 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy-Labeled NER with Confidence Estimation
Apr 12, 2021
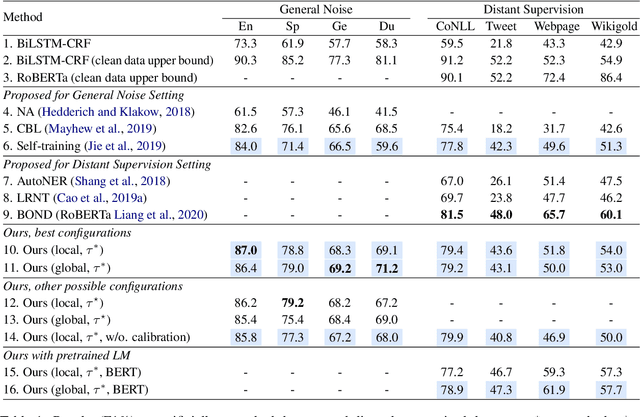
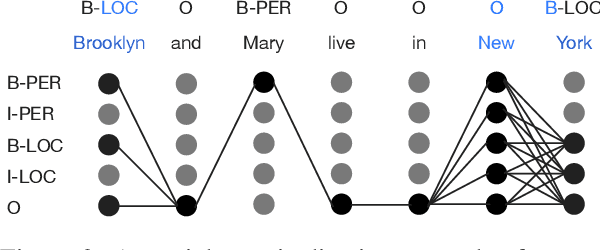
Recent studies in deep learning have shown significant progress in named entity recognition (NER). Most existing works assume clean data annotation, yet a fundamental challenge in real-world scenarios is the large amount of noise from a variety of sources (e.g., pseudo, weak, or distant annotations). This work studies NER under a noisy labeled setting with calibrated confidence estimation. Based on empirical observations of different training dynamics of noisy and clean labels, we propose strategies for estimating confidence scores based on local and global independence assumptions. We partially marginalize out labels of low confidence with a CRF model. We further propose a calibration method for confidence scores based on the structure of entity labels. We integrate our approach into a self-training framework for boosting performance. Experiments in general noisy settings with four languages and distantly labeled settings demonstrate the effectiveness of our method. Our code can be found at https://github.com/liukun95/Noisy-NER-Confidence-Estimation
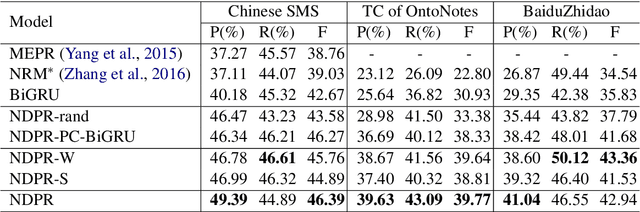
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
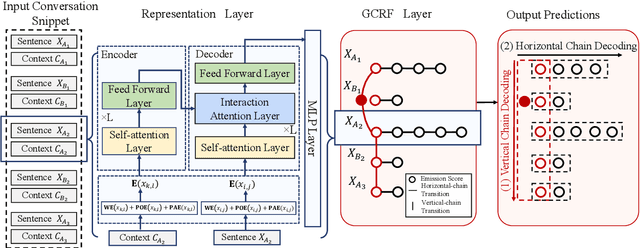
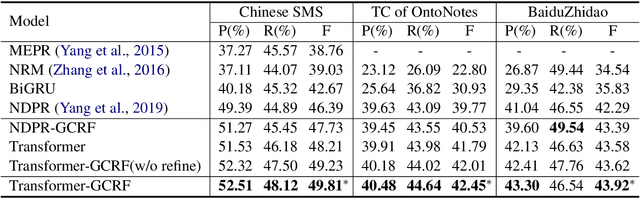
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.
Recovering Dropped Pronouns in Chinese Conversations via Modeling Their Referents
May 17, 2019
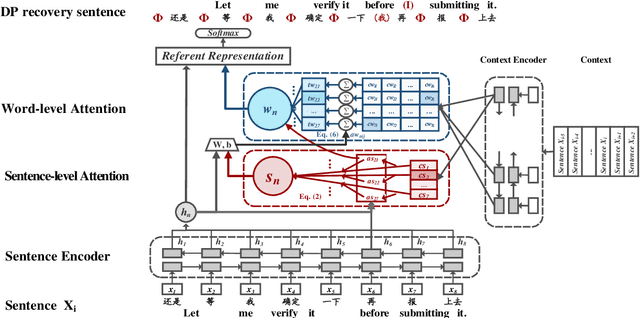
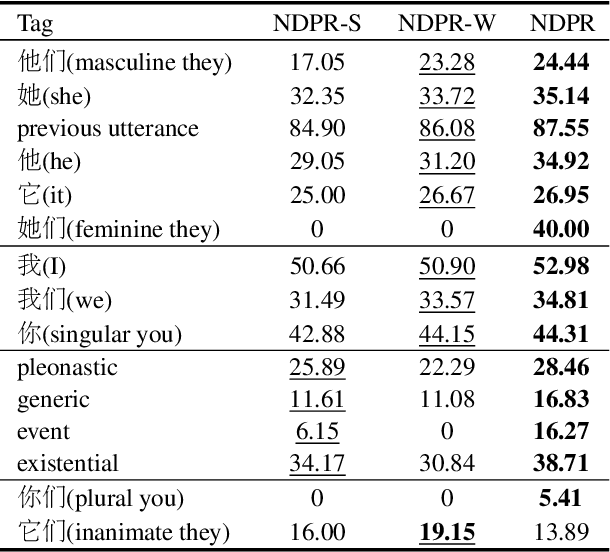
Pronouns are often dropped in Chinese sentences, and this happens more frequently in conversational genres as their referents can be easily understood from context. Recovering dropped pronouns is essential to applications such as Information Extraction where the referents of these dropped pronouns need to be resolved, or Machine Translation when Chinese is the source language. In this work, we present a novel end-to-end neural network model to recover dropped pronouns in conversational data. Our model is based on a structured attention mechanism that models the referents of dropped pronouns utilizing both sentence-level and word-level information. Results on three different conversational genres show that our approach achieves a significant improvement over the current state of the art.
Pre-training of Context-aware Item Representation for Next Basket Recommendation
Apr 14, 2019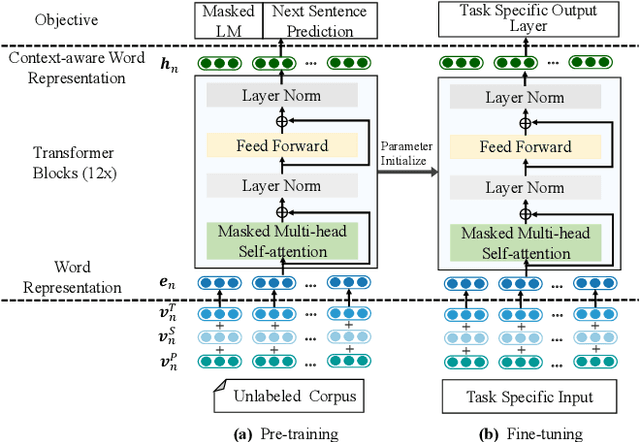
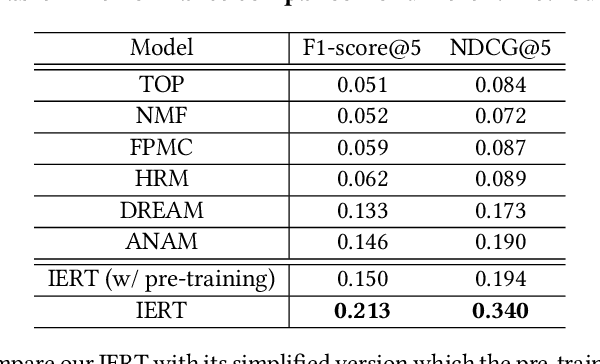
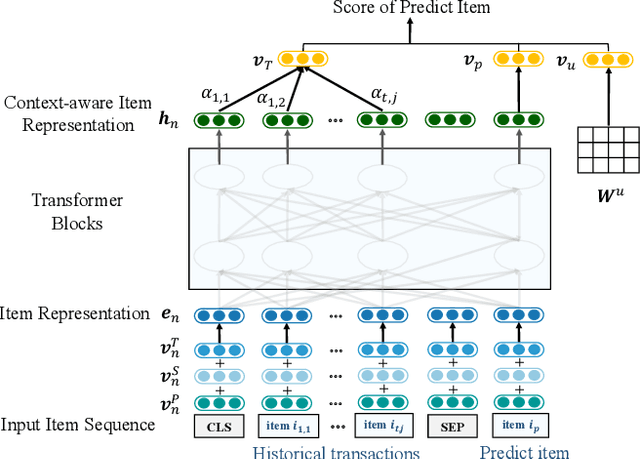
Next basket recommendation, which aims to predict the next a few items that a user most probably purchases given his historical transactions, plays a vital role in market basket analysis. From the viewpoint of item, an item could be purchased by different users together with different items, for different reasons. Therefore, an ideal recommender system should represent an item considering its transaction contexts. Existing state-of-the-art deep learning methods usually adopt the static item representations, which are invariant among all of the transactions and thus cannot achieve the full potentials of deep learning. Inspired by the pre-trained representations of BERT in natural language processing, we propose to conduct context-aware item representation for next basket recommendation, called Item Encoder Representations from Transformers (IERT). In the offline phase, IERT pre-trains deep item representations conditioning on their transaction contexts. In the online recommendation phase, the pre-trained model is further fine-tuned with an additional output layer. The output contextualized item embeddings are used to capture users' sequential behaviors and general tastes to conduct recommendation. Experimental results on the Ta-Feng data set show that IERT outperforms the state-of-the-art baseline methods, which demonstrated the effectiveness of IERT in next basket representation.
From Random to Supervised: A Novel Dropout Mechanism Integrated with Global Information
Oct 10, 2018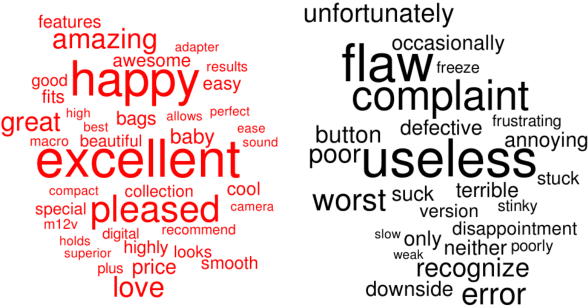
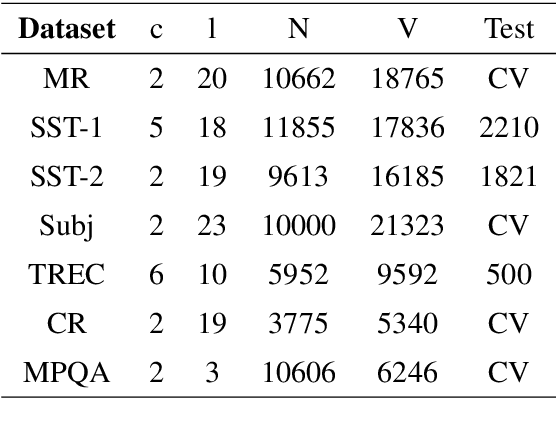
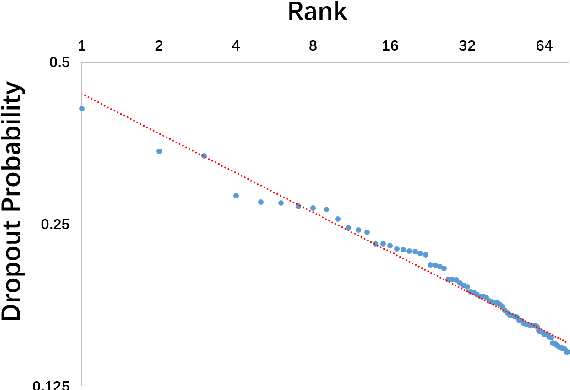
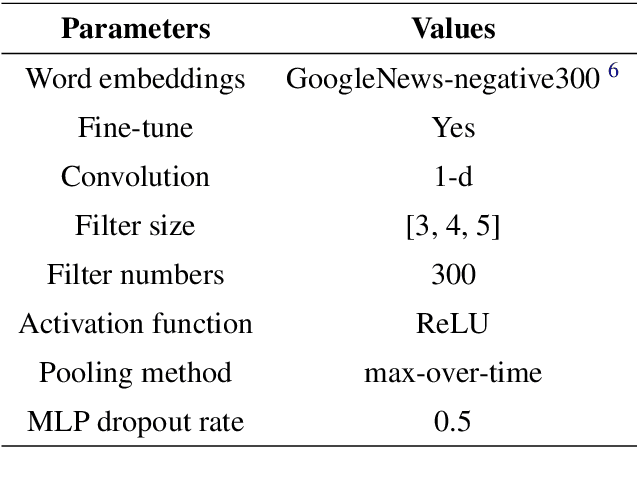
Dropout is used to avoid overfitting by randomly dropping units from the neural networks during training. Inspired by dropout, this paper presents GI-Dropout, a novel dropout method integrating with global information to improve neural networks for text classification. Unlike the traditional dropout method in which the units are dropped randomly according to the same probability, we aim to use explicit instructions based on global information of the dataset to guide the training process. With GI-Dropout, the model is supposed to pay more attention to inapparent features or patterns. Experiments demonstrate the effectiveness of the dropout with global information on seven text classification tasks, including sentiment analysis and topic classification.
A Tree Search Algorithm for Sequence Labeling
May 18, 2018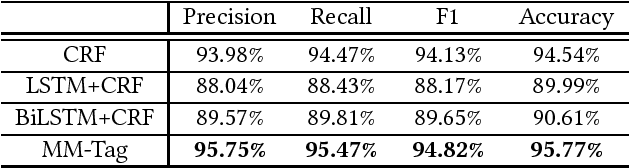
In this paper we propose a novel reinforcement learning based model for sequence tagging, referred to as MM-Tag. Inspired by the success and methodology of the AlphaGo Zero, MM-Tag formalizes the problem of sequence tagging with a Monte Carlo tree search (MCTS) enhanced Markov decision process (MDP) model, in which the time steps correspond to the positions of words in a sentence from left to right, and each action corresponds to assign a tag to a word. Two long short-term memory networks (LSTM) are used to summarize the past tag assignments and words in the sentence. Based on the outputs of LSTMs, the policy for guiding the tag assignment and the value for predicting the whole tagging accuracy of the whole sentence are produced. The policy and value are then strengthened with MCTS, which takes the produced raw policy and value as inputs, simulates and evaluates the possible tag assignments at the subsequent positions, and outputs a better search policy for assigning tags. A reinforcement learning algorithm is proposed to train the model parameters. Our work is the first to apply the MCTS enhanced MDP model to the sequence tagging task. We show that MM-Tag can accurately predict the tags thanks to the exploratory decision making mechanism introduced by MCTS. Experimental results show based on a chunking benchmark showed that MM-Tag outperformed the state-of-the-art sequence tagging baselines including CRF and CRF with LSTM.
Improving Cross-domain Recommendation through Probabilistic Cluster-level Latent Factor Model--Extended Version
Sep 24, 2014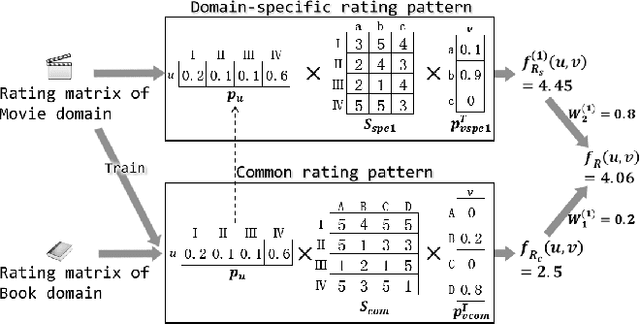
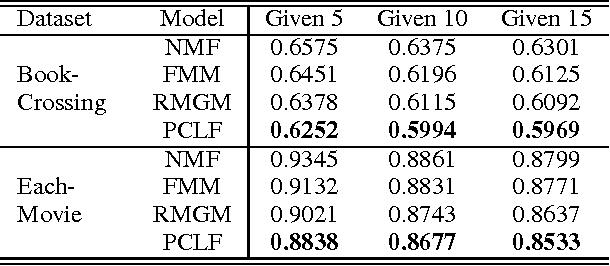
Cross-domain recommendation has been proposed to transfer user behavior pattern by pooling together the rating data from multiple domains to alleviate the sparsity problem appearing in single rating domains. However, previous models only assume that multiple domains share a latent common rating pattern based on the user-item co-clustering. To capture diversities among different domains, we propose a novel Probabilistic Cluster-level Latent Factor (PCLF) model to improve the cross-domain recommendation performance. Experiments on several real world datasets demonstrate that our proposed model outperforms the state-of-the-art methods for the cross-domain recommendation task.
Probabilistic Latent Tensor Factorization Model for Link Pattern Prediction in Multi-relational Networks
Apr 11, 2012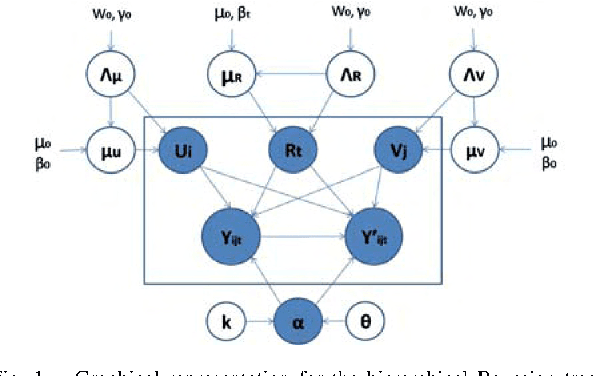
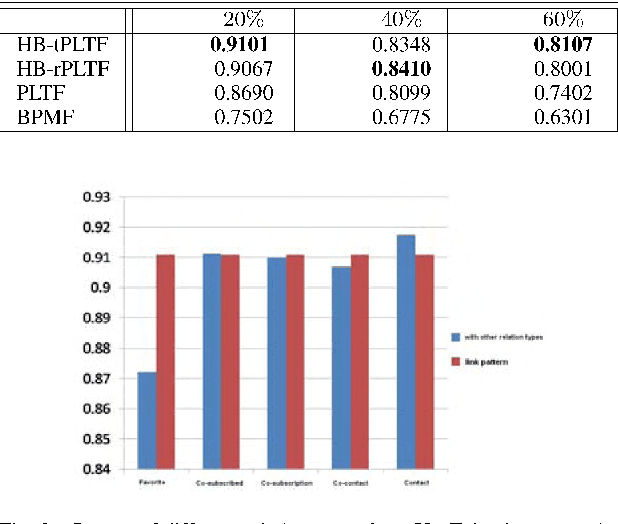
This paper aims at the problem of link pattern prediction in collections of objects connected by multiple relation types, where each type may play a distinct role. While common link analysis models are limited to single-type link prediction, we attempt here to capture the correlations among different relation types and reveal the impact of various relation types on performance quality. For that, we define the overall relations between object pairs as a \textit{link pattern} which consists in interaction pattern and connection structure in the network, and then use tensor formalization to jointly model and predict the link patterns, which we refer to as \textit{Link Pattern Prediction} (LPP) problem. To address the issue, we propose a Probabilistic Latent Tensor Factorization (PLTF) model by introducing another latent factor for multiple relation types and furnish the Hierarchical Bayesian treatment of the proposed probabilistic model to avoid overfitting for solving the LPP problem. To learn the proposed model we develop an efficient Markov Chain Monte Carlo sampling method. Extensive experiments are conducted on several real world datasets and demonstrate significant improvements over several existing state-of-the-art methods.
Modeling Relational Data via Latent Factor Blockmodel
Apr 11, 2012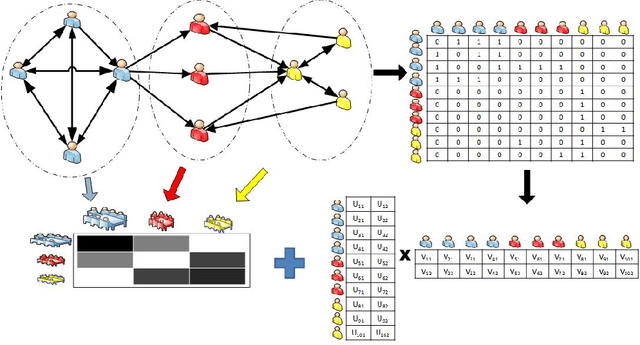

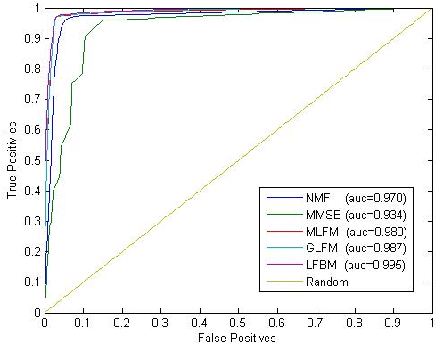
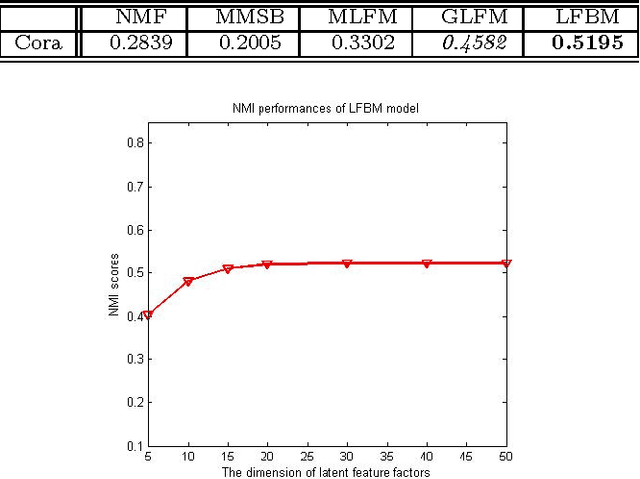
In this paper we address the problem of modeling relational data, which appear in many applications such as social network analysis, recommender systems and bioinformatics. Previous studies either consider latent feature based models but disregarding local structure in the network, or focus exclusively on capturing local structure of objects based on latent blockmodels without coupling with latent characteristics of objects. To combine the benefits of the previous work, we propose a novel model that can simultaneously incorporate the effect of latent features and covariates if any, as well as the effect of latent structure that may exist in the data. To achieve this, we model the relation graph as a function of both latent feature factors and latent cluster memberships of objects to collectively discover globally predictive intrinsic properties of objects and capture latent block structure in the network to improve prediction performance. We also develop an optimization transfer algorithm based on the generalized EM-style strategy to learn the latent factors. We prove the efficacy of our proposed model through the link prediction task and cluster analysis task, and extensive experiments on the synthetic data and several real world datasets suggest that our proposed LFBM model outperforms the other state of the art approaches in the evaluated tasks.