 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Near-Optimal Hypothesis Selection
Aug 17, 2021



Hypothesis Selection is a fundamental distribution learning problem where given a comparator-class $Q=\{q_1,\ldots, q_n\}$ of distributions, and a sampling access to an unknown target distribution $p$, the goal is to output a distribution $q$ such that $\mathsf{TV}(p,q)$ is close to $opt$, where $opt = \min_i\{\mathsf{TV}(p,q_i)\}$ and $\mathsf{TV}(\cdot, \cdot)$ denotes the total-variation distance. Despite the fact that this problem has been studied since the 19th century, its complexity in terms of basic resources, such as number of samples and approximation guarantees, remains unsettled (this is discussed, e.g., in the charming book by Devroye and Lugosi `00). This is in stark contrast with other (younger) learning settings, such as PAC learning, for which these complexities are well understood. We derive an optimal $2$-approximation learning strategy for the Hypothesis Selection problem, outputting $q$ such that $\mathsf{TV}(p,q) \leq2 \cdot opt + \eps$, with a (nearly) optimal sample complexity of~$\tilde O(\log n/\epsilon^2)$. This is the first algorithm that simultaneously achieves the best approximation factor and sample complexity: previously, Bousquet, Kane, and Moran (COLT `19) gave a learner achieving the optimal $2$-approximation, but with an exponentially worse sample complexity of $\tilde O(\sqrt{n}/\epsilon^{2.5})$, and Yatracos~(Annals of Statistics `85) gave a learner with optimal sample complexity of $O(\log n /\epsilon^2)$ but with a sub-optimal approximation factor of $3$.
A Theory of PAC Learnability of Partial Concept Classes
Jul 20, 2021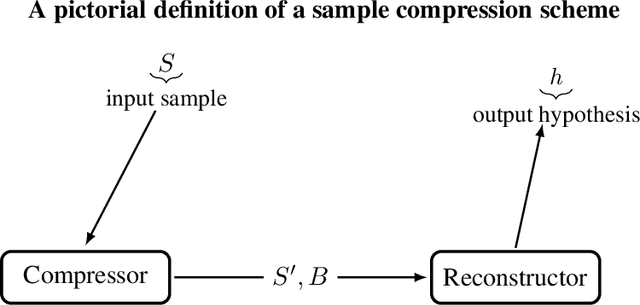
We extend the theory of PAC learning in a way which allows to model a rich variety of learning tasks where the data satisfy special properties that ease the learning process. For example, tasks where the distance of the data from the decision boundary is bounded away from zero. The basic and simple idea is to consider partial concepts: these are functions that can be undefined on certain parts of the space. When learning a partial concept, we assume that the source distribution is supported only on points where the partial concept is defined. This way, one can naturally express assumptions on the data such as lying on a lower dimensional surface or margin conditions. In contrast, it is not at all clear that such assumptions can be expressed by the traditional PAC theory. In fact we exhibit easy-to-learn partial concept classes which provably cannot be captured by the traditional PAC theory. This also resolves a question posed by Attias, Kontorovich, and Mansour 2019. We characterize PAC learnability of partial concept classes and reveal an algorithmic landscape which is fundamentally different than the classical one. For example, in the classical PAC model, learning boils down to Empirical Risk Minimization (ERM). In stark contrast, we show that the ERM principle fails in explaining learnability of partial concept classes. In fact, we demonstrate classes that are incredibly easy to learn, but such that any algorithm that learns them must use an hypothesis space with unbounded VC dimension. We also find that the sample compression conjecture fails in this setting. Thus, this theory features problems that cannot be represented nor solved in the traditional way. We view this as evidence that it might provide insights on the nature of learnability in realistic scenarios which the classical theory fails to explain.
Online Learning with Simple Predictors and a Combinatorial Characterization of Minimax in 0/1 Games
Feb 02, 2021Which classes can be learned properly in the online model? -- that is, by an algorithm that at each round uses a predictor from the concept class. While there are simple and natural cases where improper learning is necessary, it is natural to ask how complex must the improper predictors be in such cases. Can one always achieve nearly optimal mistake/regret bounds using "simple" predictors? In this work, we give a complete characterization of when this is possible, thus settling an open problem which has been studied since the pioneering works of Angluin (1987) and Littlestone (1988). More precisely, given any concept class C and any hypothesis class H, we provide nearly tight bounds (up to a log factor) on the optimal mistake bounds for online learning C using predictors from H. Our bound yields an exponential improvement over the previously best known bound by Chase and Freitag (2020). As applications, we give constructive proofs showing that (i) in the realizable setting, a near-optimal mistake bound (up to a constant factor) can be attained by a sparse majority-vote of proper predictors, and (ii) in the agnostic setting, a near-optimal regret bound (up to a log factor) can be attained by a randomized proper algorithm. A technical ingredient of our proof which may be of independent interest is a generalization of the celebrated Minimax Theorem (von Neumann, 1928) for binary zero-sum games. A simple game which fails to satisfy Minimax is "Guess the Larger Number", where each player picks a number and the larger number wins. The payoff matrix is infinite triangular. We show this is the only obstruction: if a game does not contain triangular submatrices of unbounded sizes then the Minimax Theorem holds. This generalizes von Neumann's Minimax Theorem by removing requirements of finiteness (or compactness), and captures precisely the games of interest in online learning.
Adversarial Laws of Large Numbers and Optimal Regret in Online Classification
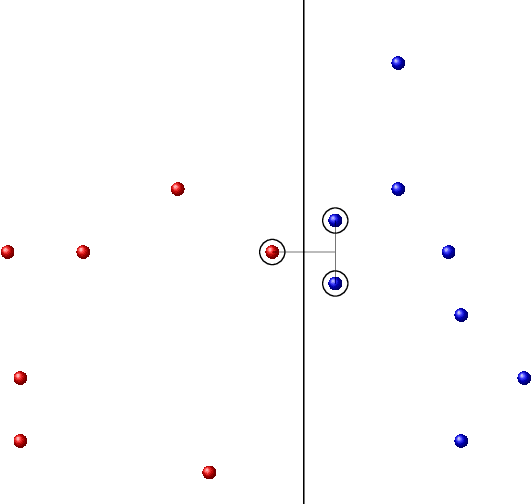
Jan 22, 2021
Laws of large numbers guarantee that given a large enough sample from some population, the measure of any fixed sub-population is well-estimated by its frequency in the sample. We study laws of large numbers in sampling processes that can affect the environment they are acting upon and interact with it. Specifically, we consider the sequential sampling model proposed by Ben-Eliezer and Yogev (2020), and characterize the classes which admit a uniform law of large numbers in this model: these are exactly the classes that are \emph{online learnable}. Our characterization may be interpreted as an online analogue to the equivalence between learnability and uniform convergence in statistical (PAC) learning. The sample-complexity bounds we obtain are tight for many parameter regimes, and as an application, we determine the optimal regret bounds in online learning, stated in terms of \emph{Littlestone's dimension}, thus resolving the main open question from Ben-David, P\'al, and Shalev-Shwartz (2009), which was also posed by Rakhlin, Sridharan, and Tewari (2015).
A Theory of Universal Learning
Nov 09, 2020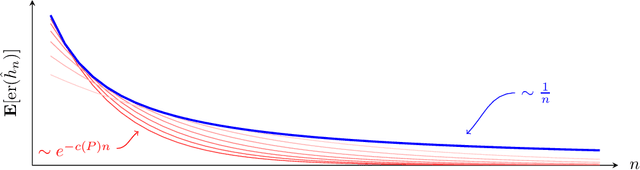
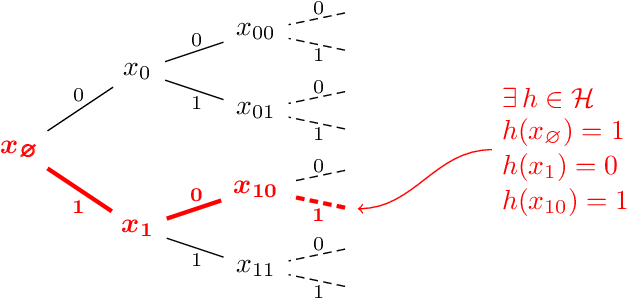
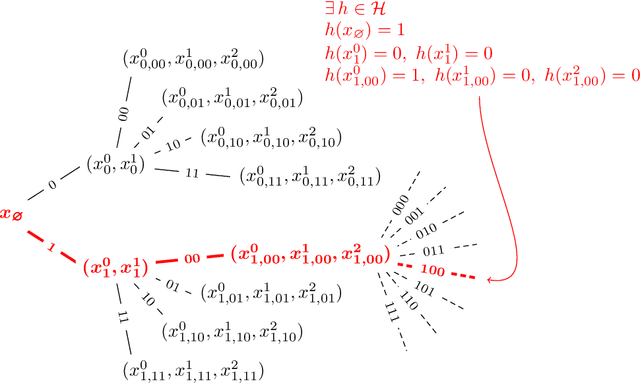
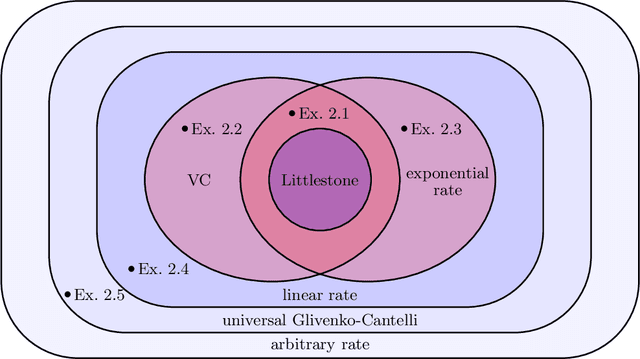
How quickly can a given class of concepts be learned from examples? It is common to measure the performance of a supervised machine learning algorithm by plotting its "learning curve", that is, the decay of the error rate as a function of the number of training examples. However, the classical theoretical framework for understanding learnability, the PAC model of Vapnik-Chervonenkis and Valiant, does not explain the behavior of learning curves: the distribution-free PAC model of learning can only bound the upper envelope of the learning curves over all possible data distributions. This does not match the practice of machine learning, where the data source is typically fixed in any given scenario, while the learner may choose the number of training examples on the basis of factors such as computational resources and desired accuracy. In this paper, we study an alternative learning model that better captures such practical aspects of machine learning, but still gives rise to a complete theory of the learnable in the spirit of the PAC model. More precisely, we consider the problem of universal learning, which aims to understand the performance of learning algorithms on every data distribution, but without requiring uniformity over the distribution. The main result of this paper is a remarkable trichotomy: there are only three possible rates of universal learning. More precisely, we show that the learning curves of any given concept class decay either at an exponential, linear, or arbitrarily slow rates. Moreover, each of these cases is completely characterized by appropriate combinatorial parameters, and we exhibit optimal learning algorithms that achieve the best possible rate in each case. For concreteness, we consider in this paper only the realizable case, though analogous results are expected to extend to more general learning scenarios.
On the Information Complexity of Proper Learners for VC Classes in the Realizable Case
Nov 05, 2020We provide a negative resolution to a conjecture of Steinke and Zakynthinou (2020a), by showing that their bound on the conditional mutual information (CMI) of proper learners of Vapnik--Chervonenkis (VC) classes cannot be improved from $d \log n +2$ to $O(d)$, where $n$ is the number of i.i.d. training examples. In fact, we exhibit VC classes for which the CMI of any proper learner cannot be bounded by any real-valued function of the VC dimension only.
Learning from Mixtures of Private and Public Populations
Aug 01, 2020We initiate the study of a new model of supervised learning under privacy constraints. Imagine a medical study where a dataset is sampled from a population of both healthy and unhealthy individuals. Suppose healthy individuals have no privacy concerns (in such case, we call their data "public") while the unhealthy individuals desire stringent privacy protection for their data. In this example, the population (data distribution) is a mixture of private (unhealthy) and public (healthy) sub-populations that could be very different. Inspired by the above example, we consider a model in which the population $\mathcal{D}$ is a mixture of two sub-populations: a private sub-population $\mathcal{D}_{\sf priv}$ of private and sensitive data, and a public sub-population $\mathcal{D}_{\sf pub}$ of data with no privacy concerns. Each example drawn from $\mathcal{D}$ is assumed to contain a privacy-status bit that indicates whether the example is private or public. The goal is to design a learning algorithm that satisfies differential privacy only with respect to the private examples. Prior works in this context assumed a homogeneous population where private and public data arise from the same distribution, and in particular designed solutions which exploit this assumption. We demonstrate how to circumvent this assumption by considering, as a case study, the problem of learning linear classifiers in $\mathbb{R}^d$. We show that in the case where the privacy status is correlated with the target label (as in the above example), linear classifiers in $\mathbb{R}^d$ can be learned, in the agnostic as well as the realizable setting, with sample complexity which is comparable to that of the classical (non-private) PAC-learning. It is known that this task is impossible if all the data is considered private.
A Limitation of the PAC-Bayes Framework
Jun 24, 2020PAC-Bayes is a useful framework for deriving generalization bounds which was introduced by McAllester ('98). This framework has the flexibility of deriving distribution- and algorithm-dependent bounds, which are often tighter than VC-related uniform convergence bounds. In this manuscript we present a limitation for the PAC-Bayes framework. We demonstrate an easy learning task that is not amenable to a PAC-Bayes analysis. Specifically, we consider the task of linear classification in 1D; it is well-known that this task is learnable using just $O(\log(1/\delta)/\epsilon)$ examples. On the other hand, we show that this fact can not be proved using a PAC-Bayes analysis: for any algorithm that learns 1-dimensional linear classifiers there exists a (realizable) distribution for which the PAC-Bayes bound is arbitrarily large.
Proper Learning, Helly Number, and an Optimal SVM Bound
May 24, 2020
The classical PAC sample complexity bounds are stated for any Empirical Risk Minimizer (ERM) and contain an extra logarithmic factor $\log(1/{\epsilon})$ which is known to be necessary for ERM in general. It has been recently shown by Hanneke (2016) that the optimal sample complexity of PAC learning for any VC class C is achieved by a particular improper learning algorithm, which outputs a specific majority-vote of hypotheses in C. This leaves the question of when this bound can be achieved by proper learning algorithms, which are restricted to always output a hypothesis from C. In this paper we aim to characterize the classes for which the optimal sample complexity can be achieved by a proper learning algorithm. We identify that these classes can be characterized by the dual Helly number, which is a combinatorial parameter that arises in discrete geometry and abstract convexity. In particular, under general conditions on C, we show that the dual Helly number is bounded if and only if there is a proper learner that obtains the optimal joint dependence on $\epsilon$ and $\delta$. As further implications of our techniques we resolve a long-standing open problem posed by Vapnik and Chervonenkis (1974) on the performance of the Support Vector Machine by proving that the sample complexity of SVM in the realizable case is $\Theta((n/{\epsilon})+(1/{\epsilon})\log(1/{\delta}))$, where $n$ is the dimension. This gives the first optimal PAC bound for Halfspaces achieved by a proper learning algorithm, and moreover is computationally efficient.
Private Query Release Assisted by Public Data
Apr 23, 2020
We study the problem of differentially private query release assisted by access to public data. In this problem, the goal is to answer a large class $\mathcal{H}$ of statistical queries with error no more than $\alpha$ using a combination of public and private samples. The algorithm is required to satisfy differential privacy only with respect to the private samples. We study the limits of this task in terms of the private and public sample complexities. First, we show that we can solve the problem for any query class $\mathcal{H}$ of finite VC-dimension using only $d/\alpha$ public samples and $\sqrt{p}d^{3/2}/\alpha^2$ private samples, where $d$ and $p$ are the VC-dimension and dual VC-dimension of $\mathcal{H}$, respectively. In comparison, with only private samples, this problem cannot be solved even for simple query classes with VC-dimension one, and without any private samples, a larger public sample of size $d/\alpha^2$ is needed. Next, we give sample complexity lower bounds that exhibit tight dependence on $p$ and $\alpha$. For the class of decision stumps, we give a lower bound of $\sqrt{p}/\alpha$ on the private sample complexity whenever the public sample size is less than $1/\alpha^2$. Given our upper bounds, this shows that the dependence on $\sqrt{p}$ is necessary in the private sample complexity. We also give a lower bound of $1/\alpha$ on the public sample complexity for a broad family of query classes, which by our upper bound, is tight in $\alpha$.