images with high fidelity and diverse contents. Despite this advancement, latent space smoothness within diffusion models remains largely unexplored. Smooth latent spaces ensure that a perturbation on an input latent corresponds to a steady change in the output image. This property proves beneficial in downstream tasks, including image interpolation, inversion, and editing. In this work, we expose the non-smoothness of diffusion latent spaces by observing noticeable visual fluctuations resulting from minor latent variations. To tackle this issue, we propose Smooth Diffusion, a new category of diffusion models that can be simultaneously high-performing and smooth. Specifically, we introduce Step-wise Variation Regularization to enforce the proportion between the variations of an arbitrary input latent and that of the output image is a constant at any diffusion training step. In addition, we devise an interpolation standard deviation (ISTD) metric to effectively assess the latent space smoothness of a diffusion model. Extensive quantitative and qualitative experiments demonstrate that Smooth Diffusion stands out as a more desirable solution not only in T2I generation but also across various downstream tasks. Smooth Diffusion is implemented as a plug-and-play Smooth-LoRA to work with various community models. Code is available at https://github.com/SHI-Labs/Smooth-Diffusion.
Train Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
Understanding, Predicting and Better Resolving Q-Value Divergence in Offline-RL
Oct 06, 2023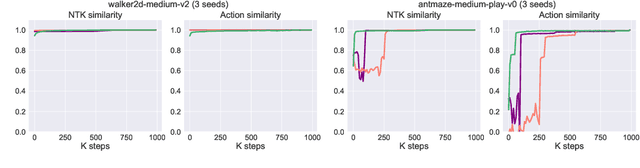
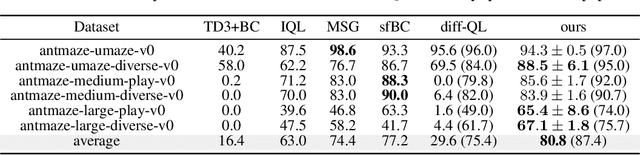
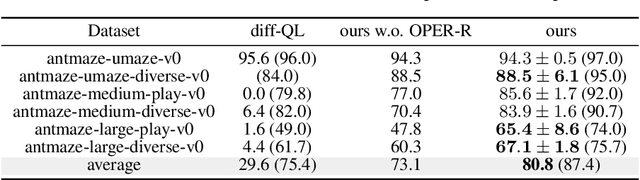
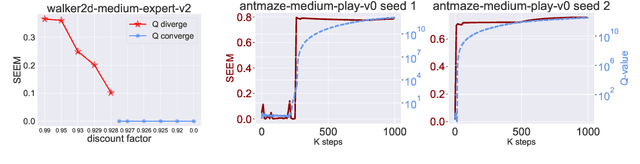
The divergence of the Q-value estimation has been a prominent issue in offline RL, where the agent has no access to real dynamics. Traditional beliefs attribute this instability to querying out-of-distribution actions when bootstrapping value targets. Though this issue can be alleviated with policy constraints or conservative Q estimation, a theoretical understanding of the underlying mechanism causing the divergence has been absent. In this work, we aim to thoroughly comprehend this mechanism and attain an improved solution. We first identify a fundamental pattern, self-excitation, as the primary cause of Q-value estimation divergence in offline RL. Then, we propose a novel Self-Excite Eigenvalue Measure (SEEM) metric based on Neural Tangent Kernel (NTK) to measure the evolving property of Q-network at training, which provides an intriguing explanation of the emergence of divergence. For the first time, our theory can reliably decide whether the training will diverge at an early stage, and even predict the order of the growth for the estimated Q-value, the model's norm, and the crashing step when an SGD optimizer is used. The experiments demonstrate perfect alignment with this theoretic analysis. Building on our insights, we propose to resolve divergence from a novel perspective, namely improving the model's architecture for better extrapolating behavior. Through extensive empirical studies, we identify LayerNorm as a good solution to effectively avoid divergence without introducing detrimental bias, leading to superior performance. Experimental results prove that it can still work in some most challenging settings, i.e. using only 1 transitions of the dataset, where all previous methods fail. Moreover, it can be easily plugged into modern offline RL methods and achieve SOTA results on many challenging tasks. We also give unique insights into its effectiveness.
* 31 pages, 20 figures
Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
Oct 06, 2023



Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs' potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a "Game-of-Thoughts". Inspired by the efficacy of humans' recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs' ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others' mental states, and the second-order involves understanding how others perceive the agent's mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.
Facilitating Battery Swapping Services for Freight Trucks with Spatial-Temporal Demand Prediction
Oct 01, 2023



Electrifying heavy-duty trucks offers a substantial opportunity to curtail carbon emissions, advancing toward a carbon-neutral future. However, the inherent challenges of limited battery energy and the sheer weight of heavy-duty trucks lead to reduced mileage and prolonged charging durations. Consequently, battery-swapping services emerge as an attractive solution for these trucks. This paper employs a two-fold approach to investigate the potential and enhance the efficacy of such services. Firstly, spatial-temporal demand prediction models are adopted to predict the traffic patterns for the upcoming hours. Subsequently, the prediction guides an optimization module for efficient battery allocation and deployment. Analyzing the heavy-duty truck data on a highway network spanning over 2,500 miles, our model and analysis underscore the value of prediction/machine learning in facilitating future decision-makings. In particular, we find that the initial phase of implementing battery-swapping services favors mobile battery-swapping stations, but as the system matures, fixed-location stations are preferred.
Hundreds Guide Millions: Adaptive Offline Reinforcement Learning with Expert Guidance
Sep 04, 2023



Offline reinforcement learning (RL) optimizes the policy on a previously collected dataset without any interactions with the environment, yet usually suffers from the distributional shift problem. To mitigate this issue, a typical solution is to impose a policy constraint on a policy improvement objective. However, existing methods generally adopt a ``one-size-fits-all'' practice, i.e., keeping only a single improvement-constraint balance for all the samples in a mini-batch or even the entire offline dataset. In this work, we argue that different samples should be treated with different policy constraint intensities. Based on this idea, a novel plug-in approach named Guided Offline RL (GORL) is proposed. GORL employs a guiding network, along with only a few expert demonstrations, to adaptively determine the relative importance of the policy improvement and policy constraint for every sample. We theoretically prove that the guidance provided by our method is rational and near-optimal. Extensive experiments on various environments suggest that GORL can be easily installed on most offline RL algorithms with statistically significant performance improvements.
Leveraging Reward Consistency for Interpretable Feature Discovery in Reinforcement Learning
Sep 04, 2023The black-box nature of deep reinforcement learning (RL) hinders them from real-world applications. Therefore, interpreting and explaining RL agents have been active research topics in recent years. Existing methods for post-hoc explanations usually adopt the action matching principle to enable an easy understanding of vision-based RL agents. In this paper, it is argued that the commonly used action matching principle is more like an explanation of deep neural networks (DNNs) than the interpretation of RL agents. It may lead to irrelevant or misplaced feature attribution when different DNNs' outputs lead to the same rewards or different rewards result from the same outputs. Therefore, we propose to consider rewards, the essential objective of RL agents, as the essential objective of interpreting RL agents as well. To ensure reward consistency during interpretable feature discovery, a novel framework (RL interpreting RL, denoted as RL-in-RL) is proposed to solve the gradient disconnection from actions to rewards. We verify and evaluate our method on the Atari 2600 games as well as Duckietown, a challenging self-driving car simulator environment. The results show that our method manages to keep reward (or return) consistency and achieves high-quality feature attribution. Further, a series of analytical experiments validate our assumption of the action matching principle's limitations.