 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiTwin: Scaling Data-Generation-Ready Digital Object Dataset to 100K
Mar 17, 2026Learning in simulation provides a useful foundation for scaling robotic manipulation capabilities. However, this paradigm often suffers from a lack of data-generation-ready digital assets, in both scale and diversity. In this work, we present ManiTwin, an automated and efficient pipeline for generating data-generation-ready digital object twins. Our pipeline transforms a single image into simulation-ready and semantically annotated 3D asset, enabling large-scale robotic manipulation data generation. Using this pipeline, we construct ManiTwin-100K, a dataset containing 100K high-quality annotated 3D assets. Each asset is equipped with physical properties, language descriptions, functional annotations, and verified manipulation proposals. Experiments demonstrate that ManiTwin provides an efficient asset synthesis and annotation workflow, and that ManiTwin-100K offers high-quality and diverse assets for manipulation data generation, random scene synthesis, and VQA data generation, establishing a strong foundation for scalable simulation data synthesis and policy learning. Our webpage is available at https://manitwin.github.io/.
A Comparative Study of Algorithms for Realtime Panoramic Video Blending
Dec 24, 2016
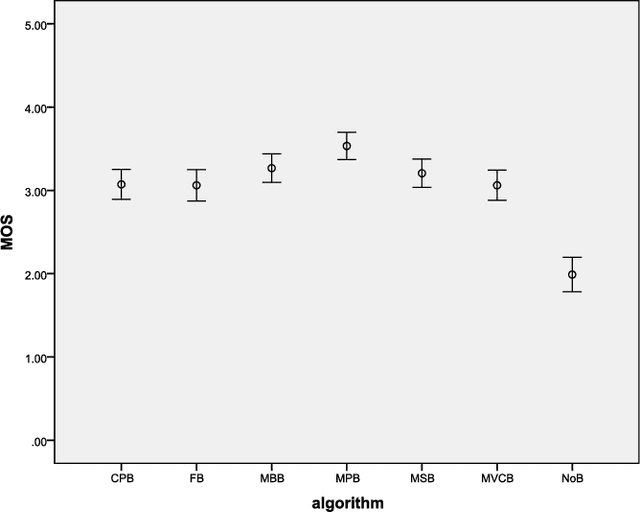


Unlike image blending algorithms, video blending algorithms have been little studied. In this paper, we investigate 6 popular blending algorithms---feather blending, multi-band blending, modified Poisson blending, mean value coordinate blending, multi-spline blending and convolution pyramid blending. We consider in particular realtime panoramic video blending, a key problem in various virtual reality tasks. To evaluate the performance of the 6 algorithms on this problem, we have created a video benchmark of several videos captured under various conditions. We analyze the time and memory needed by the above 6 algorithms, for both CPU and GPU implementations (where readily parallelizable). The visual quality provided by these algorithms is also evaluated both objectively and subjectively. The video benchmark and algorithm implementations are publicly available.