 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiTwin: Scaling Data-Generation-Ready Digital Object Dataset to 100K
Mar 17, 2026Learning in simulation provides a useful foundation for scaling robotic manipulation capabilities. However, this paradigm often suffers from a lack of data-generation-ready digital assets, in both scale and diversity. In this work, we present ManiTwin, an automated and efficient pipeline for generating data-generation-ready digital object twins. Our pipeline transforms a single image into simulation-ready and semantically annotated 3D asset, enabling large-scale robotic manipulation data generation. Using this pipeline, we construct ManiTwin-100K, a dataset containing 100K high-quality annotated 3D assets. Each asset is equipped with physical properties, language descriptions, functional annotations, and verified manipulation proposals. Experiments demonstrate that ManiTwin provides an efficient asset synthesis and annotation workflow, and that ManiTwin-100K offers high-quality and diverse assets for manipulation data generation, random scene synthesis, and VQA data generation, establishing a strong foundation for scalable simulation data synthesis and policy learning. Our webpage is available at https://manitwin.github.io/.
World-Coordinate Human Motion Retargeting via SAM 3D Body
Dec 25, 2025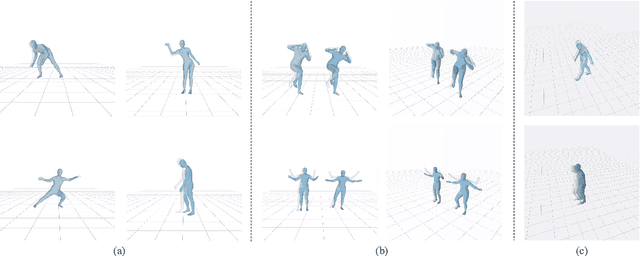
Recovering world-coordinate human motion from monocular videos with humanoid robot retargeting is significant for embodied intelligence and robotics. To avoid complex SLAM pipelines or heavy temporal models, we propose a lightweight, engineering-oriented framework that leverages SAM 3D Body (3DB) as a frozen perception backbone and uses the Momentum HumanRig (MHR) representation as a robot-friendly intermediate. Our method (i) locks the identity and skeleton-scale parameters of per tracked subject to enforce temporally consistent bone lengths, (ii) smooths per-frame predictions via efficient sliding-window optimization in the low-dimensional MHR latent space, and (iii) recovers physically plausible global root trajectories with a differentiable soft foot-ground contact model and contact-aware global optimization. Finally, we retarget the reconstructed motion to the Unitree G1 humanoid using a kinematics-aware two-stage inverse kinematics pipeline. Results on real monocular videos show that our method has stable world trajectories and reliable robot retargeting, indicating that structured human representations with lightweight physical constraints can yield robot-ready motion from monocular input.