 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-clip Aggregation for Video Person Re-identification
May 05, 2019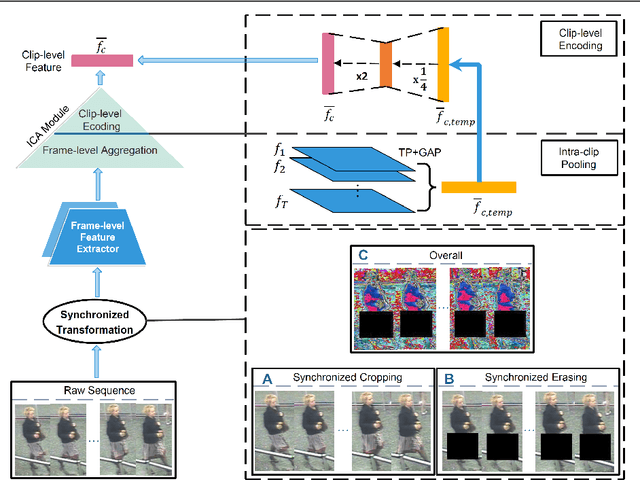
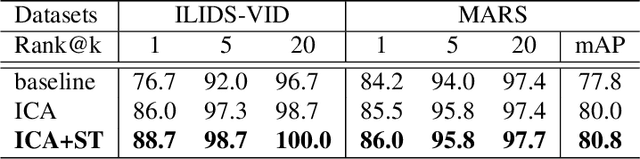
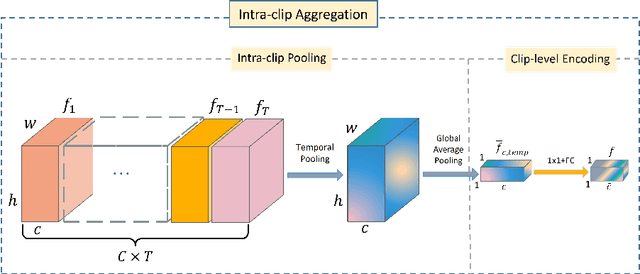
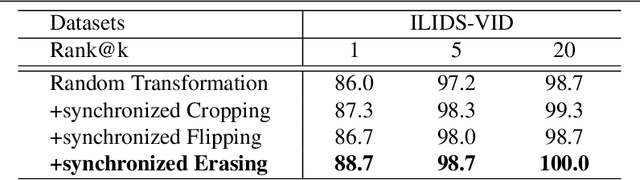
Video-based person re-id has drawn much attention in recent years due to its prospective applications in video surveillance. Most existing methods concentrate on how to represent discriminative clip-level features. Moreover, clip-level data augmentation is also important, especially for temporal aggregation task. Inconsistent intra-clip augmentation will collapse inter-frame alignment, thus bringing in additional noise. To tackle the above-motioned problems, we design a novel framework for video-based person re-id, which consists of two main modules: Synchronized Transformation (ST) and Intra-clip Aggregation (ICA). The former module augments intra-clip frames with the same probability and the same operation, while the latter leverages two-level intra-clip encoding to generate more discriminative clip-level features. To confirm the advantage of synchronized transformation, we conduct ablation study with different synchronized transformation scheme. We also perform cross-dataset experiment to better understand the generality of our method. Extensive experiments on three benchmark datasets demonstrate that our framework outperforming the most of recent state-of-the-art methods.
HAR-Net: Joint Learning of Hybrid Attention for Single-stage Object Detection
Apr 25, 2019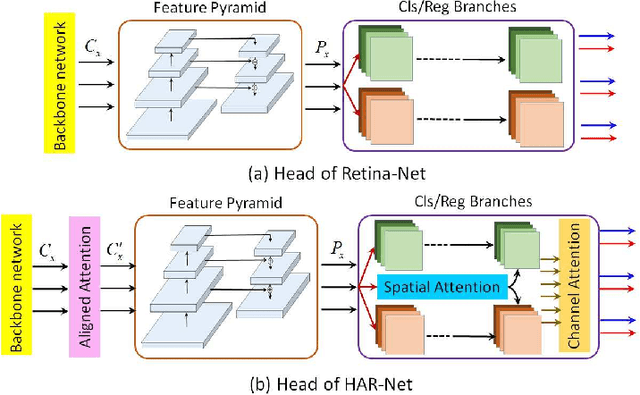
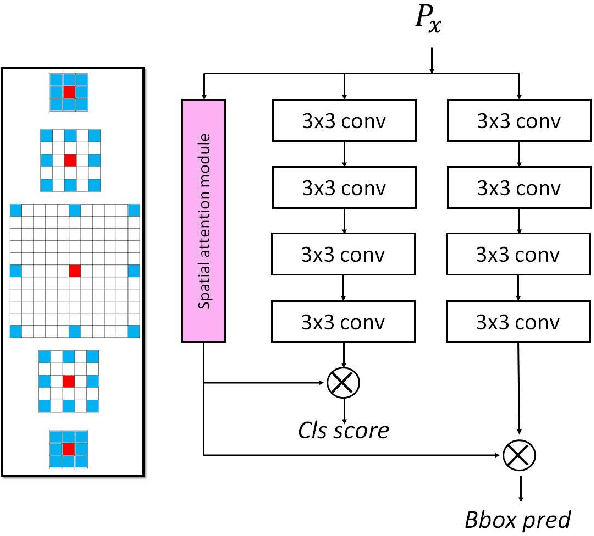
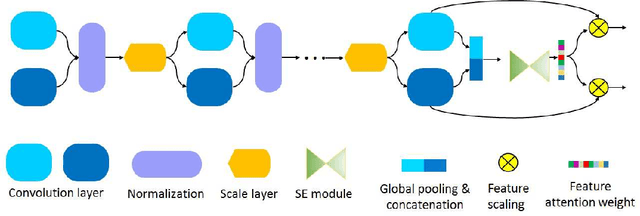

Object detection has been a challenging task in computer vision. Although significant progress has been made in object detection with deep neural networks, the attention mechanism is far from development. In this paper, we propose the hybrid attention mechanism for single-stage object detection. First, we present the modules of spatial attention, channel attention and aligned attention for single-stage object detection. In particular, stacked dilated convolution layers with symmetrically fixed rates are constructed to learn spatial attention. The channel attention is proposed with the cross-level group normalization and squeeze-and-excitation module. Aligned attention is constructed with organized deformable filters. Second, the three kinds of attention are unified to construct the hybrid attention mechanism. We then embed the hybrid attention into Retina-Net and propose the efficient single-stage HAR-Net for object detection. The attention modules and the proposed HAR-Net are evaluated on the COCO detection dataset. Experiments demonstrate that hybrid attention can significantly improve the detection accuracy and the HAR-Net can achieve the state-of-the-art 45.8\% mAP, outperform existing single-stage object detectors.
Linkage Based Face Clustering via Graph Convolution Network
Apr 08, 2019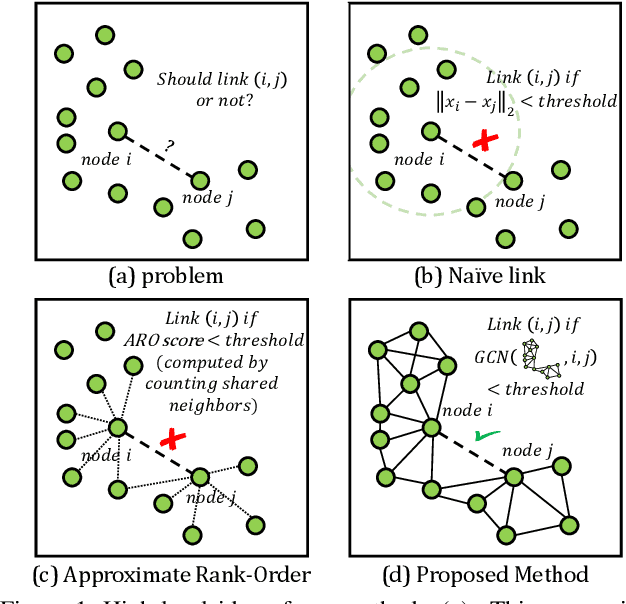
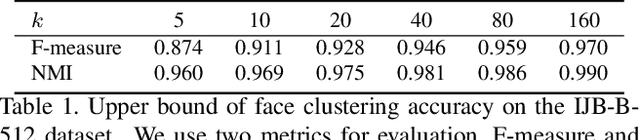
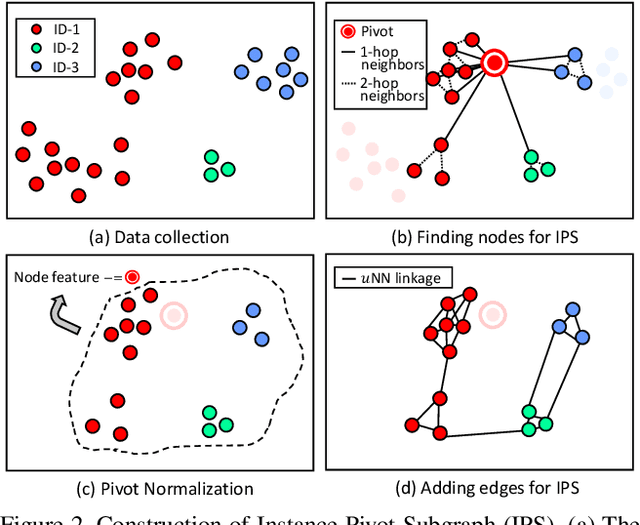
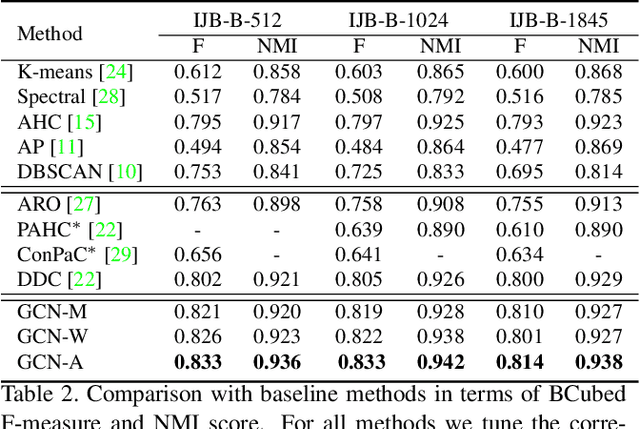
In this paper, we present an accurate and scalable approach to the face clustering task. We aim at grouping a set of faces by their potential identities. We formulate this task as a link prediction problem: a link exists between two faces if they are of the same identity. The key idea is that we find the local context in the feature space around an instance (face) contains rich information about the linkage relationship between this instance and its neighbors. By constructing sub-graphs around each instance as input data, which depict the local context, we utilize the graph convolution network (GCN) to perform reasoning and infer the likelihood of linkage between pairs in the sub-graphs. Experiments show that our method is more robust to the complex distribution of faces than conventional methods, yielding favorably comparable results to state-of-the-art methods on standard face clustering benchmarks, and is scalable to large datasets. Furthermore, we show that the proposed method does not need the number of clusters as prior, is aware of noises and outliers, and can be extended to a multi-view version for more accurate clustering accuracy.
Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification
Apr 01, 2019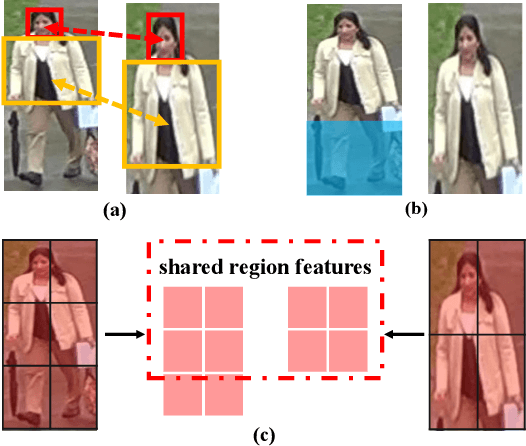
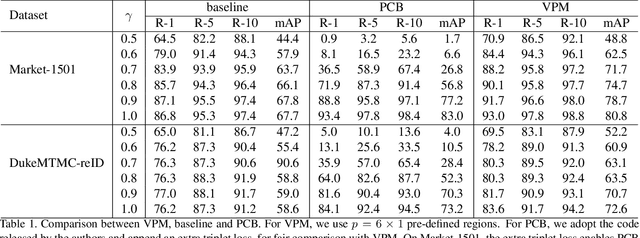
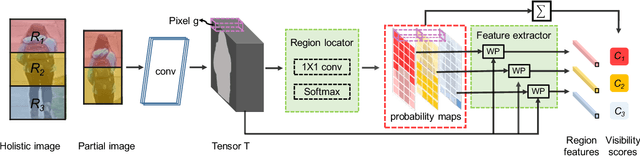
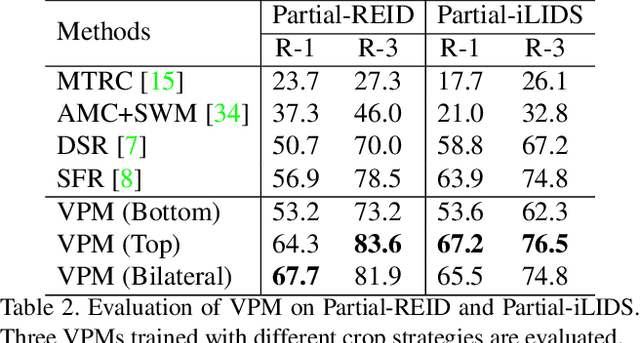
This paper considers a realistic problem in person re-identification (re-ID) task, i.e., partial re-ID. Under partial re-ID scenario, the images may contain a partial observation of a pedestrian. If we directly compare a partial pedestrian image with a holistic one, the extreme spatial misalignment significantly compromises the discriminative ability of the learned representation. We propose a Visibility-aware Part Model (VPM), which learns to perceive the visibility of regions through self-supervision. The visibility awareness allows VPM to extract region-level features and compare two images with focus on their shared regions (which are visible on both images). VPM gains two-fold benefit toward higher accuracy for partial re-ID. On the one hand, compared with learning a global feature, VPM learns region-level features and benefits from fine-grained information. On the other hand, with visibility awareness, VPM is capable to estimate the shared regions between two images and thus suppresses the spatial misalignment. Experimental results confirm that our method significantly improves the learned representation and the achieved accuracy is on par with the state of the art.
Intention Oriented Image Captions with Guiding Objects
Nov 19, 2018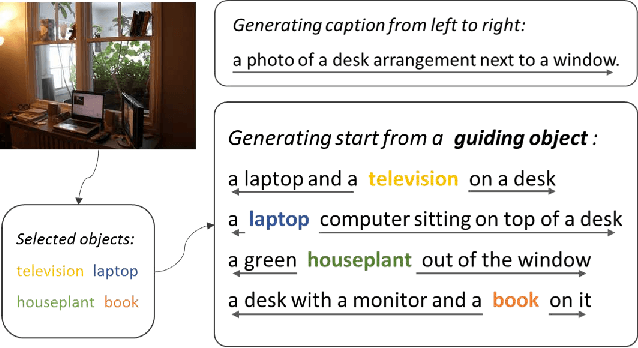
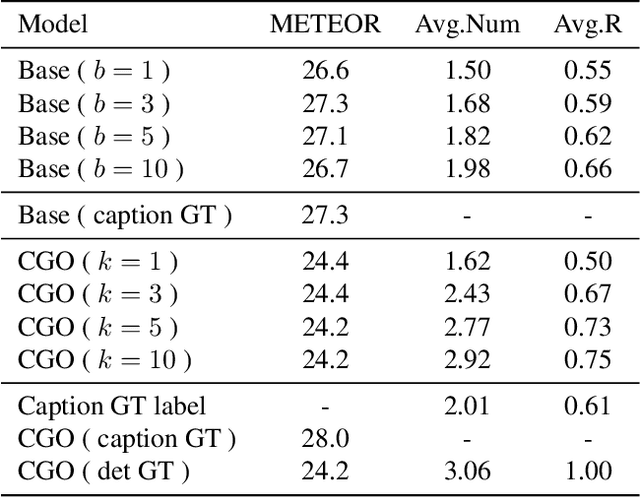
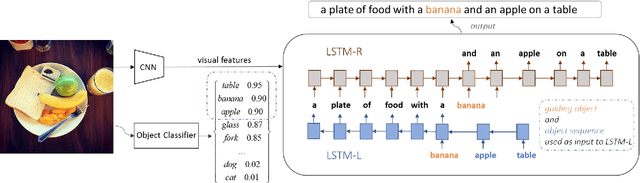
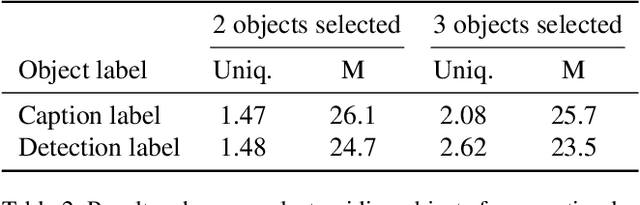
Although existing image caption models can produce promising results using recurrent neural networks (RNNs), it is difficult to guarantee that an object we care about is contained in generated descriptions, for example in the case that the object is inconspicuous in image. Problems become even harder when these objects did not appear in training stage. In this paper, we propose a novel approach for generating image captions with guiding objects (CGO). The CGO constrains the model to involve a human-concerned object, when the object is in the image, in the generated description while maintaining fluency. Instead of generating the sequence from left to right, we start description with a selected object and generate other parts of the sequence based on this object. To achieve this, we design a novel framework combining two LSTMs in opposite directions. We demonstrate the characteristics of our method on MSCOCO to generate descriptions for each detected object in images. With CGO, we can extend the ability of description to the objects being neglected in image caption labels and provide a set of more comprehensive and diverse descriptions for an image. CGO shows obvious advantages when applied to the task of describing novel objects. We show experiment results on both MSCOCO and ImageNet datasets. Evaluations show that our method outperforms the state-of-the-art models in the task with average F1 75.8, leading to better descriptions in terms of both content accuracy and fluency.
Query Adaptive Late Fusion for Image Retrieval
Oct 31, 2018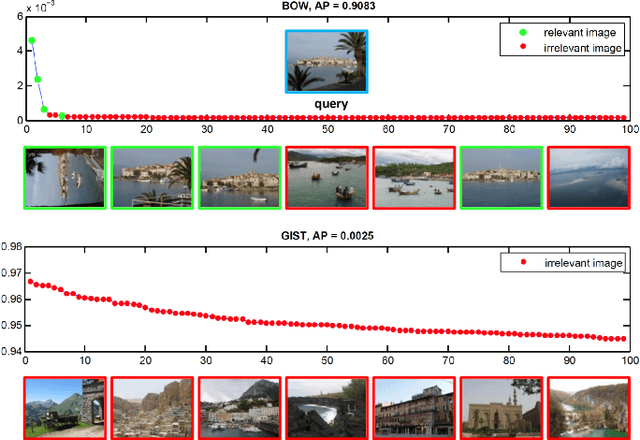
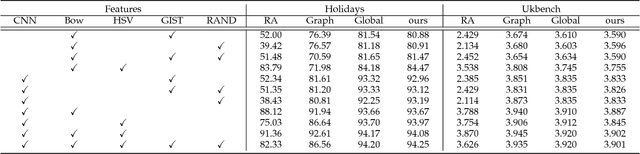
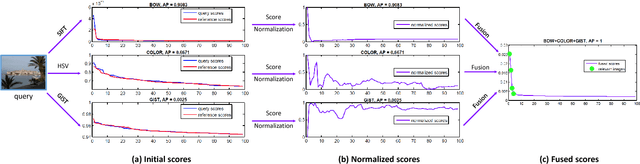
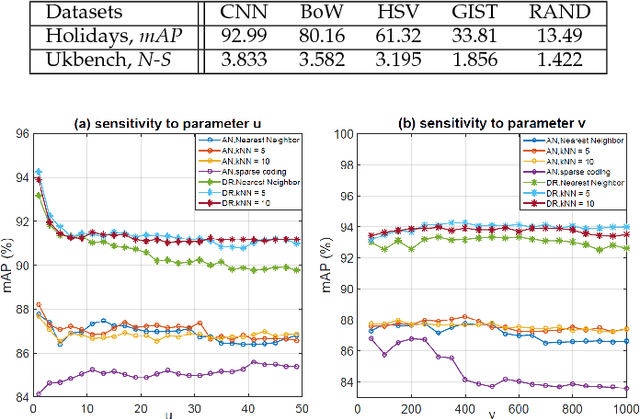
Feature fusion is a commonly used strategy in image retrieval tasks, which aggregates the matching responses of multiple visual features. Feasible sets of features can be either descriptors (SIFT, HSV) for an entire image or the same descriptor for different local parts (face, body). Ideally, the to-be-fused heterogeneous features are pre-assumed to be discriminative and complementary to each other. However, the effectiveness of different features varies dramatically according to different queries. That is to say, for some queries, a feature may be neither discriminative nor complementary to existing ones, while for other queries, the feature suffices. As a result, it is important to estimate the effectiveness of features in a query-adaptive manner. To this end, this article proposes a new late fusion scheme at the score level. We base our method on the observation that the sorted score curves contain patterns that describe their effectiveness. For example, an "L"-shaped curve indicates that the feature is discriminative while a gradually descending curve suggests a bad feature. As such, this paper introduces a query-adaptive late fusion pipeline. In the hand-crafted version, it can be an unsupervised approach to tasks like particular object retrieval. In the learning version, it can also be applied to supervised tasks like person recognition and pedestrian retrieval, based on a trainable neural module. Extensive experiments are conducted on two object retrieval datasets and one person recognition dataset. We show that our method is able to highlight the good features and suppress the bad ones, is resilient to distractor features, and achieves very competitive retrieval accuracy compared with the state of the art. In an additional person re-identification dataset, the application scope and limitation of the proposed method are studied.
Fast and Accurate Online Video Object Segmentation via Tracking Parts
Jun 06, 2018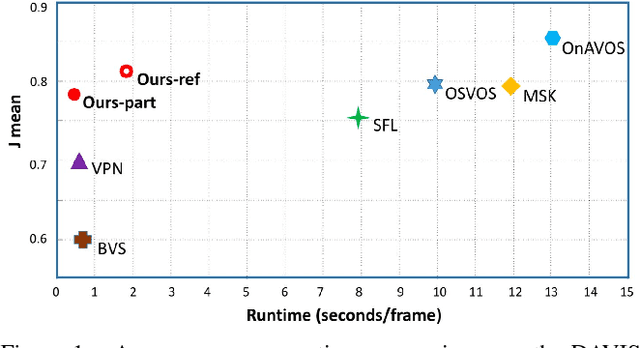
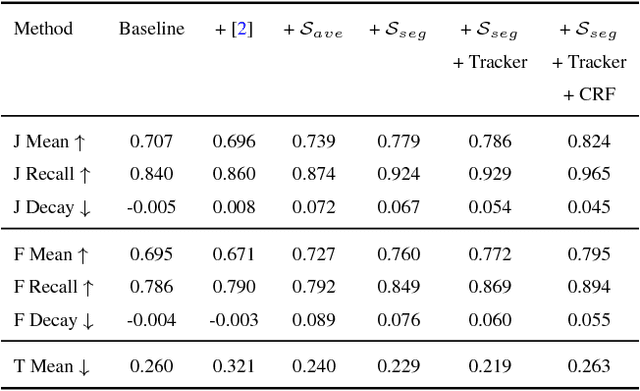
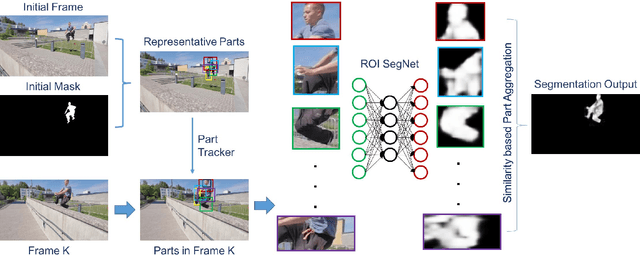
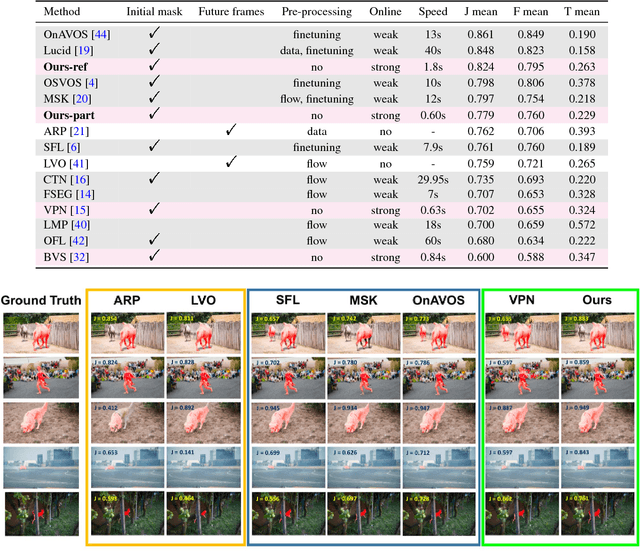
Online video object segmentation is a challenging task as it entails to process the image sequence timely and accurately. To segment a target object through the video, numerous CNN-based methods have been developed by heavily finetuning on the object mask in the first frame, which is time-consuming for online applications. In this paper, we propose a fast and accurate video object segmentation algorithm that can immediately start the segmentation process once receiving the images. We first utilize a part-based tracking method to deal with challenging factors such as large deformation, occlusion, and cluttered background. Based on the tracked bounding boxes of parts, we construct a region-of-interest segmentation network to generate part masks. Finally, a similarity-based scoring function is adopted to refine these object parts by comparing them to the visual information in the first frame. Our method performs favorably against state-of-the-art algorithms in accuracy on the DAVIS benchmark dataset, while achieving much faster runtime performance.
Beyond Part Models: Person Retrieval with Refined Part Pooling (and a Strong Convolutional Baseline)
Jan 09, 2018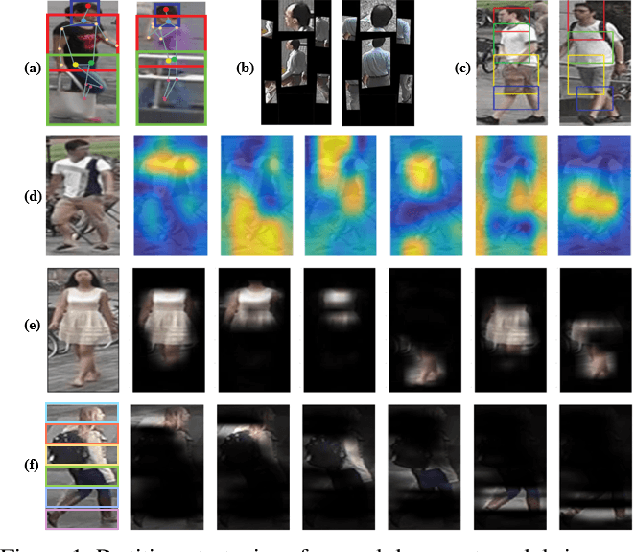
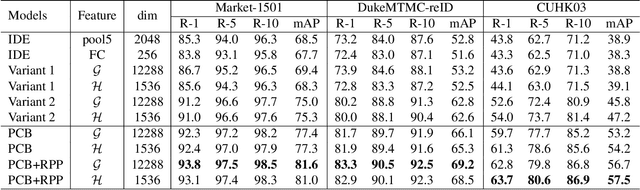
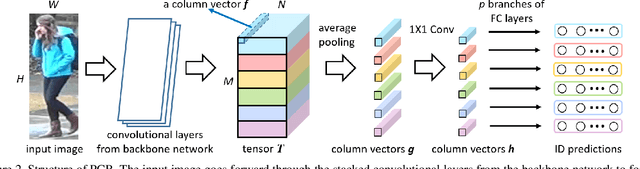
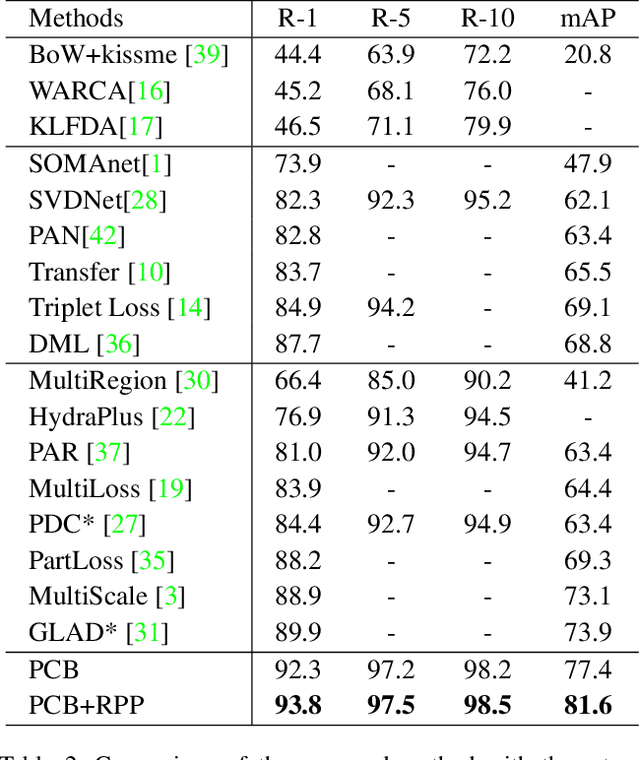
Employing part-level features for pedestrian image description offers fine-grained information and has been verified as beneficial for person retrieval in very recent literature. A prerequisite of part discovery is that each part should be well located. Instead of using external cues, e.g., pose estimation, to directly locate parts, this paper lays emphasis on the content consistency within each part. Specifically, we target at learning discriminative part-informed features for person retrieval and make two contributions. (i) A network named Part-based Convolutional Baseline (PCB). Given an image input, it outputs a convolutional descriptor consisting of several part-level features. With a uniform partition strategy, PCB achieves competitive results with the state-of-the-art methods, proving itself as a strong convolutional baseline for person retrieval. (ii) A refined part pooling (RPP) method. Uniform partition inevitably incurs outliers in each part, which are in fact more similar to other parts. RPP re-assigns these outliers to the parts they are closest to, resulting in refined parts with enhanced within-part consistency. Experiment confirms that RPP allows PCB to gain another round of performance boost. For instance, on the Market-1501 dataset, we achieve (77.4+4.2)% mAP and (92.3+1.5)% rank-1 accuracy, surpassing the state of the art by a large margin.
DeepDeblur: Fast one-step blurry face images restoration
Nov 27, 2017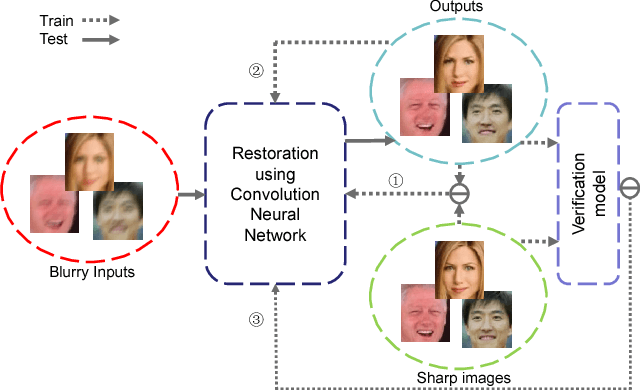


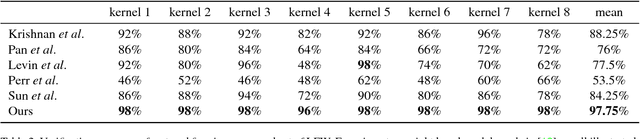
We propose a very fast and effective one-step restoring method for blurry face images. In the last decades, many blind deblurring algorithms have been proposed to restore latent sharp images. However, these algorithms run slowly because of involving two steps: kernel estimation and following non-blind deconvolution or latent image estimation. Also they cannot handle face images in small size. Our proposed method restores sharp face images directly in one step using Convolutional Neural Network. Unlike previous deep learning involved methods that can only handle a single blur kernel at one time, our network is trained on totally random and numerous training sample pairs to deal with the variances due to different blur kernels in practice. A smoothness regularization as well as a facial regularization are added to keep facial identity information which is the key to face image applications. Comprehensive experiments demonstrate that our proposed method can handle various blur kenels and achieve state-of-the-art results for small size blurry face images restoration. Moreover, the proposed method shows significant improvement in face recognition accuracy along with increasing running speed by more than 100 times.
Progressive Representation Adaptation for Weakly Supervised Object Localization
Oct 12, 2017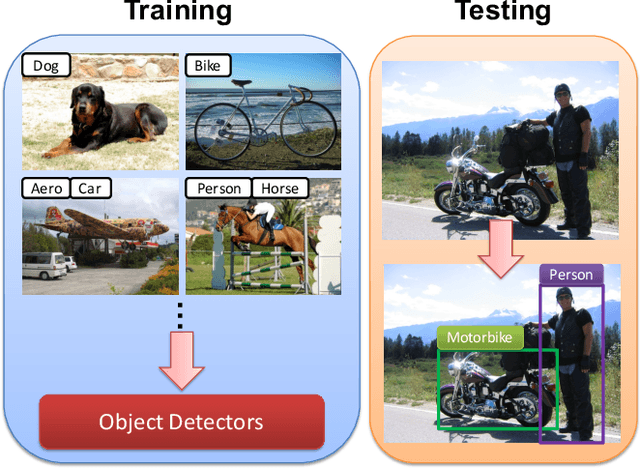
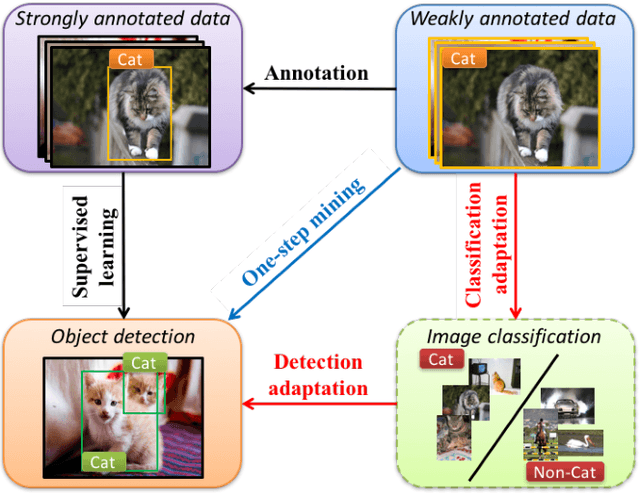
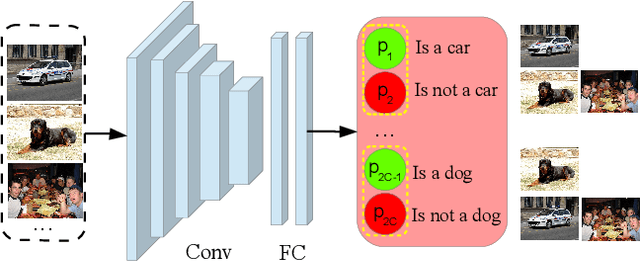
We address the problem of weakly supervised object localization where only image-level annotations are available for training object detectors. Numerous methods have been proposed to tackle this problem through mining object proposals. However, a substantial amount of noise in object proposals causes ambiguities for learning discriminative object models. Such approaches are sensitive to model initialization and often converge to undesirable local minimum solutions. In this paper, we propose to overcome these drawbacks by progressive representation adaptation with two main steps: 1) classification adaptation and 2) detection adaptation. In classification adaptation, we transfer a pre-trained network to a multi-label classification task for recognizing the presence of a certain object in an image. Through the classification adaptation step, the network learns discriminative representations that are specific to object categories of interest. In detection adaptation, we mine class-specific object proposals by exploiting two scoring strategies based on the adapted classification network. Class-specific proposal mining helps remove substantial noise from the background clutter and potential confusion from similar objects. We further refine these proposals using multiple instance learning and segmentation cues. Using these refined object bounding boxes, we fine-tune all the layer of the classification network and obtain a fully adapted detection network. We present detailed experimental validation on the PASCAL VOC and ILSVRC datasets. Experimental results demonstrate that our progressive representation adaptation algorithm performs favorably against the state-of-the-art methods.